Download

1 / 23

E N D
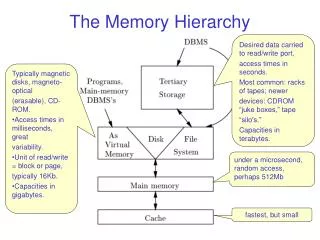
The Memory Hierarchy • Ideally one would desire an indefinitely large memory capacity such that any particular word would be immediately available … We are forced to recognize the possibility of constructing a hierarchy of memories, each of which has a greater capacity than the preceding but which is less quickly accessible.A.W. Burks, H.H. Goldstine, and J. von Neumann, 1946. • The same is true today. Access to main memory is too slow for modern microprocessors. On a 100Mhz (pretty slow) microprocessor an addition computation takes 10ns. A memory reference takes 60-110ns (using DRAM ) or 25ns using EDO DRAM. On a 500Mhz microprocessor an add takes 2ns, a memory reference still takes at least 25ns. • In order to bridge this gap we use a memory hierarchy whose main component is the cache (זכרוןהמטמון).
The Principle of Locality • The principle of locality (עקרון המקומיות) states that a program accesses a small part of its address space at any instant of time. • There are 2 types of locality: • Temporal locality (locality in time) - If an item is accessed it will be accessed again soon. • Spatial Locality (locality in space) - If an item was accessed, items close by will be accessed. • We use the principal of locality by implementing a memory hierarchy composed of multiple levels of memory with different sizes and speeds. SRAMs whichare faster(5-20ns) and moreexpensive(100-250$ per Mbyte)are used closer to the CPU while DRAMs (25-100ns, 3-8$) are used as main memory.
Hits and Misses • In the memory hierarchy an upper level (closer to the CPU) holds a subset (תת-קבוצה) of any lower level (farther away than the CPU). • Although the memory hierarchy can have multiple levels data is transferred between two adjacent (שכנים) levels. The minimum unit of data that can be present or not present is called a block or line. • If data requested by the CPU is in a block of the upper level, this is called a hit, if it isn't and the lower level has to be accessed it is called a miss. • The hit rate or hit ratio is the fraction of accesses found in the upper level. The miss rate (1 - hit rate) is the fraction of accesses not found in the upper level.
Hit Time and Miss Penalty • The hit time is the time needed to access the upper level, decide if the data is there and get it to the CPU. • The miss penalty is the time it takes to replace a block in the upper level with the block we need from the lower level and get the data to the CPU. • The hit time for upper levels is much faster than the hit time for lower levels. Thus if we have a high hit ratio at upper levels, we have a access time equal to that of the highest (and fastest) level with the size of the lowest (and slowest) level.
The Cache (זכרוןמטמון) • Cache: a safe place for hiding or string things. Webster's Dictionary • The level between main memory and CPU was called the cache in a 1968 paper describing the IBM 360/85 (1st commercial machine with cache). Nowadays all levels between main memory and CPU are called caches. • Lets look at a simple cache in whichthe processor accesses a word at atime and the block size is 1 word. • The processor requested the word Xn.It isn't in the cache which results ina cache miss. The word Xn is broughtfrom memory into the cache.
Direct Mapped Caches • How do we map memory location into cache locations? • The simplest way is to use the address. When each memory location can be mapped toonly one cache location we call thecache a direct mapped cache. • Almost all direct mapped cachesuse the mapping:(Block address)%(# of blocks in $) • In the case where the #of blocks is a power of 2then the lower log2bits of the address are usedto map the memory location into the cache.
Tags • If each cache location is mapped to several memory locations, how do we know whether the data in the cache corresponds to the data requested from memory? • We add a tag to each block. The tag contains the upper bits of the address not used to index the cache. • We also need a way to determine if the cache has valid information. At start up the cache will hold garbage. In order not to use it by mistake a valid bit is added to each block. If the bit isn't set there can't be a match.
Cache Size • Assuming a 32 bit address, a direct mapped cache of size 2n words with 1 word (4-byte) blocks will need a tag field of size 32 - (n+2) because 2 bits are the byte offset and n bits are used for the index. • The total number of bits in a direct mapped cache is 2n*(32 + (32-n-2)+1) = 2n*(63-n). • How many total bits are needed for a direct mapped cache with 64KB data in 1 word blocks?64KB = 16K words = 214 words = 214 blocks. Each block has 32 bits of data, 32-14-2 bits of tag, and a valid bit. Thus the total cache size is: 214*(32+(32-14-2)+1) = 214*49 = ~98KB. The size of the cache is 50% more than the size of the data it holds (for this configuration).
The DECStation 3100 • The DECStation 300 was a work station that used the MIPS R2000 processor and had 2 64KB caches, one for data and one for instructions. • A read is simple: • Send the address to the I-cache or D-cache. The address comes either from the PC (instruction) or from the ALU (data). • If the cache signals a hit the data is ready on the cache lines. If the cache signals a miss, the address is sent to main memory. When the data is brought from memory it is written into the cache.
