Download

1 / 17
170 likes | 276 Views
Failure Spread in Redundant UMTS Core Network. Author: Tuomas Erke, Helsinki University of Technology Supervisor: Timo Korhonen, Professor of Telecommunication Systems (S72) Tuomas.Erke@hut.fi 30.9.2003. Table of Contents. Background Terminology Problem Setting Used Methodology

E N D
Failure Spread in Redundant UMTS Core Network • Author: Tuomas Erke, Helsinki University of Technology • Supervisor: Timo Korhonen, Professor of Telecommunication Systems (S72) • Tuomas.Erke@hut.fi • 30.9.2003
Table of Contents • Background • Terminology • Problem Setting • Used Methodology • Results of the Study • Conclusions • Future Work
Background • Fixed networks have been built reliable, but the reliability of mobile networks have been given less attention • Enhanced services (e.g. telemedicine applications) and escalated competition between main market players over new subscribers is about to change this in the near future • In fixed networks, outages involving a large number of people must be reported. This may be extended to mobile networks in future also
Terminology (1/4) • Availability:A probability that the system will be functioning correctly at any given time • Failure: The impact of the faults and errors seen by user (SW program crash) • Fault Tree Analysis (FTA): A top-down method of analyzing system design and performance. Specifies a top event followed by identifying all of the associated elements in the system that can cause the top event to occur • Failure Spread:A failure occurs in some part(s) of the system, and propagates to other part(s) of the system • Fault Tolerance: A capability of the system to withstand and handle faults • Media Gateway (MGW): a network node in UMTS core network, which is used to interconnect networks • Redundancy:Availability of unit(s) and mechanisms for taking over failed unit(s) • Reliability:The capability of and item to carry out certain functionality in a certain period of time in certain conditions, or a probability that it will
Terminology (2/4) • Fault is connected to physical world (electronic components confront faults after a period of time), but it also includes mistakes made in design (incomplete system architecture) or implementation (programming mistakes) of the system • Error has an impact on information (error in data processing) • Failure is the impact of the faults and errors seen by user (SW program crash)
Terminology (3/4) • There are different types of failures: • Sudden, when failure cannot be predicted (nondeterministic software based problems) • Gradual, when failure can be predicted with prior examination (hardware wear-out increases probability of a failure over a period of time) • Partial when failure affects only some parts of the system (only one network node) • Complete when failure has an impact on the whole system (complete network) • Catastrophic when failure is both sudden and complete (power-system failure) • Degradation failures are gradual and partial (HW component wear-out over time)
Terminology (4/4) • Standby redundancy (triggered only when the other unit fails) • Parallel redundancy (frequently used in telecom networks)
Problem Setting (1/2) • Effect of failures in UMTS CN is studied in the thesis, and how redundancy mechanisms may be used in the network to increase availability and decrease the effect of failures • Area has not been widely studied before, but some work related to node failures exists • Network reliability has been studied, and this thesis compares results from the other studies and proposes solution alternatives
Problem Setting (2/2) • Failures occur in various parts of the system: • Node failure (HLR database failure results in unavailability of permanent user data if no redundant component and mechanism is available) • Protocol failures (wrong implementation or design), results in overload of network elements or signaling links, or faulty interaction between network nodes. For instance, wrong use of broadcasting messages, which leads to overload at the receiving side • HW failures (bus/circuitry failures/memory corruption, results in HW either malfunctioning or failing) • Recovery triggering mechnanisms (changeover procedure failures, DSP device manager failures or other triggering failures) • Load sharing algorithm (ineffective use of resources, exceeding the capacity of the system before taking action or wrong resource sharing on right network nodes) • HW/SW update procedure failures, which leads to faulty configurations and interworking of network elements • Wrong network configuration (often because of complex network design)
Used Methodology (1/3) • Failures are considered to occur on different levels:
Used Methodology (2/3) • A partly redundant example network is studied in the thesis • A tree format FTA (Fault-tree Analysis) is used for analyzing the causes of failures. FTA is mainly applied in SW reliability area • A literature study is performed to find mechanisms for achieving a higher level of system reliability
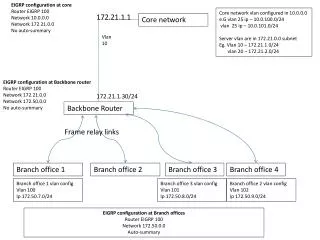
Used Methodology (3/3) • Example network configuration
Results of the Study (1/3) • The chain between fault detection, localization, analysis and recovery must be unbroken, otherwise failures cannot be recovered completely • Redundancy must be applied in different levels of the system for achieving high level of fault-tolerance (system is as strong as its weakest component) • SW fault-tolerance is increased by building distributed, reliable and scalable SW • The critical network nodes have to be duplicated, and restoration algorithms must be available
Results of the Study (2/3) • Emphasis on profound system testing (and especially testing of fault recovery mechanisms, load control and different failure scenarios) • SW based mechanisms include: • Distributed SW architecture (a failure of one component involves a smaller fraction of the system, so the loss of data and resources can be recovered in a better way). A fault can be isolated to a smaller area when the architecture is distributed • Multithreaded protocol stacks so that a failure of a process involves only part of the module capabilities, and the SW modules use dynamic checkpointing protocols for recovering from failure of peer entities • Optimization of the recovery process time to its minimum (only necessary part of the system is restarted: processor, board or node restart. This reduces the outage time) • A blackbox for SW failure analysis can be implemented inside SW components for later analysis
Results of the Study (3/3) • Dynamic routing and meshed network architecture is a recommendable solution (Advantage: high tolerance for the network failures and adaptability to different network configurations. Disadvantage: complicated design and maintenance of the network) • Reliability of the network is an optimization problem, but investing on redundant HW now can be used in future to increase the capacity of the system if needed • Multifunction devices, MSC in Pool, Multihoming and special algorithms may be utilized to increase reliability of the system
Conclusions • Different redundancy mechanisms were discussed in this thesis and existing algorithms were compared • Seems like the network design trend goes towards smaller, adaptable network nodes and architecture • The reliability of the system is best achieved by using multiple levels of redundancy • Failure spread depends on the availability and workability of the methods for ensuring the reliability of the system
Future Work • OPEX (OPerating EXpenses) and CAPEX (CApital EXpenses) calculations for network architecture solutions • Testing of failure recovery mechanisms and effect of failures using real network or a simulated environment • Multiple simultaneous failures have only been handled partly in this thesis. More research needs to be performed on the subject (e.g. for tolerating of geographical catastrophe involving large number of network nodes)