Download

1 / 45
450 likes | 559 Views
Potential usefulness of a framework of 7 steps for prediction models. Ewout Steyerberg Professor of Medical Decision Making Dept of Public Health, Erasmus MC, Rotterdam, the Netherlands Oberwolfach, Jan 28, 2010. Erasmus MC – University Medical Center Rotterdam. Overview.

E N D
Potential usefulness of a framework of 7 steps for prediction models Ewout Steyerberg Professor of Medical Decision Making Dept of Public Health, Erasmus MC, Rotterdam, the Netherlands Oberwolfach, Jan 28, 2010
Overview • Background: “Oberwolfach in the mountains” • A framework to develop prediction models • Potential usefulness • Discussion: how to improve prediction research
Workshop «Statistical Issues in Prediction», personal aims • Meet and listen to other researchers • Go cross-country skiing • Sell book • Get back on track with work in ‘TO DO’ box
Presentation options • Theoretical challenges • Practical challenges
2. Methodological problems Missing values Optimal recoding and dichotomization Stepwise selection, relatively small data sets Presentation Validation
Potential solutions • Awareness and education • Scientific progress required • Translation to practice • Epidemiologists/clinicians interested in prediction modeling • Statisticians not interested in prediction modeling • Reporting guidelines • Not yet available • Study protocol registration • Possible, rare
http://www.clinicalpredictionmodels.org http://www.springer.com/978-0-387-77243-1
Aim: knowledge on predictors, or provide predictions? • Predictors (Prognostic factors) • Traditional (demographics, patient, disease related) • Modern (‘omics’, biomarkers, imaging) • Challenges: • Testing: independent effect, adjusted for confounders • Estimation: correct functional form • Predictions • Pragmatic combination of predictors • Essentially an estimation problem
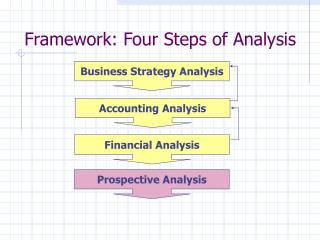
Prognostic modelling checklist:intended to assist in developing a valid prediction model
Usefulness of framework • Checklist for model building • SMART data, survival after cardiovascular event, 2008 • Critical assessment of model building • GUSTO-I model, Lee 1995
Aim: predictors or predictions? • Title: predictions vs text: prediction • Additional publication focuses at clinicians
1. Data inspection, specifically: missing values Among the array of clinical characteristics considered potential predictorvariables in the modeling analyses were occasional patients withmissing values. Although a full set of analyses was performedin patients with complete data for all the important predictorvariables (92% of the study patients), the subset of patientswith one or more missing predictor variables had a higher mortalityrate than the other patients, and excluding those patients couldlead to biased estimates of risk. To circumvent this, a methodfor simultaneous imputation and transformation of predictorvariables based on the concepts of maximum generalized varianceand canonical variables was used to estimate missing predictorvariables and allow analysis of all patients.3334 The iterativeimputation technique conceptually involved estimating a givenpredictor variable on the basis of multiple regression on (possibly)transformed values of all the other predictor variables. End-pointdata were not explicitly used in the imputation process. Thecomputations for these analyses were performed with S-PLUS statisticalsoftware (version 3.2 for UNIX32), using a modification ofan existing algorithm.3334 The imputation software is available electronicallyin the public domain.33
2. Coding of predictors • continuous predictors • linear and restricted cubic spline functions • truncation of values (for example for systolic blood pressure) • categorical variables • Detailed categorization for location of infarction: anterior (39%), inferior (58%), or other (3%) • Ordinality ignored for Killip class (I – IV) class III and class IV each contained only 1% of the patients
