Download
1 / 1
10 likes | 150 Views
Histograms of Sparse Codes for Object Detection. Xiaofeng Ren (Amazon, formerly Intel Labs) and Deva Ramanan (University of California, Irvine). Highlights Learning-based local features that replace and surpass HOG.

E N D
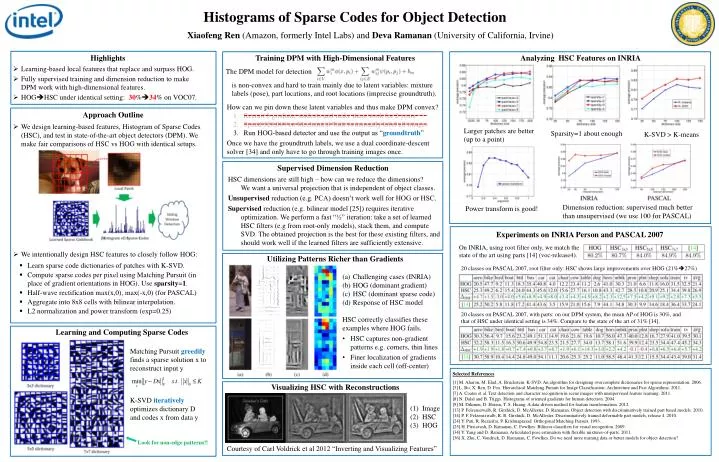
Histograms of Sparse Codes for Object Detection Xiaofeng Ren(Amazon, formerly Intel Labs) and Deva Ramanan (University of California, Irvine) • Highlights • Learning-based local features that replace and surpass HOG. • Fully supervised training and dimension reduction to make DPM work with high-dimensional features. • HOGHSC under identical setting: 30%34% on VOC07. Training DPM with High-Dimensional Features Analyzing HSC Features on INRIA The DPM model for detection is non-convex and hard to train mainly due to latent variables: mixture labels (pose), part locations, and root locations (imprecise groundtruth). • How can we pin down these latent variables and thus make DPM convex? • Recruit 5 graduate students and make them work for 2 years • Spend $20,000 on Mechanical Turk to manually label all images • Run HOG-based detector and use the output as “groundtruth” • Once we have the groundtruth labels, we use a dual coordinate-descent solver [34] and only have to go through training images once. Approach Outline • We design learning-based features, Histogram of Sparse Codes (HSC), and test in state-of-the-art object detectors (DPM). We make fair comparisons of HSC vs HOG with identical setups. Larger patches are better (up to a point) Sparsity=1 about enough K-SVD > K-means Supervised Dimension Reduction HSC dimensions are still high – how can we reduce the dimensions? We want a universal projection that is independent of object classes. Unsupervised reduction (e.g. PCA) doesn’t work well for HOG or HSC. Supervisedreduction (e.g. bilinear model [25]) requires iterative optimization. We perform a fast “½” iteration: take a set of learned HSC filters (e.g from root-only models), stack them, and compute SVD. The obtained projection is the best for these existing filters, and should work well if the learned filters are sufficiently extensive. Dimension reduction: supervised much better than unsupervised (we use 100 for PASCAL) Power transform is good! Experiments on INRIA Person and PASCAL 2007 On INRIA, using root filter only, we match the state of the art using parts [14] (voc-release4). • We intentionally design HSC features to closely follow HOG: • Learn sparse code dictionaries of patches with K-SVD. • Compute sparse codes per pixel using Matching Pursuit (in place of gradient orientations in HOG). Use sparsity=1. • Half-wave rectification max(x,0), max(-x,0) (for PASCAL) • Aggregate into 8x8 cells with bilinear interpolation. • L2 normalization and power transform (exp=0.25) Utilizing Patterns Richer than Gradients 20 classes on PASCAL 2007, root filter only: HSC shows large improvements over HOG (21%27%) Challenging cases (INRIA) HOG (dominant gradient) HSC (dominant sparse code) Response of HSC model 20 classes on PASCAL 2007, with parts: on our DPM system, the mean AP of HOG is 30%, and that of HSC under identical setting is 34%. Compare to the state of the art of 31% [14]. • HSC correctly classifies these examples where HOG fails. • HSC captures non-gradient patterns e.g. corners, thin lines • Finer localization of gradients inside each cell (off-center) Learning and Computing Sparse Codes Matching Pursuit greedilyfinds a sparse solution x to reconstruct input y Selected References [1] M. Aharon, M. Elad, A. Bruckstein. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. 2006. [3] L. Bo, X. Ren, D. Fox. Hierarchical Matching Pursuit for Image Classification: Architecture and Fast Algorithms. 2011. [7] A. Coates et al. Text detection and character recognition in sceneimages with unsupervised feature learning. 2011. [8] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. 2004. [9] M. Dikmen, D. Hoiem, T. S. Huang. A data-driven method for feature transformation. 2012. [13] P. Felzenszwalb, R. Girshick, D. McAllester, D. Ramanan. Object detection with discriminatively trained part based models. 2010. [14] P. F. Felzenszwalb, R. B. Girshick, D. McAllester. Discriminatively trained deformable part models, release 4. 2010. [24] Y. Pati, R. Rezaiifar, P. Krishnaprasad. Orthogonal Matching Pursuit. 1993. [25] H. Pirsiavash, D. Ramanan, C. Fowlkes. Bilinear classifiers for visual recognition. 2009. [34] Y. Yang and D. Ramanan. Articulated pose estimation with flexible mixtures-of-parts. 2011. [36] X. Zhu, C. Vondrick, D. Ramanan, C. Fowlkes. Do we need more training data or better models for object detection? Visualizing HSC with Reconstructions K-SVD iterativelyoptimizes dictionary D and codes x from data y (1) Image (2) HSC (3) HOG Look for non-edge patterns!! Courtesy of Carl Voldrick et al 2012 “Inverting and Visualizing Features”





















