Download
1 / 12
120 likes | 270 Views
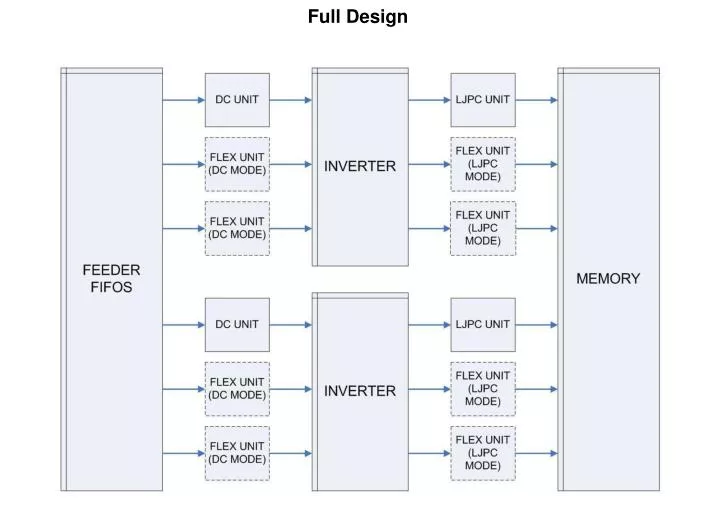
Full Design. The main idea behind this design was to create an architecture capable of performing run-time load balancing in order to more efficiently work with N-body type problems. The design consists of the following units: Feeder FIFO DC Units LJPC Units FLEX Units Inverter Units

E N D
The main idea behind this design was to create an architecture capable of performing run-time load balancing in order to more efficiently work with N-body type problems. The design consists of the following units: Feeder FIFO DC Units LJPC Units FLEX Units Inverter Units Main Controller All of these units will be discussed in this presentation. The primary units responsible for the implementation of the load balancing are the FLEX units, which are managed by the main controller. The FLEX units are special purpose processing elements that are capable of performing either the DC or the LJPC computations. This allows them to be used in whichever mode is currently in the most need of assistance. The main controller works with the Feeder FIFO and the Inverter Units in order to properly determine the most efficient use of the FLEX processors. This is done by monitoring FIFO capacities which provide the controller with an understanding of the congestion of the current area. Since LJPC calculations are only performed on atoms within a specified radius, if the majority of atoms lie outside this area, then most of the computation time will be spent on DC calculations and the Inverter’s FIFO capacity will be small, and vice versa. DESIGN CONCEPTS
DC UNIT DESIGN • This unit is responsible for computing the distance squared between two atoms. • X1, Y1, and Z1 represent the 3-dimensional coordinate vector for the source atom. X2, Y2, and Z2 represent the 3-dimensional coordinate vector for all other atoms. This value is changed every clock cycle, whereas the source atom remains constant. • Once the distance squared has been calculated, it is compared with a cut-off radius (CR). If the radius is within tolerance, the data is sent through to the inverter. Otherwise, it is discarded. • Represented in hardware by a 1-to-1 mapping, allowing for maximum throughput. Since not all atoms will be within tolerance, it is important to perform as many distance calculations as possible in as short of a time as possible in order to improve the efficiency of the LJPC units.
LJPC UNIT DESIGN • This unit is responsible for performing a portion of the Lenard-Jones Potential Calculation. • 1/R2 represents the inverted radius squared that is received from the inverter. • DX, DY, and DZ are the results of the initial subtraction in the DC Unit and are passed along with the radius squared. • FX, FY, and FZ represent the accumulated 3-dimensional force vector. POTENTIAL ENERGY represents the accumulated potential energy. • The hardware design is not a 1-to-1 mapping as was done with the DC Unit. Instead, the design is broken into two portions, each containing three operational step each, plus a separate accumulation step. This allows the unit to receive new data after completion of only three operational steps rather than all seven. • Data may be received into this unit for up to six clock cycles at a time. If the two corresponding FLEX units are also in LJPC mode, then they are feed while this unit completes its first 3-step cycle. This allows for a minimum amount of delay in receiving data from the inverter.
FEEDER FIFO • This unit is responsible for fetching data from the onboard block ram modules and appropriately feeding this data to each of the units, including FLEX units if they are operating in DC mode. • Load balancing is also achieved within this unit. All six block ram modules send their data into the controller where the controller may then determine which unit to send the data to. Since the DC units will always empty their data units first, they may then be used to assist in emptying any remaining units. If a FLEX unit has spent a large portion of its time in LJPC mode, a large amount of data may be left in its block ram module. This data may then be feed to either of the DC units, thus allowing both sides to balance out. • The determination of which block ram will be taken over by a DC unit is made by the main controller and is based upon the amount of data remaining in each unit. Whichever unit is currently fullest would be the best candidate. Therefore, if one side has produced more atoms within the radius tolerance, then the two DC units may end up working on both available block rams on one side, although data may be available on both sides.
INVERTER • This unit is responsible for retrieving data from the DC units and FLEX units working in DC mode, inverting the radius received, and then sending that data on to all available LJPC units and FLEX units operating in LJPC mode. • The controller uses a polling routine to check each of the three FIFOs, each 1K in size, to determine if data is available. This is done on a priority basis, with the DC unit having highest priority. Once valid data has been received by any of the 3 units, it is taken in and sent to the inverter. • Once the radius has been inverted, this data is then sent to the LJPC FIFO. Data is accumulated here until it reaches a specified level, which is currently set at 128 out of 1K. Since the LJPC unit can not accept data at all times, if the level reaches above this point, it is transferred to the next FLEX FIFO. The level of each FLEX FIFO is read every clock cycle to determine if the corresponding FLEX unit should switch modes from DC to LJPC. The unit will not switch back until the FIFO has reached another specified level. Currently, the FLEX will switch from DC to LJPC when the level is greater than 128, but will not switch back until the level is below 32.
FLEX • Flexible unit that can operate in either DC or LJPC mode • Using Force-Directed scheduling, the architecture shown was derived • Pure data flow architecture – no conditional branching necessary • No register files • Instructions control MUX select lines and adder/subtractor modes • Delays of 1, 2, 5, 6, 9, 10, 11, and 35 clock cycles are implemented where needed • There is a one-to-one relationship between arithmetic units in the DC module and in the FLEX module, allowing for identical behavior • In LJPC mode, the FLEX processor must reuse resources, causing it to cycle through periods of accepting inputs and of processing those inputs
FLEX The FLEX instruction word takes care of • Control of the MUXes that feed data to the arithmetic units at each clock cycle • Control of the mode of each adder/subtractor at each clock cycle • 4 control signals • FW_WE allows data to be written to the force accumulation registers • PE_WE allows data to be written to the potential energy accumulation register • JUMP causes the program counter to be reset to 0 • BUSY indicates the program is busy in LJPC mode and cannot be switched to DC mode
Preliminary results show a roughly linear • relationship between: • Atoms processed and time taken • Percentage of atoms within the cutoff radius and time taken • An inverse relationship occurs between time taken and the FIFO threshold
Average data levels on both input and output FIFOs follow an exponential curve with respect to the percentage atoms within the cutoff radius.
FUTURE WORK • System Performance can be enhanced through several optimizations, including • Redesigning the FIFOs to pipe data to all LJPC and applicable FLEX units more efficiently • Improving the logic used by the controller to determine the mode of each FLEX unit • Porting the controller logic to software for use on a PowerPC (There are 2 PowerPC cores available on our Xilinx Virtex 4 FPGA) • Modifying the FLEX processor architecture to ensure an optimal number of computational units and to ensure optimal usage of these units