Download

1 / 18
190 likes | 320 Views
Lightweight Graphical Models for Selectivity Estimation without Independence Assumptions. Kostas Tzoumas Amol Deshpande Christian S. Jensen. Query Optimization. LO. cost = | LO |. Need to decide (among others) the “best” join plan. Very simplified picture:

E N D
Lightweight Graphical Models for Selectivity Estimation without Independence Assumptions Kostas Tzoumas AmolDeshpande Christian S. Jensen
Query Optimization LO cost = |LO| • Need to decide (among others) the “best” join plan. • Very simplified picture: • Cost of a plan = # of intermediate tuples it produces. • Use upper plan if |LO|<|OC|, lower plan otherwise. • Use size estimates of intermediate relations. • Cardinality estimation: Estimating relation sizes at compile time. • Typically using statistical summaries. • Errors in estimates can lead to wrong plan. Independence assumptions a frequent factor of errors. L O C cost = |OC| OC L O C
Why Correlations Matter An order’s total price is a function of the prices of the order’s items. Causes LO to have more tuples than in average. select c_name,c_address from lineitem,orders,customer where l_orderkey=o_orderkey and o_custkey=c_custkey and o_totalprice in [t1,t2] and l_extendedprice in [e1,e2] and c_acctbal in [b1,b2] lineitem orders customer eprice orderkey orderkey tprice custkey custkey acctbal
Independence Assumption select c_name,c_address from lineitem,orders,customer where l_orderkey=o_orderkey and o_custkey=c_custkey and o_totalprice in [t1,t2] and l_extendedprice in [e1,e2] and c_acctbal in [b1,b2] |L’| = Pr(epricein [e1,e2]) |L| |O’| = Pr(tpricein [t1,t2]) |O| |L’O’| = Pr(l_orderkey=o_orderkey)|L’||O’| |L’O’| = Pr(l_orderkey=o_orderkey) Pr(epricein [e1,e2]) Pr(tpricein [t1,t2]) |L||O| • Results to under-estimation of |L’O’| wrong query plan, nested loop join. • Can result in orders of magnitude slower execution. • Solution: estimate joint probabilities: |L’O’| = Pr (l_orderkey=o_orderkey, epricein [e1,e2], tpricein [t1,t2]) |L||O| NLJ L’O’ HJ L’ O’ C’ σL σΟ σC L O C
Problem Setting • Database + workload schema graph • Schema graph Set of random variables (descriptive attributes and join indicators) • Goal: Approximate P(JLO, JLP, JLS, JSC, JOC, L.sdate, L.cdate, L.rdate, O.odate, P.size, S.acctbal,C.acctbal) orders lineitem JLO ≡ L.okey=O.okey Join indicator A binary random variable Captures the “event” that two random tuples join. We don’t need “key” attributes in the model (hard to approximate). Pr(JOC=T)=sel(O.ckey=C.ckey) sdate cdate rdate odate Problem: Exponential blow-up of storage space and selectivity estimation time. JOC ≡ O.ckey=C.ckey JLP ≡ L.pkey=P.pkey JLS ≡ L.skey=S.skey customer part supplier JSC ≡ S.nkey=C.nkey size acctbal acctbal
Graphical Models • Exploit independence and conditional independence to factor the full joint distribution. • X┴Y ↔P(X,Y)=P(X)P(Y) • X┴Z|Y ↔ P(X,Y,Z)=P(X,Y)P(Y,Z)/P(Y) • Bayesian networks • Graphical representation of a set of cond. inds • Express a factorization of the joint distribution • Can be used directly for selectivity estimation [Getoor’01]. • High dimensional distributions high overhead • Construction algorithms do not scale. X Y Z
Fixed Structure • “Tailored” solution • 2D histograms only, scalable construction • Relational independencies: • L.rdate┴ O.odate σL.rdate=a,O.odate=b(LxO)=σL.rdate=a(L) x σO.odate=b(O) • L.rdate┴ JSC • JLO┴ JSC • Design decisions • Join indicator has at most two parents • BN within a relation a directed tree
Bayesian Network lineitem rdate cdate orders JLO sdate odate JLP JLS JOC JSC S.acctbal size S.acctbal part supplier customer
Moral Graph rdate cdate JLO sdate odate JLP JLS JOC JSC C.acctbal size S.acctbal
Chordal Graph rdate cdate JLO sdate odate JLP JLS JOC JSC C.acctbal size S.acctbal
Junction Tree Distributions to be kept = marginals of “cliques” and “separators.” Factorization achieved! Efficient selectivity estimation via junction tree propagation, or a custom dynamic programming algorithm. sdate rdate cdate odate JLO odate C.acctbal JOC odate cdate odate sdate C.acctbal odate sdate sdate cdate odate sdate S.acctbal JLS S.acctbal C.acctbal JSC sdate odate sdate acctbal • Storage space: • (sdate,rdate) One 2D histogram • (odate,acctbal,JOC) Two 2D histograms (JOC=false,true) • (acctbal,odate,sdate) Three 1D histograms • Only 2D histograms needed! sdate sdate sdate size JLP C.acctbal S.acctbal sdate
Scalable Model Construction • Create a “local” Bayesian network for each relation R(X,Y,…)by testing pairwise correlations. • P(X,Y) = select X,Y,count(*) from R group by X,Y • Extract the maximum spanning tree using mutual information I(X;Y) as weight. • Find the best two predictors of each join indicator JRS. • P(X,Y,JRS=T) = select R.X,S.Y,count(*) from R,S where R.a=S.a group by R.X,S.Y • P(X,Y,JRS=F) = P(X)P(Y) – P(X,Y,JRS=T) • Very efficient; same complexity as CORDS [Ilyas’04].
