Download

1 / 63
630 likes | 782 Views
Hardware-Assisted Visibility Sorting for Tetrahedral Volume Rendering. Steven Callahan Milan Ikits Jo ã o Comba Cl á udio Silva. Overview. Introduction Previous Work Hardware-Assisted Visibility Sorting Results Future Work Conclusion. Research Goal. Real-time volume rendering

E N D
Hardware-Assisted Visibility Sortingfor Tetrahedral Volume Rendering Steven Callahan Milan Ikits João Comba Cláudio Silva
Overview • Introduction • Previous Work • Hardware-Assisted Visibility Sorting • Results • Future Work • Conclusion
Research Goal • Real-time volume rendering • Scalable (machine performance) • Data of arbitrary size • Simple and robust implementations
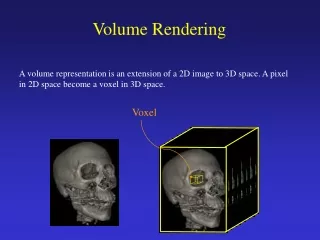
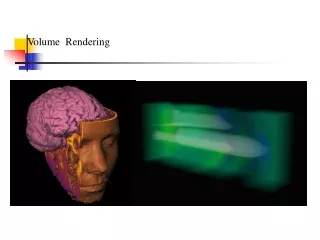
Volume Rendering Regular Irregular
Why Irregular Grids ? Unstructured grids are the preferred data type in scientific computations Level-Of-Detail (LOD) techniques intrinsically need unstructured grids El-Sana et al, Ben-Gurion
Optical Models Absorption plus emission Light s s
Compositing Front-to-back I1 I0 I2 1 2 0 I01 I2 2 01
Sampling: Triangle-Based Approach Class 1 (+, +, +, -) Class 2 (+, +, -, -) Projected Tetrahedra [Shirley-Tuchman 1990]
Sorting Application Object-Space Sorting i.e., let’s sort the geometry! Rasterization Image Space Display
Cell-Projection B 7 5 6 A 3 4 p 2 1 A < B p
Object-Space Sorting: Williams’ MPVO B < A A < C B < E C < E C < D E < F D < F Idea: Define ordering relations by looking at shared faces. D A C F B E Viewing direction
MPVO Limitations Missing relations!
XMPVO A < C B < D Idea: Using ray shooting queries to complement ordering relations. C D A B A < B Viewing direction
Sorting Application Object Space Rasterization Image-Space Sorting Display i.e., let’s sort the pixels!
Image-Space Sorting: A-Buffer • Idea: Keep a list of intersections for each pixel. [Carpenter 1984]
Cell-Projection With An A-Buffer Not sorted!
Cell-Projection With An A-Buffer Sorted!
A-Buffer Limitations 2 Number of Intersections: O(cn ) n x n pixels c cells • Problems • Time: sorting takes too long • Memory: storage too high
Sorting Application Object-Space Sorting Rasterization Image-Space Sorting Display
Approximate Object-Space Sorting 3 5 1 4 2
Approximate Object-Space Sorting 3 6 5 7 1 4 2
Approximate Object-Space Sorting 3 7 5 6 1 4 2 A Solution: Use an insertion-sort A-buffer!
Approximate Object-Space Sorting What about the space problem? 3 7 5 6 1 4 2 Use a conservative bound on the intersections
Hardware Assisted Visibility Sorting (HAVS) • Sort in image-space and object-space • Do an approximate object-space sorting of the cells on the CPU (i.e. sort by face centroid) • Complete the sort in image-space by using a fixed depth A-buffer (called a k-buffer) implemented on the GPU • Can handle non-convex meshes, has a low memory overhead, and requires minimal pre-processing of data
k-buffer • Fixed size A-buffer of depth k • Fragment stream sorter • Stores k entries for each pixel. Each entry consists of the fragment’s scalar value and its distance to the viewpoint • An incoming fragment replaces the entry that is closest to the eye (front-to-back compositing) • Given a sequence of fragments such that each fragment is within k positions from its position is sorted order, it will output the fragments in sorted order
k-buffer: Hardware Implementation r a b g g comp r comp b comp a comp v1 v2 d2 d1 v3 d4 d3 v4 d5 v6 v5 d6 • Use multiple render target capability of ATI graphics cards (ATI_draw_buffers in OpenGL) • Use P-buffer to accumulate color and opacity and three Aux buffers for the k-buffer entries P-buffer Aux 0 Aux 1 Aux 2
Details • Fix incorrect screen-space texture coordinates caused by perspective-correct interpolation Projecting vertices to find tex coords Projecting tex coords in shader Perspective interpolation
Details • Simultaneously reading and writing to a buffer is undefined when fragments are rasterized in parallel
Details • The buffers are initialized and flushed using k screen-aligned rectangles with negative scalar values • Handling non-convex objects requires the exterior faces to be tagged with a negative distance d and keeping track of when we are inside or outside of the mesh with the sign of the scalar value v
Details • Early ray termination reads accumulated opacity and kills fragment if it is over a given threshold. Early z-test is currently not available on ATI 9800 when using multiple rendering targets
Pre-Integrated Transfer Function • Previous Work • Volume density optical model • Williams and Max 1992 • Pre-integration on GPU • Roettger et al. 2000 • 5 s to update a 128x128x128 table • Incremental pre-integration on CPU • Wieler et al. 2003 • 1.5 s to update a 128x128x128 table
Pre-Integrated Transfer Function S S f b l • Williams and Max