Download
1 / 41
450 likes | 866 Views
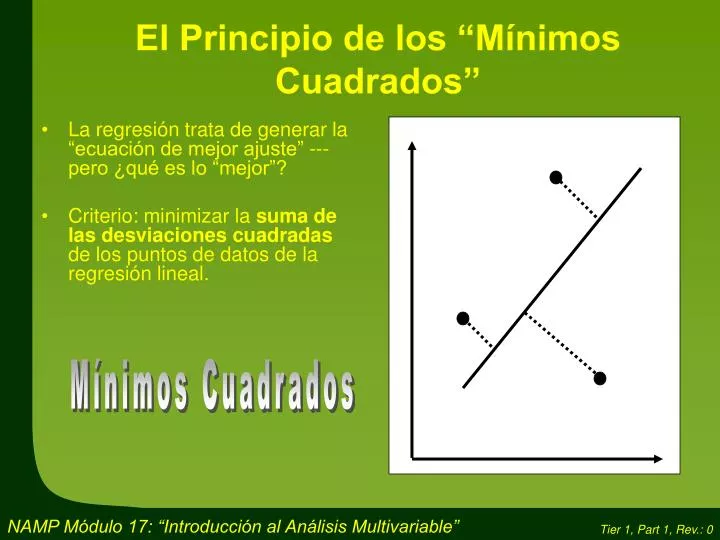
La regresión trata de generar la “ecuación de mejor ajuste” --- pero ¿qué es lo “mejor”? Criterio: minimizar la suma de las desviaciones cuadradas de los puntos de datos de la regresión lineal. El Principio de los “Mínimos Cuadrados”. Mínimos Cuadrados.

E N D
La regresión trata de generar la “ecuación de mejor ajuste” --- pero ¿qué es lo “mejor”? Criterio: minimizar la suma de las desviaciones cuadradas de los puntos de datos de la regresión lineal. El Principio de los “Mínimos Cuadrados” Mínimos Cuadrados
(Suma de los cuadrados de la media de Y) (Suma de los cuadrados de la regresión lineal) ¿Qué tan Buena es la Regresión (Parte 1) ? ¿Qué tan bien representa nuestros datos originales la ecuación de regresión? La proporción (porcentaje) de la varianza en y que es explicada por la ecuación de regresión es representada por el símbolo R2. R2=
R2 Alto- buen ajuste R2 Bajo- poco ajuste Variabilidad Ajustada - ilustración
Recuerde que empleó una muestra de la población de los puntos de datos potenciales para determinar la ecuación de regresión. e.g. un valor cada 15 minutos, 1-2 semanas de operación de datos Una muestra diferente dará una ecuación diferente con diferentes coeficientes de bi Como se muestra en la siguiente diapositiva, la muestra puede afectar enormemente la ecuación de regresión… ¿Qué tan Buena es la Regresión (Parte 2) ? ¿Qué tan bien predecirá esta ecuación de regresión los NUEVOS puntos de datos?
Muestreando variablidad de los Coeficientes de Regresión- ilustración Muestra 2: y = a’’x + b’’ + e Muestra 1: y = a’x + b’ + e
Los límites de confianza (x%) son las fronteras superior e inferior que tienen una probabilidad x% de encerrar el valor de población verdadero de una variable dada Generalmente mostradas como barras arriba y debajo de un punto de dato predicho: Límites de Confianza
Los datos empleados para la regresión son usualmente normalizados para tener una media de cero y varianza de uno. De otra forma los cálculos estarían dominados (parcializados) por variables, presentándose: valores numéricos muy grandes varianza grande Esto significa que el software del AMV nunca ve los datos originales, sólo la versión normalizada Normalización de los Datos
Cada variable es representada por una barra de varianza y su media (centro). Normalización de los Datos - ilustración Sólo Media-centrada Sólo Varianza-centrada Datos sin procesar Normalizada
Requerimientos de los Datos Datos normalizados Errores normalmente distribuidos con media cero Variables independientes no correlacionadas Implicaciones si los Requerimientos No se Logran Mayores límites de confianza alrededor de los coeficientes de regresión (bi) Predicción más pobre de nuevos datos Requisitos para la Regresión
Análisis del Componente Principal (ACP) Sólo X’s Proyecciones a las Estructuras Latentes (PEL) a.k.a. “Mínimos Cuadrados Parciales” X’s y Y’s Análisis Multivariable Ahora estamos listos para empezar a hablar acerca del análisis multivariable (AMV). Existen dos tipos principales de AMV: Puede ser la misma base de datos, i.e., puedes hacer el ACP en sobre la totalidad de la muestra (X’s y Y’s juntos) Xx X Y Empecemos con el ACP. Note que el ejemplo de la comida europea al principio fue ACP, debido a todos los tipos de comida fueron tratados como equivalentes.