Selectivity Estimation Estimate size of query: select c_name,c_address from lineitem,orders,customer where l_orderkey=o_orderkey and o_custkey=c_custkey and l_sdate<=“25/7/2011” and c_acctbal<=200000 sdate rdate cdate odate JLO odate C.acctbal JOC odate cdate odate sdate C.acctbal odate sdate sdate cdate odate sdate S.acctbal JLS S.acctbal C.acctbal JSC sdate odate sdate acctbal Equivalent: Estimate Pr(JLO=true, JOC=true, sdate<=“25/7/2011”, C.acctbal<=200000) sdate sdate Extract “Steiner tree”: Minimal subtree that contains JLO, JOC, sdate, C.acctbal sdate size JLP C.acctbal S.acctbal sdate
Selectivity Estimation 1. Substitute φ1*(cdate,odate)= φ1[sdate<=“25/7/2011”] φ2*(cdate,odate)= φ2[JLO=true] φ3*(odate)= φ3[JOC=true,acctbal<=200000] φ2=P(cdate,odate,JLO) μ23=P(odate) cdate odate JLO odate acctbal JOC odate cdate odate 2. Multiply φ12*(cdate,odate)= φ1*φ2*/μ12 φ3=P(odate,acctbal,JOC) μ12=P(cdate,odate) sdate cdate odate Estimate Pr(JLO=true, JOC=true, sdate<=“25/7/2011”, acctbal<=200000) 3. Marginalize φ12**(odate)= Σcdateφ12* 4. Multiply φ123*(odate)= φ12**φ3*/μ23 φ1=P(sdate,cdate,odate) Also in paper: dynamic programming algorithm that minimizes #multiplications by exploiting query optimizer order of requests. 5. Return Σodateφ123*
Implementation • Model construction outside DBMS. Create distributions with SQL queries. • Stores junction tree as tables in PostgreSQL catalog. • Graphical model foundation as PostgreSQL “nodes”. • Probability distributions stored as equi-width multidimensional histograms. • Cliques, multiplication, division, marginalization. • Junction tree, selectivity estimation algorithms • Integration with PostgreSQL query optimizer. • Load Steiner tree from catalog tables. • Bypass PostgreSQL selectivity estimation functions.
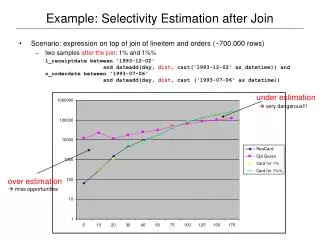
Impact of Capturing Correlations Can do selectivity estimation efficiently. Optimization time in the range of 10s of milliseconds select c_name,c_address from lineitem,orders,customer where l_orderkey=o_orderkey and o_custkey=c_custkey and o_tprice in [t1,t2] and l_eprice in [e1,e2] and c_acctbal in [b1,b2] Execution & optimization times Cost of plans (intermediate tuples) Avoid under-estimation by capturing the price correlation. Estimates very close to reality. Optimizer picks different plan than default PGSQL. Huge impact in execution time.
Accuracy of Estimates Optimization time less than 25 milliseconds • Multiplicative error: • max(real,estimate) / min(real,estimate) • Penalizes both under- and over- estimation. Subset of TPC-H schema. Tweaked data generator to introduce correlations. 400 random queries. Geometric average of multiplicative error. One order of magnitude better estimates for 5-join queries
Conclusions and Future Work • Attribute value independence assumption unfounded • Heuristic, not good enough • Most frequent source of horrible plans • Practical adaptation of graphical models implemented in PostgreSQL • Low overhead, good estimate quality • Specialized synopses • Low-dimensional, minimize multiplicative error, error guarantees after multiplication • Incremental updates • Building graphical model as a side-effect of query execution