Download

1 / 19
220 likes | 403 Views
STOCHASTIC CONTEXT FREE GRAMMAR. PARSING & USE. OUTLINE. Introduction to Stochastic Context Free Grammar(SCFG) Parsing of SCFG Use to RNA secondary structure prediction. SCFG. Chomsky hierarchy:. CONTEXT FREE GRAMMAR It’s a triple where: ∑ = set of terminal symbols(alphabet)

E N D
STOCHASTIC CONTEXT FREE GRAMMAR PARSING & USE
OUTLINE • Introduction to Stochastic Context Free Grammar(SCFG) • Parsing of SCFG • Use to RNA secondary structure prediction
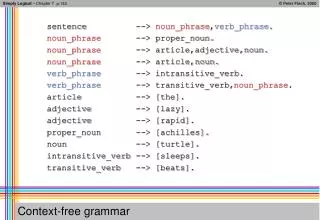
SCFG Chomsky hierarchy: • CONTEXT FREE GRAMMAR • It’s a triple where: • ∑ = set of terminal symbols(alphabet) • V = set of non terminal symbols • R = set of production rules in the form: • S=special start symbol and ∑ П V=Φ A string can be derived from another string ( ) if: and the production is a production of the grammar.
SCFG A Stochastic Context Free Grammar is a quadruple G=(∑,V,R,P): Probability function constraint Def.: Let G=(∑,V,R,P) a SCFG and a derivation sequence d, where is a string of non terminal symbols, the probability of the derivation d is:
, SCFG • Grammar can be ambiguous • Def. : The probability of SCFG G that produce the string s, is: , where are the derivation sequences that produces s.
SCFG • Chomsky Normal Form(CNF) • Def.: A CFG(or SCFG) is in CNF if all the rules are in this form: B and C non terminal symbol αis a single terminal symbol
SCFG - Parsing • Parsing process sequence Parser (synctacticanalyzer) Parse tree Give a sequence and a grammar, which is the best parse tree that generate the sequence, wath is which is the parse tree with the highest probability? CYK algorithm
SCFG - Parsing • CYK algorithm (Cocke-Younger-Kasami) • High usedfor NLP(NaturalLanguage Processing) • Dynamicprogramming • Work with SCFG in CNF
SCFG – Parsing • Input: SCFG G in CNF and word s. • Data Structure: dynamic programming 3-D arrray holds the maximum probability for a constituent with non terminal a spanning words i…j. Back-pointers to construct the parse tree. • Output: maximum probability parse.
SCFG - Parsing • Initialization: n = length of ,R = number of nonterminals in G. Table P[n,n,R] = 0 // set all values in table to 0. Triples G[n,n,R] = triples of (position,nonterminal1,nonterminal2). //traceback pointers For j = 1 to n do for all unit productions of type do if s[j] == then set P[j,1,V] = Pv() // the probability of the production set G[j,1,V] = new Triple(0,0,0) // indicates no further traceback - i.e. a child node end if end for end for
SCFG - Parsing • Mainloop: //i is the length of the span, j the start and k where to split into two subspans for i = 2 to n do for j = 1 to n-i+1 do for k = 1 to i-1 do for all productions of type do set newprob = P[j, k, X] *P[j + k, i – k, Y ]*pv(XY ) if newprob > P[j, i, V ] then set P[j, i, V ] = newprob set G[j, i, V] = new Triple(k,X,Y) // new traceback // point end if end for end for end for end for P[1][n][Start symbol in G] holds the probability of the most likely parse.
SCFG - Parsing • Memory cost: O(n^2*M) • Time cost: O(n^3*T) n=length of the input string M=number of non terminal symbols T=number of production rules in the type V-->XY
SCFG - Use • RNA primary structure: a nucleotide sequence constituent the mulecule, represented with a single string of the {a,c,g,u} alphabet • RNA secondary structure: refer to the retreat of the sequence(that is the primary structure) to her-self, due to the action of hydrogen link.
SCFG - Use Stem & loop
SCFG - Use • The secondarystructureof RNA isimportantbecause: • RNA “preserve” thisstructureduring the time • It’s common findsimilar RNA thathave the similarsecondarystructure, butdifferntsequenceofnucleotides • Evolutionof the RNA “follow” hisstructure Sequenceanalysisof RNA is more difficultthan DNA and otherproteins
SCFG - Use • Problem: - Prediction of RNA secondary structure for a single sequence? Analogy with SCFG Calculate the most likely “parse tree” that derive a string
SCFG - Use • Simple grammar for RNA: • S -> gSc | cSg | aSu | uSa | ε (complementary couples) • S -> aS | cS | gS | uS (left single basis) • S -> Sa | Sc | Sg | Su (right single basis) • S -> a | c | g | u (single basis) • S -> SS (fork)
SCFG - Use Nucleotides sequence String RNA secondary structure Parse tree