Download
1 / 1
10 likes | 142 Views
Information Sharing for Distributed Planning Prasanna Velagapudi pkv @ cs.cmu.edu. Start. A. A. B. B. C. C. D. D. Tractable Planning in Large Teams

E N D
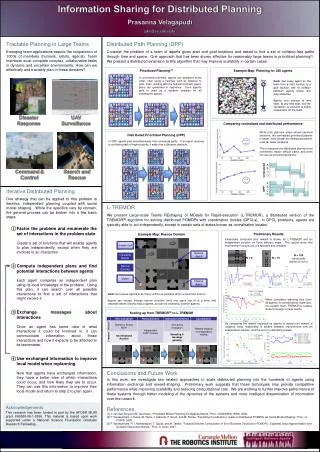
Information Sharing for Distributed Planning Prasanna Velagapudi pkv@cs.cmu.edu Start A A B B C C D D Tractable Planning in Large Teams Emerging team applications require the cooperation of 1000s of members (humans, robots, agents). Team members must complete complex, collaborativetasks in dynamic and uncertain environments. How can we effectively and tractably plan in these domains? DistributedPath Planning (DPP) Consider the problem of a team of agentsgiven start and goal locations and asked to find a set of collision-freepathsthrough time and space. Oneapproachthat has been showneffectiveforreasonablylarge teams is prioritized planning[1]. We present a distributedextension to thisalgorithmthatmayimprovescalability in certain cases. Goal Example Map: Planning for 240 agents Prioritized Planning[1] In prioritized planning, agents are assigned some order, often using a heuristic such as distance to goal. Then, starting with the highest (furthest) agent, plans are generated in sequence. Each agent’s path is used as a dynamic obstacle for all subsequent agents. Goal: Get every agent on the team from a start location to a goal location, with no collision between agents and/or any map obstacles. Agents can interact at any state, at any time step, and the interaction (a collision) is highly undesirable for the team. Unsafe Cell Comparing centralized and distributed performance Rescue Agent Clearable Debris Narrow Corridor Disaster Response UAV Surveillance Victim Cleaner Agent While both planners attain almost identical solutions, the centralized prioritized planner is faster, even though the distributed planner uses far fewer iterations. This is because the distributed planner must sometimes replan difficult paths, and does not use an incremental planner. Distributed Prioritized Planning (DPP) In DPP, agents plan simultaneously, then exchange paths. If an agent receives a conflicting path of higher priority, it adds it as a dynamic obstacle. Centralized Command & Control Search and Rescue DPP • IterativeDistributed Planning • Onestrategythatcanbeapplied to thisproblem is iterative, independent planning coupled withsocial model shaping. While the specificsvaryby domain, the generalprocesscanbebrokeninto a few basic steps: • Factor the problem and enumerate the set of interactions in the problem state • Create a set of functions that will enable agents to plan independently, except when they are involved in an interaction. • Compute independent plans and find potential interactions between agents • Each agent computes an independent plan using its local knowledge of the problem. Using this plan, it can search over all possible interactions to find a set of interactions that might involve it. • Exchange messages about interactions • Once an agent has some idea of what interactions it could be involved in, it can communicate information about those interactions and how it expects to be affected to its teammates. • Use exchanged information to improve local model when replanning • Now that agents have exchanged information, they have a better idea of which interactions could occur, and how likely they are to occur. They can use this information to improve their local model and return to step 2 to plan again. L-TREMOR We present Large-scale Teams REshaping of MOdelsforRapid-execution (L-TREMOR), a distributedversion of the TREMOR[2]algorithmforsolvingdistributedPOMDPswithcoordinationlocales (DPCLs). In DPCL problems, agents are typically able to act independently, except in certain sets of states known as coordination locales. Example Map: Rescue Domain Empirically computed joint reward is shown for L-TREMOR and an independent solution on three different maps. The results show that improvement occurs, but it is sporadic and unstable. N = 100 (structurally similar to N=10) N = 6 N = 10 Preliminary Results Scaling up from TREMOR[2] to L-TREMOR Goal: Get rescue agents to as many victims as possible within a fixed time horizon. Agents can interact through narrow corridors (only one agent can fit at a time) and clearable debris (blocks rescue agents, but can be cleared by cleaner agents). When cumulative planning time (over all agents) is normalized by team size, it is evident that L-TREMOR is scaling close to linearly to large teams. By comparing the reward expected by agents to actual joint reward, a negative linear relationship is evident between improvement over an independent solution, and the error in estimating reward. Conclusions and Future Work In this work, we investigate two related approaches to scale distributed planning into the hundreds of agents using information exchange and reward-shaping. Preliminary work suggests that these techniques may provide competitive performance while improving scalability and reducing computational cost. We are working to further improve performance of these systems through better modeling of the dynamics of the systems and more intelligent dissemination of information over the network. References [1] J. van den Berg and M. Overmars, "Prioritized Motion Planning for Multiple Robots,” Proc. of IEEE/RSJ IROS, 2005. [2] P. Varakantham, J. Kwak, M. Taylor, J. Marecki, P. Scerri, and M. Tambe, "Exploiting Coordination Locales in Distributed POMDPs via Social Model Shaping," Proc. of ICAPS, 2009. [3] P. Varakantham, R.T. Maheswaran, T. Gupta, and M. Tambe, "Towards Efficient Computation of Error Bounded Solutions in POMDPs : Expected Value Approximation and Dynamic Disjunctive Beliefs," Proc. of IJCAI, 2007. Acknowledgements This research has been funded in part by the AFOSR MURI grant FA9550-08-1-0356. This material is based upon work supported under a National Science Foundation Graduate Research Fellowship.





















