Download

1 / 39
390 likes | 473 Views
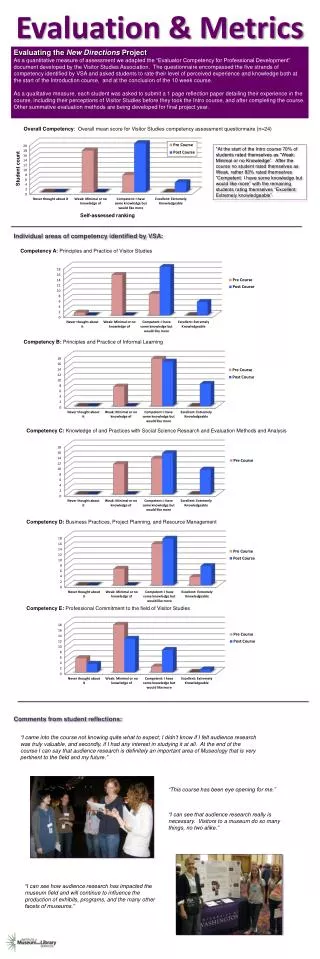
Test Collections and Associated Evaluation Metrics based on Graded Relevance. Kal Jarvelin kalervo.jarvelin@uta.fi. Introduction. Real-life vs. Cranfield paradigm in IR evaluation Cranfield, with TREC as an example: binary relevance with bias

E N D
Test Collections and Associated Evaluation Metrics based on Graded Relevance Kal Jarvelin kalervo.jarvelin@uta.fi
Introduction • Real-life vs. Cranfield paradigm in IR evaluation • Cranfield, with TREC as an example: • binary relevance with bias • very liberal relevance criterion, system-oriented evaluation • document overlaps not considered • Real-life: • document floods • all documents are not created equal • often strict relevance criteria, little scanning, sessions • document overlaps do matter, bias strong but variable • Evaluate by graded/high relevance? Why? How?
Outline • Introduction • Relevance • degree, types, and dimensions of relevance • topical graded relevance defined for test collections • Building a Test Collection with Graded Relevance • The TREC-UTA Experience • A Glance at Evaluation Metrics based on Graded Relevance • binarization; gMAP; (s)(n)(D)CG • Does it Matter? • Kinds of results graded relevance may offer • Discussion
Relevance • A difficult concept - Saracevic (1975) proposed a generator for relevance concepts: • Relevance is <any of measurement instruments>, which measures <any aspect of relevance>, which exists between <any object to be assessed> and <any scope of assessment> as seen by <any assessor>. • For example, relevance is the quantity, which measures the match, which exists between a text and an information need as seen by the inquirer.
Relevance • Relevance is multi-graded (Cuadra & Katter 1967; Rees & Schultz 1967) • grades can be measured (Tang & al. 1999) • Relevance is amultidimensional cognitive concept • it depends on searchers’ perceptions of information and of their situations • Relevance is complex (Schamber & al. 1990) • main categories: objective, subjective • Relevance is dynamic • assessments of objects may change over time
Relevance • Types of relevance (Saracevic 1996; Cosijn & Ingwersen 2000) • algorithmic relevance • topical relevance • pertinence • situational relevance • socio-cognitive relevance • Graded relevance in test collections: topical? • Why?