El propósito del ACP es el de proyectar un espacio de datos con un gran número de dimensiones correlacionadas (variables) en un segundo espacio de datos con un número mucho menor de dimensiones independientes (ortogonal). Esto es justificable científicamente gracias a la Navaja de Ockham. Muy en el fondo, la Naturaleza ES simple. Seguido, la dimensión espacial más baja corresponde más de cerca a lo que está sucediendo en un nivel físico. El reto es interpretar los resultados del de una forma científicamente válida. Propósito del ACP Recordatorio… “Navaja de Ockham”
Ventajas del ACP Entre las ventajas del ACP están: • Las variables no correlacionadas se prestan para el análisis estadístico tradicional • Espacios de bajas dimensiones que son más fáciles para trabajar • Las nuevas dimensiones muy a menudo, representan más claramente la base de la estructura de los grupos de variables (nuestro amigo Ockham) -1 +1 Recordatorio… “Atributos Latentes”
Encontrar un componente (vector de dimensión) que ajuste la mayor cantidad de variaciones de x como sea posible Encontrar un segundo componente que: sea ortgonal al (no correlacionado con) primero ajuste la mayor cantidad posible de los restos de la variación de x El proceso continua hasta que el investigador esté satisfecho o el ajuste sea mínimo. Cómo funciona el ACP (Concepto) El ACP es un proceso paso a paso. Así es como funciona conceptualmente:
Cómo Trabaja el ACP (Matemáticas) Así es como trabaja el ACP matemáticamente: • Considerar una (n x k) matríz de datos X(n observaciones, k variables) • Modelos PCS como(asumiendo datos normalizados): X = T * P’ + E • dondeTson los valores de cada observación de los nuevos componentesPson las cargas de las variables originales en los nuevos componentesE matriz residual, conteniendo el ruido Como en la regresión linear sólo se usan matrices
. . . . . . . . . . . . Cómo Trabaja el ACP (Visualmente) El ACP trabaja visualmente proyectando la nube de datos multidimensionales en un “hiperplano” definido por los primeros dos componentes. La imagen muestra esto en 3-D, para que sea sencillo de entender, pero en realidad puede haber una docena de o hasta cientos de dimensiones: plano proyección X3 er X2 do La nube de datos (en rojo) es proyectada en un plano definido por los primeros 2 componentes X1 3 variables originales
Número de Componentes Los componentes son simplemente los nuevos ejes que son creados para ajustar la mayoría de la varianza con el menor número de dimensiones. La metodología del ACP asegura que los componentes sean extraídos en orden decreciente de la varianza. En otras palabras, el primer componente siempre ajusta la mayoría de la varianza, el segundo ajusta la mayoría restante de la varianza, y así sucesivamente: 1 2 3 4 5 6 . . . Eventualmente, los componentes de mayor nivel representan principalmente ruido. Esto es algo bueno, y de hecho una de las razones por las cuales se usa el ACP. Debido a que el ruido es relegado a los componentes de alto nivel, éste está ausente en los primeros componentes. Esto se debe a que todos los componentes son ortogonales el uno del otro, lo que significa que son estadísticamente independientes o no correlacionados.
Eigenvalores de la matriz A : Definida matemáticamente por (A - I) = 0 Útil como “medida de importancia” para las variables El Criterio de los Eigenvalores • Existen dos maneras de determinar cuándo dejar de crear nuevos componentes: • Criterio Eigenvalor • Scree test • La primera de éstas usa la siguiente definición matemática: • Usualmente, componentes con eigenvalores menores de uno son descartados, ya que presentan menos poder de definición que el que presentaban originalmente las variables originales.
