Download

1 / 27
270 likes | 482 Views
Revisiting Co-Processing for Hash Joins on the Coupled CPU-GPU Architecture. Jiong He , Mian Lu, Bingsheng He. School of Computer Engineering Nanyang Technological University. 27 th Aug 2013. Outline. Motivations System Design Evaluations Conclusions. Importance of Hash Joins.

E N D
Revisiting Co-Processing for Hash Joins on the Coupled CPU-GPU Architecture Jiong He, Mian Lu, Bingsheng He School of Computer Engineering Nanyang Technological University 27th Aug 2013
Outline • Motivations • System Design • Evaluations • Conclusions
Importance of Hash Joins • In-memory databases • Enable GBs even TBs of data reside in main memory (e.g., the large memory commodity servers) • Are hot research topic recently • Hash joins • The most efficient join algorithm in main memory databases • Focus: simple hash joins (SHJ, by ICDE 2004) and partitioned hash joins (PHJ, by VLDB 1999)
Hash Joins on New Architectures • Emerging hardware • Multi-core CPUs (8-core, 16-core, even many-core) • Massively parallel GPUs (NVIDIA, AMD, Intel, etc.) • Query co-processing on new hardware • On multi-core CPUs: SIGMOD’11 (S. Blanas), … • On GPUs: SIGMOD’08 (B. He), VLDB’09 (C. Kim), … • On Cell: ICDE’07 (K. Ross), …
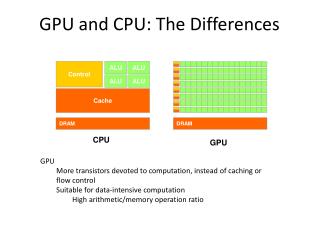
Light-weight workload: Create context, Send and receive data, Launch GPU program, Post-processing. Bottlenecks Heavy-weight workload: All real computations. • Conventional query co-processing is inefficient • Data transfer overhead via PCI-e • Imbalanced workload distribution CPU GPU PCI-e Cache Cache CPU GPU Main Memory Device Memory
The Coupled Architecture • Coupled CPU-GPU architecture • Intel Sandy Bridge, AMD Fusion APU, etc. • New opportunities • Remove the data transfer overhead • Enable fine-grained workload scheduling • Increase higher cache reuse CPU GPU Cache Main Memory
Challenges Come with Opportunities • Efficient data sharing • Share main memory • Share Last-level cache (LLC) • Keep both processors busy • The GPU cannot dominate the performance • Assign suitable tasks for maximum speedup
Outline • Motivations • System Design • Evaluations • Conclusions
Fine-Grained Definition of Steps for Co-Processing • Hash join consists of three stages (partition, build and probe) • Each stage consists of multiple steps (take build as example) • b1: compute # hash bucket • b2: access hash bucket header • b3: search the key list • b4: insert the tuple
Co-Processing Mechanisms • We study the following three kinds of co-processing mechanisms • Off-loading (OL) • Data-dividing (DD) • Pipeline (PL) • With the fine-grained step definition of hash joins, we can easily implement algorithms with those co-processing mechanisms
Off-loading (OL) • Method: Offload the whole step to one device • Advantage: Easy to schedule • Disadvantage: Imbalance CPU GPU
Data-dividing (DD) • Method: Partition the input at stage level • Advantage: Easy to schedule, no imbalance • Disadvantage: Devices are underutilized CPU GPU
Pipeline (PL) • Method: Partition the input at step level • Advantage: Balanced, devices are fully utilized • Disadvantage: Hard to schedule CPU GPU
Determining Suitable Ratios for PL is Challenging • Workload preferences of CPU & GPU vary • Different computation type & amount of memory access across steps • Delay across steps should be minimized to achieve global optimization
Cost Model • Abstract model for CPU/GPU • Estimate data transfer costs, memory access costs and execution costs • With the cost model, we can • Estimate the elapsed time • Choose the optimal workload ratios More details can be found in our paper.
Outline • Motivations • System Design • Evaluations • Conclusions
System Setting Up • System configurations • Data sets • R and S relations with 16M tuples each • Two attributes in each tuple: (key, record-ID) • Data skew: uniform, low skew and high skew
Discrete vs. Coupled Architecture • In discrete architecture: • data transfer takes 4%~10% • merge takes 14%~18% • The coupled architecture outperforms the discrete by 5%~21% among all variants 21.5% 15.3% 5.1% 6.2%
Fine-grained vs. Coarse-grained • For SHJ, PL outperforms OL & DD by 38% and 27% • For PHJ, PL outperforms OL & DD by 39% and 23% 23% 38% 39% 27%
Unit Costs in Different Steps • Unit cost represents the average processing time of one tuple for one device in one step • Costs vary heavily across different steps on two devices Build Probe Partition
Ratios Derived from Cost Model • Ratios across steps are different • In the first step of all three stages, the GPU takes should take most of the work (i.e. hashing) • Workload dividing are fine-grained at step level
Other Findings • Results on skewed data • Results on input with varying size • Evaluations on some design tradeoffs, etc. More details can be found in our paper.
Outline • Motivations • System Design • Evaluations • Conclusions
Conclusions • Implement hash joins on the discrete and the coupled CPU-GPU architectures • Propose a generic cost model to guide the fine-grained tuning to get optimal performance • Evaluate some design tradeoffs to make hash join better exploit the hardware power • The first systematic study of hash join co-processing on the emerging coupled CPU-GPU architecture
Future Work • Design a full-fledged query processor • Extend the fine-grained design methodology to other applications on the coupled CPU-GPU architecture
Acknowledgement • Thank Dr. QiongLuo and OngZhong Liang for their valuable comments • This work is partly supported by a MoEAcRFTier 2 grant (MOE2012-T2-2-067) in Singapore and an Interdisciplinary Strategic Competitive Fund of Nanyang Technological University 2011 for “C3: Cloud-Assisted Green Computing at NTU Campus”