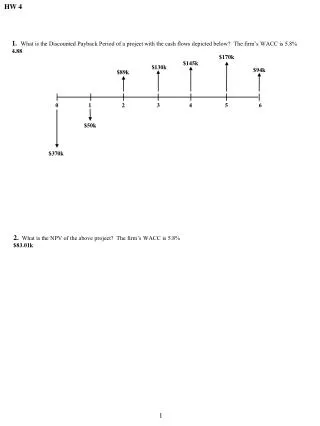
Download

1 / 17
170 likes | 235 Views
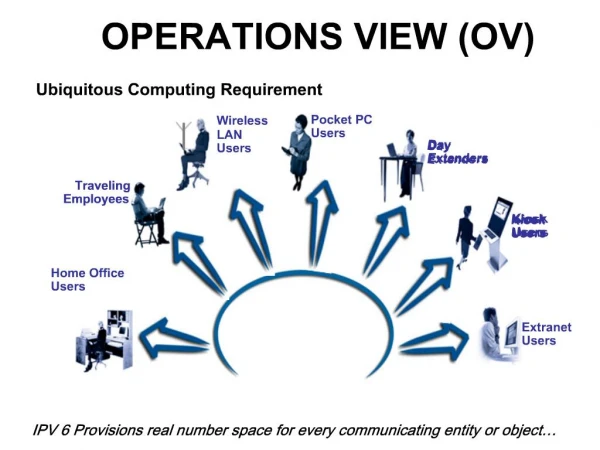
COMPUTING HW REQUIREMENT. Enzo Papandrea. GEOFIT - MTR. With Geofit measurements from a full orbit are simultaneously processed A Geofit where P, T and VMR of H 2 O and O 3 are simultaneously retrieved increase the computing time. TIME OF SIMULATIONS.

E N D
COMPUTING HW REQUIREMENT Enzo Papandrea COMPUTING - HW REQUIREMENTS
GEOFIT - MTR • With Geofit measurements from a full orbit are simultaneously processed • A Geofit where P, T and VMR of H2O and O3 are simultaneously retrieved increase the computing time COMPUTING - HW REQUIREMENTS
TIME OF SIMULATIONS Computing Time: sequential algorithm • We made some simulations with an Alphas. ES45, CPU 1 GHz • H2O TS = 1h 30m (TS = TSEQUENTIAL) • O3 TS = 4h 40m • PT TS = 9h 48m • MTR TS = 10h 30m …to reduce the time of the simulations we propose a parallel system COMPUTING - HW REQUIREMENTS
PARALLELIZATION • The first step will be to parallelize the loop that computes the forward model because: • It is the most time consuming part of the code. • The computation of the forward model for one sequence is independent from the computation of another sequence so that processors have to communicate data only at the beginning and at the end of the forward model. COMPUTING - HW REQUIREMENTS
PARALLEL TIME • Parallel time (TP) is the sequential time divided the number of CPUs • Example, for a system with 8 CPUs if the algorithm is completely parallel: TP= TS/8 = 12.5% of sequential time This is the best improvement we can reach with 8 CPUs COMPUTING - HW REQUIREMENTS
FORWARD MODEL PARALL. If we parallelize only the forward model we can do an evaluation of the simulations time with 8 CPUs: • TForward model (3 iterations): 45m Sum of the times to compute the forward model • TP = TForward model/#CPU = 45m/8 = 6m Time of parallelized code • T = TS + TP = (1h 30m - 45m) + 6m = 51m = 56% Total time (sum of the time of code remainedsequential and time of code parallelized) H2O COMPUTING - HW REQUIREMENTS
FW MODEL PARALL./1 • TForward model (2 it): 4h 10m, TP = 30m • T = 60m = 21% O3 • TForward model (2 it): 9h 33m, TP = 1h 12m • T = 1h 26m = 15% PT • TForward model (2 it): 10h 30m, TP = 1h 11m • T = 2h 11m = 20% MTR COMPUTING - HW REQUIREMENTS
M M P P P P P M NETWORK M P P P Shared Memory Local Memory M MEMORY CLASSIFICATION In order to use a parallel code we need an appropriate hardware witch can be classified by memory: Each processor can see only its memory: to exchange data we need a network Each processor (P) can see the whole memory (M) COMPUTING - HW REQUIREMENTS
OPEN-MP VS MPI With systems Local Memory is used MPI + call to libraries The header file mpif.h contains definitions of MPI constants, MPI types and functions • With systems Shared Memory is used OpenMP + compiler directives • Parallelism is not visible to the programmer (compiler responsible for parallelism) • Easy to do • Small improvements in performance • Parallelism is visible to the programmer • Difficult to do • Large improvements in performance COMPUTING - HW REQUIREMENTS