El segundo método es una simple técnica gráfica: Gráfica de los eigenvalores vs. número de componentes Extraer componentes hasta el punto donde se estabiliza la “gráfica” La cola derecha de la curva es “rocosa” (como la parte inferior de una pendiente rocosa) 8 7 6 5 4 3 2 1 Eigenvalores 1 2 3 4 5 6 Componente # El Criterio del Punto de Inflexión (Scree Test)
Basar en la fuerza y dirección de las cargas Identificar los conjuntos de variables que pudieran estar físicamente relacionadas o que provienen de un origen común e.g., En la producción de papel, las propiedades de fortaleza tales como rasgado, ruptura, longitud de rompimiento en el papel están todas relacionadas a la longitud y enlaces de las fibras iniciales. Interpretación de los Componentes del ACP Como cualquier tipo de AMV, la parte más complicada del ACP es la interpretación de los componentes. El software es 100% matemático y da las mismas soluciones aún si los datos están relacionados al consumo de diesel o a los resultados de las carreras de caballos. El ingeniero es el que debe de dar sentido a las soluciones del software. En general, se debe de:
ACP vs. PEL ¿Cuál es la diferencia entre ACP y PEL? Las PEL son una versión de regresión multivariables. Usa dos modelos diferentes de ACP, uno para las X’s y otro par alas Y’s, y encuentra el enlace entre las dos. Matemáticamente, la diferencia es: En el ACP, la varianza ajustada por el modelo es maximizada. En las PEL, se maximiza la covarianza. Xx X Y
PEL encuentra una serie de componentes ortogonales que: maximizan el nivel de ajuste de la X e Y provén de una ecuación predictora para Y en términos de las X’s Esto se logra mediante: Ajuste de un grupo de componentes a X (como en ACP) Similarmente ajustar un grupo de componentes a Y Combinar los dos grupos de componentes de tal manera que se maximice el ajuste de X e Y Cómo Trabaja el PEL (Concepto) El PEL también es un proceso paso-a-paso. Así es como funciona conceptualmente:
Cómo Traba el PEL (Matemáticas) Así es como trabaja el PEL matemáticamente: • X = TP’ + E relación externa para X (como ACP) • Y = UQ’ + F relación externa para Y (como ACP) • uh = bhthrelación interna para los componentesh = 1,…,(# de componentes) Los factores de peso w son usados para asegurarse que las dimensiones son ortogonales
PEL – la “Relación Interna” La forma como trabaja el PEL visualmente es “enrollando” los dos modelos del ACP (X e Y) hasta que su covarianza es optimizada. Es este “enrollado” lo que produce el nombre de mínimos cuadrados parciales. Los 3 son resueltos simultáneamente vía métodos numéricos
Interpretación de los Componentes del PEL La interpretación de los resultados del PEL presenta todas las dificultades del ACP, además de uno más: dar sentido a los componentes individuales del espacio X e Y. En otras palabras, para que los resultados tengan sentido, el primer componente de X debe estar relacionado de alguna manera con el primer componente de Y. Observe que a lo largo de este curso, la palabras “causa” y “efecto” están ausentes. El AMV determina SÓLO las correlaciones. La única excepción es cuando se ha empleado un adecuado diseño del experimento. Este es un ejemplo de una falsa correlación: las semillas en un alimentador de aves permanece lleno todo el invierno, pero desaparece de repente en primavera. Usted concluye que el clima cálido hicieron desintegrase a las semillas…
Tipo de Salidas del AMV El software del AMV genera dos tipos de salidas: resultados y diagnósticos. Hemos visto la gráfica de Resultados y Entradas en el ejemplo de la comida. Algunos otros son mostrados en las siguientes diapositivas. • Resultados • Gráficas de Resultados • Gráficas de Entradas • Diagnósticos • Gráficas de Residuos • Observado vs. Predicho • …(muchas más) Ya estudiadas…
Residuales • También llamado “Modelo a Distancia” (DModX) • Contiene todo el ruido • Definición: DModX = ( eik2 / D.F.)1/2 • Empleado para identificar salidas moderadas • Salidas extremas visibles en la Gráfica de Resultados (siguiente diapositiva) Original observations
“Modelo a Distancia” . plano proyección eik er do i=observaciónk=variable
Observado vs. Predicho Esta gráfica presenta los valores de Y predichos por el modelo, contra los valores originales de Y. Un modelo perfecto tendría sólo puntos a lo largo de la línea. 32- meses de 1 día. M3 (PEL), Sin Título Ypred[14](53ª1034.AI)/YVar(53A1034.AI) MODELO IDEAL
Se presenta una lista de algunos de los principales retos a los que se enfrentará cuando trabaje con el AMV. ¡Usted ha sido advertido! Dificultad de interpretación de las graficas (“como leer hojas de té”) Datos pre-procesados Las curvas de control pueden disfrazar correlaciones reales Datos discretos vs. promediado vs. interpolados Determinar los retrasos para los tiempos de residencia en el diagrama de flujo Problemas con el incremento de tiempo e.g., ¿valores segundo-a-segundo o promedios diarios? Algunas variables sensitivas típicas para la aplicación del AMV a un proceso con datos reales se muestran en la siguiente página… Retos del AMV
Fin del Tier 1 ¡Felicidades! Asumiendo que ha realizado toda la lectura, este es el fin del Tier 1. Sin duda mucha información parece confusa, pero las cosas se aclararán cuando se resuelvan ejemplos reales en el Tier 2. Sólo falta completar un pequeño quiz…
Tier 1 Quiz • Pregunta 1: • Observar una o dos variables a la vez no es recomendable porque generalmente las variables están correlacionadas. ¿Qué significa esto exactamente? • Estas variables tienden a incrementar y decrecer al unisono. • Estas variables probablemente estén midiendo lo mismo, indirectamente sin embargo. • Estas variable revelan una variable común y profunda que probablemente no esté medida. • Estas variables no son estadísticamente independientes. • Todas las anteriores.
