Download

1 / 26
260 likes | 392 Views
Modularity and Costs. Greg Busby Computer Science 614 March 26, 2002. Problem 1 – Complexity. Protocols are necessary to do network communications Both ends must agree on format to exchange messages Communication protocols are complex Using several protocols together is even more complex.

E N D
Modularity and Costs Greg Busby Computer Science 614 March 26, 2002
Problem 1 – Complexity • Protocols are necessary to do network communications • Both ends must agree on format to exchange messages • Communication protocols are complex • Using several protocols together is even more complex
Solution 1 – Layers • Implement each protocol independently • Allows cleaner implementation • Layer protocols • Maintains modularity • Reduces complexity – no need to understand interactions between protocols
Problem 2 – Delays • Messages get larger as additional headers are added at each layer • Processing overhead for switch between layers • Need to wait for one protocol to finish before starting the next • I/O overhead with multiple writes to memory as buffers are stored between layers
Solution 2 – Improve Performance • Will discuss several approaches, including pros and cons of each: • x-Kernel: Puts entire communication system directly in the kernel with specific objects and support routines • Integrated Layer Processing (ILP): Integrates protocol layers to reduce task switching and memory writes • Protocol Accelerator (PA): Reduces total data to send and shortens critical path of code between messages
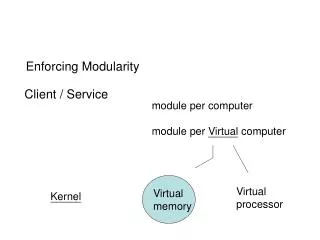
x-Kernel • Defines a uniform set of abstractions for protocols • Structures protocols for efficient interaction in the common case • Supports primitive routines for common protocol tasks
x-Kernel Architecture • Provides objects for protocols, sessions, and messages • Creates a kernel for a specific set of protocols (static) • Instantiates sessions for each protocol as needed (dynamic) • Messages are active objects that move through protocol/sessions • Provides specific support routines TCP UDP IP ETH
x-Kernel Objects • Protocols • Create sessions • Demux messages received • Sessions • Represent connections • Created and destroyed when connections made/terminated • Messages • Contain the data itself • Passed from level to level
x-Kernel Primitives • Buffer managers • Allocate, concatenate, split, and truncate • Operate in local process heap • Map managers • Add, remove, and map bindings for protocols • Event managers • Provide timers to allow timeouts
x-Kernel Performance • 2-3 x faster than Unix overall • Unix cost is primarily due to sockets • Protocol performance is comparable • Conclusion: architecture is the difference
Pros: Architecture simplifies the implementation of protocols Uniformity of interface between protocols makes protocol performance predictable and reduces overhead between protocols Possible to write efficient protocols by tuning the underlying architecture Don’t need to know exact protocol stack Cons: Requires new compilation of the kernel for each new set of protocols Doesn’t reduce message size (headers) or sequentiallity of processes Primarily useful as a research tool for protocol implementation, not to improve performance per se. x-Kernel Conclusions
Integrated Layer Processing (ILP) • Reduces protocol layers by integrating processing • Tunes performance to increase caching and avoid memory I/O • Eliminates redundant copies (similar to U-Net’s shared memory)
ILP Architecture • Combine protocol-specific manipulations in a single loop where possible • Process small pieces to make use of processor on-board caching • Put as much processing as possible in-line (macros) versus function calls
ILP Loop Application Data Application Data • Combine marshalling (encoding), encryption, and checksumming • Work in memory, reduce copying • Reduces steps from 5 to 2 (increased processing at step 1) 1. Marshalling (r/w) 1. Marshalling encryption, and checksumming (r/w) Application Data 2. Encryption (r/w) 3. Copying (r/w) TCP Buffer TCP Buffer 4. Checksum (r) 5. System copy (r/w) 2. System copy (r/w) Kernel Buffer Kernel Buffer Non-ILP Send ILP Send
ILP Processing (send) • Divide message into small parts • Begin marshalling and encryption on part B, then C… • Process part A once length is known • Finish protocol-specific processing • Doesn’t work if A must be processed first (ordering-constrained) RPC Header Data marshalling, encryption Part A Part B Part C Length align. checksum TCP Header
ILP Performance • Processing reduction of 20-25% • Throughput improvement of 10-15% • Actually reduces cache usage, although designed to optimize it • Performance gains can easily be masked by using strong encryption which drastically increases processing • Conclusion: performance results were such that use is “debatable in existing communication systems…”
Pros Decreased memory access up to 30% Slightly improved performance Cons Only applicable with non-ordering constrained functions Requires macros to increase speed, reducing flexibility Protocol stack must be known before-hand ILP Conclusions
The Protocol Accelerator (PA) • Reduces header overhead by sending non-changing protocol headers only once • Further reduces total bytes by packing other header information across protocols • Reduces layered protocol processing overhead by splitting processing of header and data (canonical processing)
PA Header Reduction • Four classes of Header Information • Connection Identification – don’t change during session • Protocol-specific Information – depends only on protocol state, not on message • Message-specific Information – depends on contents of message but not protocol state • Gossip – included because overhead is small, but optional • Connection Cookies • 8-byte field that replaces the Connection Identification information
PA Message Format Connection Id Present bit • Connection Cookie suffices for Connection ID on 2nd & later messages • Packing information explained below • Gossip is optional but useful Byte order bit (big- or little-endian) Connection cookie (62 bit number) Connection Identification (first message) Protocol-specific Information Message-specific Information Gossip (optional) Packing Information (if packed) Application Data
PA Processing Reduction • Canonical Protocol Processing – Breaks processing in a protocol layer into 2 parts • Pre-processing Phase – build or check message header without changing protocol state • Post-processing Phase – update protocol state; attempt to do this after message is sent or delivered • Pre-processing at every layer done before post-processing at any layer
PA Processing Reduction (cont.) • Header Prediction • Use post-processing phase to predict formation of next header • Packet Filters • A pre-pre-processor that checks or ensures header correctness without invoking protocol where possible; invokes protocol if necessary • Message packing • Pack backlogged messages together if application gets ahead – reduces space and processing since checksums etc. calculated only once
PA Processing (send) Application • Check backlog; queue and exit if any • Create packing and predicted header, add to message data • Run packet filter to create message-specific data (and gossip, if any) • Push to protocol if necessary • Push connection cookie onto front of message and send • Pass to protocol stack for post-processing to update protocol state Packer Unpacker Protocol Stack PreSend PreDeliver PA Network
PA Performance • Can gain an order of magnitude improvement over pure layered protocols • Maximal throughput achieved by reducing garbage collection and doing post-processing while messages are “on the wire” • Conclusion: Useful in improving performance as long as PA is used on both ends of
Pros Eliminates much of the overhead of layered protocols Significant speed improvement Canonical processing applicable in any case Cons Can’t communicate with non-PA peer Specific PA needed for set of protocols No fragmentation of messages, so only works on small messages PA Conclusions
Summary • Protocols are layered to improve modularity and reduce complexity • This reduces performance • Improving performance reduces modularity • Requires foreknowledge of protocol stack • Approaches • Increase use of kernel (x-Kernel) • Integrate processing of all layers together (ILP) • Reduce message size and speed critical path (PA) • All improve performance, but only PA results in significant improvement.