Outline • Introduction • Relevance • Building a Test Collection with Graded Relevance • The TREC-UTA Experience • A Glance at Evaluation Metrics based on Graded Relevance • binarization; gMAP; (s)(n)(D)CG • Does it Matter? • Kinds of results graded relevance may offer • Discussion
Building Test Collections with Graded Relevance: The UTA-TREC Experience • Goal • to create a sub-collection of TREC-7 and TREC-8 where the capability of IR systems to focus on highly relevant documents could be studied • 38 topics from were reassessed with a 4-point scale • a subset of TREC topics 351-450 • # TREC relevant documents required > 30 per topic • cost consideration: the number of relevant docs with a 5% sample of non-relevant docs not to exceed 200 • cultural match requirements: general topics rather than American (Sormunen @ SIGIR 2002)
Building Test Collections: Sample Relevance Grades (0) The doc does not contain information on topic (1) The doc only points to the topic - no more information than in the topic (marginal) • Typical extent: one sentence or fact (2) The doc is topical by not exhaustive (fair) • Typically: one paragraph, 2-3 sentences or facts (3) The doc is exhaustive on the topic (highly rel) • Typically : several paragraphs, 4+ sentences or facts
Building Graded Test Collections: Process • Assessors: paid students, 3 + 3 • Training • guidelines, intro, two training topics • Materials: printed, long ones on screen • Process • initial scanning to establish stable criteria • notes on interpretations, conflicts • partially parallel assessments (quality control) • rough marking of relevant passages • Comparison to original: divergence analysis
Building Graded Test Collections: Results Reassessments: Level of TREC relevant TREC non-relevant relevance # % # % Rel=3 353 13 % 11 0 % Rel=2 724 26 % 40 1 % Rel=1 1004 36 % 134 5 % Rel=0 691 25 % 2780 94 % Total 2772 100 % 2965 100 %
Building Graded Test Collections: Results Levels of Total graded UTA relevant relevance # % #/topic # % Rel=3 364 6 % 10 364 16 % Rel=2 764 13 % 20 764 34 % Rel=1 1138 20 % 30 1138 50 % Rel=0 3471 61 % 91 Total 5737 100 % 151 2266 100 % Thus among the TREC-relevant, one half were marginal, one third fair, and one sixth highly relevant
Building Graded Test Collections: Economics • Judging liberal relevance is fast • In graded assessment, extra work is required to specify the degree of relevance • The total time to assess slightly 7000+ documents was ~78 weeks, i.e. ~20 PM • note that about one half relevant in this secondary analysis (slows the process) • experience improved judgment speed
Outline • Introduction • Relevance • Building a Test Collection with GR • Evaluation Metrics based on Graded Relevance • binarization; gMAP; (s)(n)(D)CG • Does it Matter? • Kinds of results graded relevance may offer • Discussion
Evaluation Metrics: Binarization • The recall base is binarized by dividing it into relevant / non-relevant in different ways by relevance scores • Which documents are relevant enough? • Supports IR evaluation by traditional metrics • recall-precision curves; MAP; P@10 • Kekalainen & Jarvelin (JASIST 2002)
Binarization Example: Structured QE P-R curves of SUM, BOOL, and SSYN-C queries at relevance threshold 0/1-3 P-R curves of SUM, BOOL, and SSYN-C queries at relevance threshold 0-2/3
Evaluation Metrics: Generalized Metrics • Graded assessments are incorporated into traditional metrics through generalization: • generalized precision: gP = dR r(d) / |R| • generalized recall: gR = dR r(d) / dD r(d) • R is a set |R| retrieved documents, and D = {d1, d2, … , dN} a database, R D. The docs di in the database have relevance scores 0.0 <= r(di) <= 1.0 • similarly, generalized MAP, gMAP • weighting of relevance scores possible • see Kekalainen & Jarvelin (JASIST 2002)
Generalization Example: Structured QE P-R curves of SUM, BOOL, and SSYN-C queries at relevance threshold 0/1-3 Generalized P-R curves of SUM, BOOL, and SSYN-C queries (0-1-4-10)
Evaluation Metrics: (n)(S)(D)CG Family • (n)(D)CG - normalized discounted cumulated gain • document value is discounted by the log of its rank - late-found documents are less valuable than their nominal value • normalization of performance by dividing by ideal performance • sDCG - session-based discounted cumulated gain • documents found by later queries are further discounted by a query-dependent factor • normalization possible
Discounted Cumulated Gain • Cumulate gain and divide it by the log of the rank of each document where • j is the rank of each document • G[j] is the gain of document at rank j • b is the logarithm base for the query discount • The normalized version through division by the ideal gain • nDCG[i] = DCG[i] / ICG[i]
TREC-UTA ad hoc TDN (41 topics) nDCG & DCG, weighting 0-1-5-10, discount log=10 vs. 1.5 log=10 log=1.5
Evaluation Metrics: Session DCG, sDCG • … as above, but further discount gain by the log of its query rank q ( 1 … m) sDCG(q) = DCG/(1 + bqlog q) • where bqR is the logarithm base for the query discount; 1 < bq < 1000 • q is the position of the query. • Can be normalized • Average these over a set of queries • Jarvelin & al. (ECIR 2008).