Tier 1 Quiz • Pregunta 2: • ¿Cuál es la diferencia entre “información” y “conocimiento”? • La información está en la computadora o en un pedazo de papel, mientras que el conocimiento está dentro de la cabeza de las personas. • Sólo los científicos poseen el “verdadero” conocimiento. • La información es matemática, mientras que el conocimiento no lo es. • La información incluye relaciones entre variables, pero no tiene respaldo de la base de las causas científicas. • El conocimiento puede adquirirse sólo a través de la experiencia.
Tier 1 Quiz • Pregunta 3: • ¿Por qué el AMV nunca revela la causa-y-efecto, al menos que se emplee un experimento diseñado? • Causa-y-efecto puede ser determinado sólo en el laboratorio. • Los experimentos diseñados eliminan el error. • El AMV sin experimentos diseñados sólo es inductivo, mientras que la relación causa-y-efecto requiere de una deducción. • Sólo los efectos son medibles. • Los científicos diseñan los experimentos para trabajar perfectamente la primer vez.
Tier 1 Quiz • Pregunta 4: • ¿Cuál es la desventaja más grande de usar el modelo de la “caja negra” en lugar de usar uno basado en los primeros principios? • No hay unidades de operación. • El modelo es sólo tan bueno como los datos empleados para crearlo. • Datos de reacciones químicas y datos termodinámicos no son usados. • Un modelo de caja negra puede no tomar en cuenta el diagrama de flujo completo. • Los modelos de AMV son sólo lineares.
Tier 1 Quiz • Pregunta 5: • ¿Qué nos dice un intervalo de confianza? • Qué tan dispersa está la información alrededor de la línea de regresión. • El rango dentro del cual cierto porcentaje de valores es esperado que se encuentre. • El área dentro de la cual la regresión lineal debe caer. • El grado de credibilidad de los resultados de un análisis específico. • El número de veces que debe repetirse un análisis para estar seguro de los resultados.
Tier 1 Quiz • Pregunta 6: • Cuando los datos fueron recopilados, algunos de los sensores de la planta no funcionaba correctamente y daba lecturas imprecisas. ¿Cuáles son las implicaciones a tomar en el análisis estadístico? • Se ajustan en el modelo más términos cuadráticos y productos cruzados a los datos. • Valores de la media más elevados de los esperados normalmente. • Valores de varianza más elevados para las variables asociadas con el mal funcionamiento del sensor. • Diferente selección de variables para incluir en el análisis. • Término residual mayor en el modelo.
Tier 1 Quiz • Pregunta 7: • ¿Por qué el reducir el número de dimensiones (más variables para menos componentes) tiene sentido desde un punto de vista científico? • Los nuevos componentes pueden corresponder a la base física del fenómeno que no puede ser medido directamente. • Menos dimensiones son más sencillas de observar en una gráfica o computadora. • La navaja de Ockham limita a los científicos a menos de cinco dimensiones. • El mundo real está limitado a sólo tres dimensiones. • Todas las anteriores.
Tier 1 Quiz • Pregunta 8: • Si dos puntos en una gráfica de resultados están demasiado cerca, ¿significa esto que estas dos observaciones son casi idénticas? • Sí, porque están en la misma posición del cuadrante. • No, porque se debe a un error experimental. • Sí, porque presentan virtualmente el mismo efecto en el AMV. • No, porque la gráfica de resultados es sólo una proyección. • Respuestas (a) y (c).
Tier 1 Quiz • Pregunta 9: • Observando el ejemplo de la comida, ¿qué países aparentan estar correlacionados con un gran consumo de aceite de oliva? • Italia y España y en menor grado Portugal y Austria. • Sólo Italia y España. • Sólo Italia. • Irlanda e Italia. • Todos los países menos Suecia, Dinamarca e Inglaterra.
Tier 1 Quiz • Pregunta 10: • ¿Por qué el error queda relegado cuando se tiene un mayor orden de componentes en el ACP? • Porque la Navaja de Ockham así lo establece. • Porque el mundo real sólo tiene tres dimensiones. • Porque el ruido es falsa información. • Porque el AMV es capaz de corregir datos pobres. • Porque el ruido no está correlacionado con otras variables.






