3. Model specification • Main effects: “.. which variables were most strongly related to short-term mortality”: • hypothesis testing rather than prediction question • Interactions: many tested, one included: Age*Killip • Linearity of predictors: • transformations chosen at univariate analysis were also used in multivariable analysis
4. Model estimation • Standard ML • No shrinkage / penalization • No external information
5. Model performance • Discrimination • AUC • Calibration: observed vs predicted • Graphically, including deciles (links to Hosmer-Lemeshow goodness of fit test) • Specific subgroups of patients
6. Model validation • 10-fold cross validation • 100 bootstrap samplesmodel refitted, tested on the original sample
7. Model presentation • Predictor effects: • Relative importance: Chi-square statistics • Relative effects: Odds ratios graphically • Predictions • Formula
Risk Model for 30-Day Mortality Probability of death within 30 days=1/[1+exp (-L)], where L=3.812+0.07624 age-0.03976 minimum (SBP, 120)+2.0796 [Killip class II]+3.6232 [Killip class III]+4.0392 [Killip class IV]-0.02113 heart rate+0.03936 (heart rate-50)+-0.5355 [inferior MI]-0.2598 [other MI location]+0.4115 [previous MI] -0.03972 height+0.0001835 (height-154.9)+^3-0.0008975 (height-165.1)+^3+0.001587 (height-172.0)+^3-0.001068 (height-177.3)+^3+0.0001943 (height-185.4)+^3 +0.09299 time to treatment-0.2190 [current smoker]-0.2129 [former smoker]+0.2497 [diabetes]-0.007379 weight+0.3524 [previous CABG]+0.2142 [treatment with SK and intravenous heparin]+0.1968 [treatment with SK and subcutaneous heparin]+0.1399 [treatment with combination TPA and SK plus intravenous heparin]+0.1645 [hx of hypertension]+0.3412 [hx of cerebrovascular disease]-0.02124 age · [Killip class II]-0.03494 age · [Killip class III]-0.03216 age · [Killip class IV]. Explanatory notes. 1. Brackets are interpreted as [c]=1 if the patient falls into category c, [c]=0 otherwise. 2. (x)+=x if x>0, (x)+=0 otherwise. 3. For systolic blood pressure (SBP), values >120 mm Hg are truncated at 120. 4. For time to treatment, values <2 hours are truncated at 2. 5. The measurement units for age are years; for blood pressure, millimeters of mercury; for heart rate, beats per minute; for height, centimeters; for time to treatment, hours; and for weight, kilograms. 6. "Other" MI location refers to posterior, lateral, or apical but not anterior or inferior. 7. CABG indicates coronary artery bypass grafting; SK, streptokinase; and hx, history.
Conclusion on usefulness of framework • GUSTO-I makes for an interesting case-study on • General modeling considerations • Illustration of 7 modeling steps • Internal vs external validity (early 1990s 2009?) • Debate possible on some choices • 1. Missing values: multiple imputation, including the outcome • 2. Coding: fractional polynomials? Lump categories? • 3. Selection: stepwise works because of large N • 4. Estimation: standard ML works because of large N; penalization? • 5. Performance: usefulness measures • 6. Validation: CV and bootstrap, not necessary because of large N? • 7. Presentation: Predictor effects: nice! Predictions: score chart / nomogram
Discussion on usefulness of framework • Checklist for model building • SMART data, survival after cardiovascular event, 2009 • Critical assessment of model building • GUSTO-I model, Lee 1995 • Basis for reporting checklist • Link with REMARK / STROBE / … • Basis for protocol registration • Link with requirements in other protocols?
Challenges in developing a valid prognostic model • Theoretical: biostatistical research • New analysis techniques, e.g. • Neural networks / Support vector machines / … • Fractional polynomials / splines for continuous predictors • Performance measures • Simulations: what makes sense as a strategy? • Applications: epidemiological and decision-analytic research • Subject matter knowledge • Clinical experts • Literature: review / meta-analysis • Balance research questions vs effective sample size • Incremental value new markers • Transportability and external validity • Clinical impact of using a model
Which performance measure when? Discrimination: if poor, usefulness unlikely, but >= 0 Calibration: if poor in new setting: Prediction model may harm rather than improve decision-making