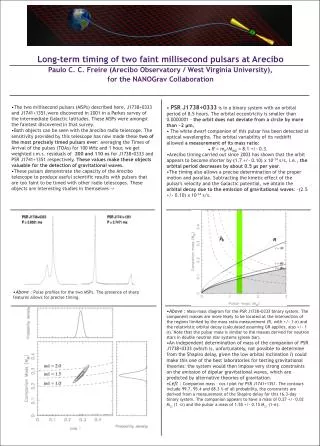
Download

1 / 7
80 likes | 156 Views
Text segmentation in Informedia. The Problem. Use closed-captioning cues to segment the text stream into coherent regions (stories). Training data is provided by news provider with paragraph separators (>>>) denoting the boundary between stories.

E N D
The Problem • Use closed-captioning cues to segment the text stream into coherent regions (stories). • Training data is provided by news provider with paragraph separators (>>>) denoting the boundary between stories. • Need to find the learning algorithm and features for text segmentation. 000076 ANDRIA: FROM CNN IN ATLANTA, 000079 SEEN LIVE AROUND THE WORLD, THIS 000081 IS "WORLDVIEW." I'M ANDRIA 000082 HALL. >>> THE SEARCH FOR 000084 SURVIVORS CONTINUES IN SOUTHEASTERN 000087 MEXICO, WHERE THE DEATH TOLL IS 000088 RISING BY THE HOUR. IT'S NOW 000089 CLOSE TO 300. RESCUERS ARE 000091 DIGGING THROUGH A SEA OF MUD, 000093 SEARCHING FOR HUNDREDS WHO ARE 000094 MISSING. THE U.S. STATE DEPARTMENT, 000096 WARNING TRAVELERS TO USE 000099 EXTREME CAUTION IN THE REGION.
Plan of Attack • Use features (if any and not too many) in adjacent sentences around the separator. • SVM / ANN. • Text segmentation by topic. • Text categorization (into topics) using KNN. • Build naïve Bayse classifier for each topic. • Locate coarse boundary by detecting topic shift. • Locate accurate boundary using local features.
Difficulties: we need your idea! • Raw Data • limited size (1700+) • Clustering: • too many features • number of topics • Topic Transition • multiple topics per story / similar topics • Local Feature • It works or not? • Result • How to measure it with noisy training data?
Data and Methods • Data • CNN WorldView (01/1999-10/2000) • Stemming, merging, stop words removal, … • Methods • Classification • Artificial Neural Network (sentence) • Naive Bayes (sentence/fixed length window) • SVM (sentence) • Topic change detection • EM clustering • # topics, block size 001630 CENTURY >>> WE PEOPLE TEND TO 001631 PUT THINGS LIKE THE PASSING OF A 001633 MILLENIUM IN SHARP FOCUS. WE 001633 CELEBRATE, CONTEMPLATE, EVEN 001635 WORRY A BIT, SOMETIMES WORRY A 001636 LOT. AFTER ALL, IT'S SOMETHING 001638 THAT HAPPENS ONLY ONCE EVERY ONE 001641 THOUSAND YEARS. A BIG DEAL? 001641 PERHAPS NOT TO ALL LIVING THINGS, 001642 AS CNN'S RICHARD BLYSTONE 001643 FOUND OUT WHEN HE CONSIDERED ONE 001654 VERY OLD TREE. >>> HO HUM. 001654 ANOTHER MILLENNIUM. THE GREAT YEW
Experimental Result • Feature selection • Block size • Best Classifier: • Naive Bayes Classifier • Fixed length block Identified boundary Sentences Reference boundary False Alarm OK Miss OK OK OK
Discussion • Impact of data set • Good recall, lower precision • Noisy: close-captioning text • Ratio of positive to negative examples • Combining different classifiers • Different granularity • Voting