Download

1 / 14
150 likes | 449 Views
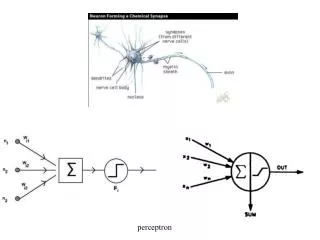
Perceptron Multicamadas (MLP). Prof. Júlio Cesar Nievola. Perceptron Multicamadas (MLP). O perceptron tem restrições para trabalho com dados não-linearmente dependentes. Minsky e Papert em 1969 mostraram que uma rede com pelo menos uma camada escondida supera estas limitações.

E N D
Perceptron Multicamadas (MLP) Prof. Júlio Cesar Nievola
Perceptron Multicamadas (MLP) • O perceptron tem restrições para trabalho com dados não-linearmente dependentes. • Minsky e Papert em 1969 mostraram que uma rede com pelo menos uma camada escondida supera estas limitações. • Como ajustar os pesos foi proposto por Rumelhart, Hinton e Williams (além de outros como Parker, Le Cun e Werbos). Prof. Júlio Cesar Nievola - PPGIA - PUCPR
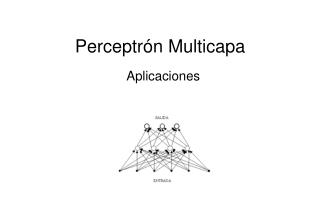
Perceptron Multicamadas (MLP) • Tem uma estrutura em camadas. • Cada camada recebe dados da camada imediatamente inferior e envia para a camada subseqüente. • Não existem conexões entre elementos da mesma camada. • As unidades de entrada são unidades fan-out. Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Perceptron Multicamadas (MLP) • A rede MLP pode ter qualquer número de camadas, bem como unidades binárias. • Uma MLP com uma camada escondida é suficiente para aproximar com precisão arbitrária qualquer função com um número finito de descontinuidades desde que a função de ativação das unidades escondidas seja não-linear. Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Regra Delta Generalizada • A ativação é uma função diferenciável da entrada total na qual • Para obter a generalização correta da regra delta deve-se ter: • A medida do erro Ep é definida como o erro total quadrático para o padrão p nas unidades de saída: Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Regra Delta Generalizada • Tem-se como uma medida total do erro. Usando a regra da cadeia: • Observa-se que: • Para obter uma atualização como a regra delta faz-se: Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Regra Delta Generalizada • Tem-se uma descida do gradiente se as alterações forem: • Usando a regra da cadeia: • O segundo elemento é, portanto: Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Regra Delta Generalizada • Existem dois casos para o primeiro fator da regra da cadeia. No primeiro caso considera-se que i é uma unidade de saída e portanto: • Neste caso obtém-se: • Se i não for uma unidade de saída pode-se obter uma medida do erro como uma função da soma ponderada da camada escondida para a camada de saída: Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Regra Delta Generalizada • Usando-se a regra da cadeia: • Substituindo na primeira regra da cadeia: Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Funcionamento com a Retropropagação • A entrada é apresentada e propagada para a frente através da rede calculando as ativações para cada unidade de saída. • Cada unidade de saída é comparada com o valor desejado, resultando um valor de erro. • Existe um passo de retorno na rede onde se calculam os erros em cada unidade e são realizadas alterações nos pesos. Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Alg. de Retropropagação (1) 1. Escolher um pequeno valor positivo para o tamanho do passo , e assinalar pesos iniciais pequenos aleatoriamente selecionados {wi,j} para todas as células. 2. Repetir até que o algoritmo convirja, isto é, até que alterações nos pesos e no erro médio quadrático tornem-se suficientemente pequenas: 2a. Escolher o próximo exemplo de treinamento E e sua saída correta C (a qual pode ser um vetor). 2b. Passo de propagação avante: Fazer uma passagem da entrada para a saída através da rede para calcular as somas ponderadas, Si, e as ativações, ui = f(Si), para todas as células. Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Alg. de Retropropagação (2) 2c. Passo de retropropagação: Iniciando com as saídas, fazer uma passagem de cima para baixo através das células de saída e intermediárias calculando: 2d. Atualizar os pesos: Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Aprendizagem e Momento • A aprendizagem requer alterações no peso proporcionais a Ep/w. • Na realidade, a descida do gradiente requer passos infinitesimalmente pequenos. Na prática deseja-se uma constante de aprendizagem tão grande quanto possível, o que leva a oscilações. • Para evitar isto, acrescenta-se um termo, denominado momento: Prof. Júlio Cesar Nievola - PPGIA - PUCPR
Deficiências da Retropropagação • Parada da rede: Se os pesos forem ajustados em valores muito grandes a ativação se torna zero ou um e os ajustes passam a ser nulos, parando a rede. • Mínimos locais: A superfície de erro de uma rede complexa é cheia de montanhas e vales. Desta forma, a mesma pode ficar presa em um ponto de mínimo local. Prof. Júlio Cesar Nievola - PPGIA - PUCPR