f90 –omp name_program setenv OMP_NUM_THREADS 2 f90 name_program OPEN-MP EXAMPLE If we compile in this way the compiler will treat the instructions beginning with !$ like comments PROGRAM Matrix IMPLICIT NONE INTEGER (KIND=4) :: i, j INTEGER (KIND=4), parameter :: n = 1000 INTEGER (KIND=4) :: a(n,n) !$ OMP PARALLEL DO & !$ PRIVATE(i,j) & !$ SHARED(a) DO j = 1, n DO i = 1, n a(i,j) = i + j ENDDO ENDDO !$ OMP END PARALLEL DO END If we compile with –omp flag the compiler will read these instructions COMPUTING - HW REQUIREMENTS
MPI EXAMPLE SENDand RECEIVE POINT TO POINT COMMUNICATION: MPI_SEND(buf, count, type, dest, tag, comm, ierr) MPI_RECV(buf, count, type, dest, tag, status, comm, ierr) BUF array of type type COUNT number of elements of buf to be sent TYPE MPI type of buf DEST rank of the destination process TAG number identifying the message COMM communicator of the sender and receiver STATUS array containing communication status IERR error code (if ierr = 0 no error occurs) COMPUTING - HW REQUIREMENTS
DATA DATA PROCESSES A0 A0 PROCESSES A0 A0 A0 MPI EXAMPLE/1 BROADCAST (ONE TO ALL COMMUNICATION): SAME DATA SENT FROM ROOT PROCESS TO ALL OTHERS IN THE COMMUNICATOR COMPUTING - HW REQUIREMENTS
0 3 2 1 4 5 7 6 MPI COMMINICATOR • IN MPI IT IS POSSIBLE TO DIVIDE THE TOTAL NUMBER OF PROCESSES INTO GROUPS, CALLED COMMUNICATORS • THE COMMUNICATOR THAT INCLUDES ALL PROCESSES IS CALLED MPI_COMM_WORLD COMPUTING - HW REQUIREMENTS
BROADCAST EXAMPLE P:1 after broadcast buffer is 24. P:3 after broadcast buffer is 24. P:4 after broadcast buffer is 24. P:0 after broadcast buffer is 24. P:5 after broadcast buffer is 24. P:6 after broadcast buffer is 24. P:7 after broadcast buffer is 24. P:2 after broadcast buffer is 24. PROGRAM Broadcast IMPLICIT NONE INCLUDE 'mpif.h' REAL (KIND=4) :: buffer INTEGER (KIND=4) :: err, rank, size CALL MPI_INIT(err) CALL MPI_COMM_RANK(MPI_WORLD_COMM, rank, err) CALL MPI_COMM_SIZE(MPI_WORLD_COMM, size, err) if(rank .eq. 5) buffer = 24. call MPI_BCAST(buffer, 1, MPI_REAL, 5, MPI_COMM_WORLD, err) print *, "P:", rank," after broadcast buffer is ", buffer CALL MPI_FINALIZE(err) END Proc. 5 sends its real variablebuffer to the processes in the comm. MPI_COMM_WORLD COMPUTING - HW REQUIREMENTS
DATA DATA PROCESSES A0 PROCESSES A0 B0 C0 D0 B0 A0 B0 C0 D0 A0 B0 C0 D0 C0 A0 B0 C0 D0 D0 DATA DATA PROCESSES PROCESSES A0 A0 A1 A2 A3 A1 A2 A3 OTHER COLLECTIVE COMMUNICATIONS ALLGATHER: DIFFERENT DATA SENT FROM DIFFERENT PROCESSES TO ALL OTHER IN THE COMMUNICATOR SCATTER: DIFFERENT DATA SENT FROM ROOT PROCESS TO ALL OTHER IN THE COMMUNICATOR GATHER: THE OPPOSITE OF SCATTER COMPUTING - HW REQUIREMENTS
LINUX CLUSTER • We have a linux cluster with 8 nodes, each node: • CPU Intel P4, 2.8Ghz, Front Side Bus 800Mhz • 2 Gbyte RAM 333Mhz • Hard Disk 40 Gbyte • 1 Switch LAN (Network) COMPUTING - HW REQUIREMENTS
CONCLUSIONS Linux cluster (Local memory): • Alphas. with 2 CPUs Shared Memory: • Cheap (~900,00 €/node) • Illimitated #CPU • In the past only arch. 32 bits 2(32-1) = 2 Gbyte = 2 · 230 bytes • Now architecture 64 bits! 2(64-1) = 8 Exabyte = 8 · 260 bytes • Very expensive (~200.000,00 €) • Limitated #CPU For readability and simplicity of the code we would like to use Fortran 90 COMPUTING - HW REQUIREMENTS