nsDCG, Top-10, Systems A – B, all sessions (b=2; bq=4; 0-1-10-100)
Outline • Introduction • Relevance • Building a Test Collection with GR • A Glance at Evaluation Metrics based on GR • Does it Matter? • Kinds of results graded relevance may offer • Discussion
Does It Matter? – User View • Recognition of relevance by degree of relevance • Vakkari & Sormunen (JASIST 2004) • Searchers seem more likely and consistent to identify highly relevant documents than marginal ones • They are likely to err on marginal documents, i.e. find these non-relevant • Should such docs then be used for evaluation?
Does It Matter? Systems Ranking • Ranking systems by graded relevance performance • Kekalainen (IP&M 2005) compared the rankings of IR systems based on binary and graded relevance (n, m, f, h); TREC 7 and 8 data • 21 topics and 90 systems from TREC 7 • 20 topics and 121 systems from TREC 8 • Binary MAP, CG, DCG, and nDCG • Different weighting schemes tested • Kendalls rank correlations are computed to determine to what extent the rankings produced by different measures are similar • High correlation in the binary end, less with sharp weighting • Voorhees (Sigir 2001) has similar findings
Correlation of MAP vs. nDCG • Some of Kekalainen’s (2005) findings: • DCG variation DCV10 DCV100 • nDCG-0.1.1.1 0.934 0.852 • nDCG-0.1.2.3 0.894 0.828 • nDCG-0.1.5.10 0.859 0.805 • nDCG-0.1.10.100 0.7370.719 • Discounting and normalizing affect system ranking along with weighting when compared to MAP – some systems retrieve highly relevant documents earlier than other
Does It Matter: Relevance Feedback • Keskustalo & al (ECIR 2006; IR 2008) • RFB with relevance requirement • Evaluation by relevance weighting • Full document FB key extraction • Liberal RFB in short window effective
Effect of RFB Amount and Quality RFB with CG evaluation with scenarios baseline, <3,10,10>, <1,10,10>, weighting 0-1-10-100
Does It Matter: Relevance Feedback • Järvelin (CIKM 2009) • Simulated RFB with relevance requirement • Evaluation by relevance weighting • Feedback through sentence extraction & key weighting • Liberal RFB in short window effective
Results: Liberal RFB Effectiveness of simulated RFB runs with liberal RFB B = browsing depth F = # RFB docs E = # QE keys extracted
Does It Matter: Transitive Translation • Lehtokangas & al. (2006, 2008) • Dictionary-based CLIR, structured queries • Direct translation loses highly-relevant docs • Transitive translation loses highly-relevant docs • Both relatively better with liberal relevance • Pseudo-relevance feedback brings transitive translation to the level of direct translation
Does It Matter: Negative Weighting • Keskustalo & al (SIGIR 2008) • What if non-relevant docs are negatively weighted? • Evaluation by different weighting scenarios, including negative weights • Opportunities • Searcher’s stopping becomes understandable • Test collection analysis
DCG - Binary Relevance, Neg Weights Moderately patient user (log base 4) with traditional weighting (0/1) and with negative weighting (-1/1). Average DCG for 50 topics (TREC 8).
DCG – Weighted (Negative) Relevance Patient user (log base 10) with traditional weighting (0/0/5/10) and with negative values (-2/0/5/10). Average DCG for 41 topics (TREC 7 and 8).
Outline • Introduction • Relevance • Building a Test Collection with GR • A Glance at Evaluation Metrics based on GR • Does it Matter? • Discussion and Conclusion
Discussion • Collections with graded relevance can be created • directly or through secondary analysis • Graded relevance matters - HRDs matter • searchers recognize and value it • more real-life flavor to evaluation • affects system ranking by performance • Many ways of using graded relevance • early precision matters - discounting • weighting supports varying use scenarios • sessions with short browsing can be evaluated - important for realistic evaluation
Conclusion • Graded relevance is an opportunity in IR evaluation • brings a bit more realism to evaluation • affects relative system performance • but there is no revolution: best systems tend to be the best under various metrics employing GR • However, bear in mind the questions: • Is result quality the only thing to look at? • Is system performance alone of interest? • GR is an important opportunity if the answer is no