Download

1 / 12
120 likes | 351 Views
Solr Integration and Enhancements. Solr has a lot of extensive features. Todd Hatcher. What is Solr?. Solr offers advanced, optimized, scalable searching capabilities Communicate with Solr using XML, JSON and HTTP Includes a HTML admin interface Solr is built on top of Lucene

E N D
Solr Integration and Enhancements Solr has a lot of extensive features Todd Hatcher
What is Solr? • Solr offers advanced, optimized, scalable searching capabilities • Communicate with Solr using XML, JSON and HTTP • Includes a HTML admin interface • Solr is built on top of Lucene • Rich features of Lucene can be leveraged when using Solr • Solr is very configurable
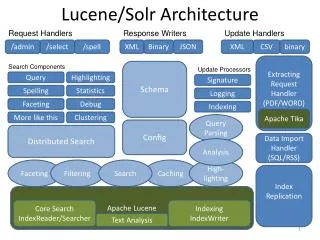
Integration with ColdFusion • Very little direct integration with ColdFusion • ColdFusion communicates with Solr using HTTP • Solr runs in its own JVM, does not share with ColdFusion • Using ColdFusion installation, Solr runs in a jetty servlet container on port 8983 (http://localhost:8983/solr) • Solr is exposed in production by default • Important files located C:\ColdFusion9\solr\multicore • Solr offers a lot more than what is available using cfindex cfcollection cfsearch
Solr • What is a core? – it’s like a verity collection (a searchable data group) • Single Core (one index) vs Multicore (multiple isolated configurations/schemas/indexes using same Solr instance) • C:\ColdFusion9\solr\multicore\solr.xml is the central file that points to locations of the Solr cores’ configuration and data (this what CF administrator reads/writes to when creating and using Solr collections) • You can put your Solr cores under you project directory and keep them in source control
[core]/conf/solrconfig.xml • Main configuration for solr core • <queryResponseWriter name=“json” /> determines the format of the results. ColdFusion uses xslt by default • You can return JSON, XML, python, ruby, php • Multiple query response writers can be configured, one can be set as default others can be specified by passing parameter wt:[name] (eg. wt:json) • cfsearch type of methods will not work if the response writer is not what ColdFusion is expecting
[core]/conf/schema.xml • Field Types maps custom types to the solr/lucene type • type solr.TextField allows for analyzers • Analyzers can be run at index time or query time • They allow for manipulations of the data (typically filtering) • The order in which filters are declared is the order processed • StopFilterFactory removes common words that do not help the search results • WordDelimiterFilterFactory can adds words like WiFi, Wi, Fi by splitting the original into subwords
[core]/conf/schema.xml cont. • EnglishPorterFilterFactory determines root word using word variations like -ing determines root word and adds to index • SynonymFilterFactory treats words as same • DoubleMetaphoneFilterFactory for phonetic logic (better than Soundex which Verity uses) • TextSpell/TextSpellPhrase feedback “did you mean” • <copyField source=“fieldName” dest=“d”/> destfieldtype can run different analyzers on source field and store result • wiki.apache.org/solr/AnalyzersTokenizersTokenFilters • Adobe adds quite a bit to the file to create fieldtypes to be compatible with what was in verity
[core]/conf/schema.xml cont. • Similar to creating a database table. Maps field names to types using <field /> • Gives you the ability to store additional data • Field can be indexed (searchable) • Field can be stored (referenced and returned with results) • Field can be required • <uniqueKey>[field name]</uniqueKey> • <solrQueryParse defaultOperator=“OR” />
Indexing • Data is sent using api - HTTP POST to Solr as XML/JSON/Binary • Commit is an intensive task. Do bulk adds first then call commit • <cfindex /> calls commit after each index (confirmed?) • Commit after each would noticeably increase index time • Efficient Process : add data (queue), commit, optimize
Search Syntax • field:term (*:* returns everything) • A score is generated at query time, the value itself doesn’t have any meaning, the scores are relevant only when relative to each other (a scale) • fq can filter query based on some supplied condition • wt is the return type of the results (xml,json, etc.) • qt is the request handler used to process the request (default is “standard”) • fl is the list of fields to return (field must be stored) • q is the query string • You can specify the start value and maxrows
DisMaxRequestHandler • Declared in solrconfig.xml • Allows simplified searching without strict syntax • Can be configured with default weighted parameters (which can be overriden) • Causes the q parameters to be parsed differently
Resources • Lucene In Action • http://wiki.apache.org/solr/ • http://cfadminsearcher.riaforge.org/ • http://cfsolrlib.riaforge.org/ • CF Solr Lib written by Shannon Hicks – Wrapper for Solr functionality