Download

1 / 21
220 likes | 414 Views
Interfaces between Speech and Non-Speech Audio Technology. Michael Pucher (FTW Vienna, ICSI Berkeley). Contents. Text-to-Speech Synthesis (TTS) Automatic Speech Recognition (ASR, STT) Dialog Systems Multimodal Mobile Applications Resources. Non-linguistic. Sound signals. Music.

E N D
Interfaces between Speech and Non-Speech Audio Technology Michael Pucher (FTW Vienna, ICSI Berkeley)
Contents • Text-to-Speech Synthesis (TTS) • Automatic Speech Recognition (ASR, STT) • Dialog Systems • Multimodal Mobile Applications • Resources
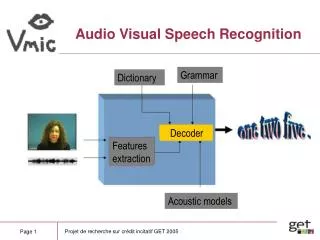
Non-linguistic Sound signals Music Perspectival, spatial cues Paralinguistic Speaker characteristics Affective states and attitudes Pragmatics and discourse Linguistic Structural prosodic elements Lexical semantics and syntax Auditory representations Dialog Systems TTS ASR
TTS Examples • 16kHz natural voice • 16kHz unit selection synthesis (server-based) • 8kHz diphone-based synthesis with lexicon (embedded or distributed) • 8kHz diphone-based synthesis without lexicon (embedded) • Application specific lexicon • Gerald R. Ford tSE-r6ld a:R fo:rd
Limited Expressiveness of Speech 1 • Limited expressiveness of Expressive TTS = Limited expressiveness of speech • Limited expressiveness of speech because of unlimited expressiveness1 of speech • Because everything is expressible in language, the messages are less useful for certain purposes (too complex) • Simpler, less expressive codes (sounds, icons) may be used in context and lead to shorter messages • Disadvantages of speech • Seriality • Non-universality
Types of ASR and Applications • Isolated word recogniton • Large vocabulary Speech recognition • Conversational Speech recognition • Speech Recognition in noisy environments Command & control Broadcast news transcription Meeting transcription Car navigation Speaker dependent or speaker independent
Other Related Technologies • Speech • Speaker verification • NLP • Dialog act detection • Topic detection
Music Information Retrieval (MIR) • Query By Humming (Fraunhofer) • Non-speech sound as an input pattern to search for other non-speech sounds • http://www.musicline.de/de/melodiesuche/input • Performer Style Identification • Melody and Rhythm Extraction • Music Similarity • Genre Classification
Dialog Systems - ASR • <rule id="exit"> • <one-of> • <item>exit</item> • <item>quit</item> • </one-of> • </rule> • 3 Types of Recognition in state-of-the-art Dialog Systems • Isolated word • Recognition grammar • Statistical Language Model (SLM) + grammar for more robustness • <rule id=„commands"> • <item repeat="0-1"> • move • </item> • <one-of> • <item>forward</item> • <item>backward</item> • </one-of> • </rule> „um ah to san francisco from new york“ 1. Apply SLM 2. Apply grammar on results of SLM
Dialog Systems – TTS and Audio • Loquendo TTS Mixer • Play and mix TTS and audio files • Fadein, fadeout • Pause and resume • Record Paolo Massimino : Loquendo S.p.A. From Marked Text to Mixed Speech and Sound
Dialog Management 1 • Usages of non-speech audio • Replace prompts • Indicate dialog turns and dialog states • Indicate menu structure (3Daudio) • Create listen & feel of the application • System response time • Questions • Bargein, Streaming and Standardization
Dialog Management 2 Bob Cooper : Avaya Corporation A Case Study on the planned and actual Use of Auditory Feedback and Audio Cues in the Realization of a Personal Virtual Assistant • A good bad example • Uses only speech • Audio enhancement for transitions • Audio enhancement for states
Dialog Managment 3 • VoiceXML Version 2.0 • W3C (Word Wide Web Consortium) standard for voice dialog design • Form filling paradigm similar to web forms • Synthesis Markup Language (SSML) Version 1.0 <prosody contour="(0%,+20Hz) (10%,+30%) (40%,+10Hz)"> good morning </prosody> <voice gender="female"> Any female voice here. <voice age="6"> A female child voice here. </voice> </voice>
Limited Expressiveness of Speech 2 • Limited expressiveness of human-machine voice dialog compared to a natural dialog • Natural dialog is probable multimodal • Role of non-speech sound in human communication
The Importance of Multimodality for Mobile Applications • Multimodal communication is perceived as natural • Disadvantages of unimodal interfaces for mobile devices • Small displays • No comfortable alphanumeric keyboards • Visual access to the display is not always possible • Disadvantages cannot be overcome by increasing processor and memory capabilities
Multimodal Dialog Managment • Speech Application Language Tags (http://www.saltforum.org) • Possible combination with non-speech audio at all states and transitions • Similar to (unimodal) dialog systems Minhua Ma : University of Ulster Paul Mc Kevitt : University of Ulster Lexical Semantics and Auditory Display in Virtual Storytelling
Asymmetric Multimodality • For Multiparty applications • Users select preferred modalities (e.g. speech, visual, music?) • System is able to translate content from one modality to another • MONA – Mobile Multimodal Next Generation Applications • Multiuser quiz application
Resources • TTS • Festival 2.0, to build unit selection voices • Festival Lite, for embedded TTS • FreeTTS, a Java speech synthesizer • The Mbrola project, many synthetic voices available • ASR • Sphinx • Htk • Multimodal Systems • SALT implementations
Thank you for your attention Contact: pucher@ftw.at http://userver.ftw.at/~pucher