Writes in a Cache • Write works differently. On a store instruction we write the data into the D-cache, now main memory has a different value from the cache. The cache and memory are inconsistent (לא עקביים). • The simple way to keep consistency is to write the data both to memory and to the cache. This is called write-through. • On a write miss there is no reason to read the block from memory. We can just overwrite the data in the cache block and change the tag. In fact we can do this for a write hit as well. Thus in the DECStation 300 a write works like this: • Index the cache using bits 15-2 of the address. • Write bits 31-16 of the address into the tag, write the data value and set the valid bit. • Write the word to main memory • The problem with write-through is that the writes to memory slow down the processor. The solution is to use a write-buffer.
Write-Back Caches • The data in the write-buffer is written to memory in parallel to the CPU continuing computation. This cuts down the penalty of the write-through scheme. • If the write buffer is full the CPU is stalled (מושהה) until data in the buffer is written to memory. In the DECStation 3000 the write buffer can hold 4 blocks. • The alternative to write-through is write-back. When a write occurs it is written into the cache only. Only when the block is replaced is the data written into main memory. Write-back caches are better when the CPU generates writes faster than the main memory can handle them. • The miss rates for 2 popular programs on the DECStation are:Program I miss rate D miss rate Combined miss rategcc 6.1% 2.1% 5.4%spice 1.2% 1.3% 1.2%
Taking Advantage of Spatial Locality • In order to take advantage of spatial locality we need a block size that is larger than 1 word. When a miss occurs we will fetch multiple adjacent (שכנים) words that we will probably use shortly. • The mapping of memory address to cache entry is the same, we just use less bits for the index and more for the offset. • Read misses are processed the same as for single word blocks. The writes are different. We can't just write the new data into the cache. Assume there are 2 addresses X and Y which map into cache block C. C contains Y. If the CPU writes into X it will overwrite the tag and write the value into C. Now C holds 1 word of X and 3 words of Y with the tag of X. So on a write miss we must read the block from memory. • Spatial locality improves the hit rate. Lets say the the byte addresses 16,24,20 are requested by the program. Reading the block that contains 16 will cause the addresses 16-31 to reside in the cache. Accesses to 24 and 20 are now hits instead of misses.
Miss Rate for 4 Word Block • The miss rate for gcc and spice is:Program Block Size I-cache D-cache Combinedgcc 1 6.1% 2.1% 5.4%gcc 4 2.0% 1.7% 1.9% spice 1 1.2% 1.3% 1.2%spice 4 0.3% 0.6% 0.4% • The miss rate rises if the block size is too large as not all the data in a block is used so space in the cache is wasted.
Memory System Support for Caches • Cache misses read data from main memory which is constructed from DRAMs. Although it is hard to reduce the latency (זמן גישה) to the first word it is possible to increase the bandwidth (רוחב סרט) from memory to cache. • Let's define access time for main memory: • 1 clock cycle to send the address • 15 clock cycles to read a word from DRAM • 1 clock cycle to send a word of data • For a cache block of 4 word and 1 word wide memory bank the miss penalty is: 1 + 4*15 + 4*1=65. • If we widen the memory and busses between memory to cachewe can reduce the miss penalty. For a 2 word wide memory the miss penalty is 1 + 2*15 + 2*1=33. For a 4 word wide memory the miss penalty is 1 + 1*15 + 1 = 17. But we pay the cost of a wide memory and wide busses.
Interleaved (שזור) Memory • The third option interleaves memory into multiple banks. Sequential addresses are in sequential banks. We can read 4 words at the same time, but send the data to the cache one word at a time. • When using interleaved memory the miss penalty is 1 + 1*15 + 4*1 = 20. Using banks is also helpful when using write-through caches, the write bandwidth is quadrupled (מוכפל פי 4).
Computing the Average Memory Access Time • The average memory access time is:(hit rate*hit time) + (miss rate*miss penalty) • Assuming the hit time is 1 cycle and the miss penalty is 17 cycles what is the average access time given a 98% hit rate:0.98*2 + 0.02*17 = 2.3 • Even for a high hit ratio the average access time is relatively high compared to R-type instructions. The solution is to introduce another level of cache between main memory and the CPU. • All modern microprocessors have an on-chip cache which is called the L1 cache and another larger off chip cache called the L2 cache. Assume a L1 hit time of 1, a L2 hit time of 5 and a L2 miss penalty of 17. Given a L1 hit rate of 98% and a L2 hit rate of 98% the average access time is:0.98*1 + 0.02(0.98*5 + 0.02*17) = 1.08 cycles
Cache Associativity • We have seen one mapping scheme: direct mapped, each memory location can be in only 1 cache location. • On the other extreme is a fully associative cache. Each memory location can be in any cache block. To find a block we must compare in parallel the tags of all blocks with the memory address. • The middle range is called set associative. A block can be mapped to a fixed number of locations. The tags in the set are compared in parallel to the memory address.
Set Associative Caches • We can look at all the mapping schemes as variations of set associative mapping. • Direct mapping is 1-way set associative and fully associative mapping is m-way set associative (m the number of blocks in the cache). • A cache with sets of 4 blocks to a set is called 4-way set associative. • The advantage of set associative caches is reduced miss rate, the disadvantage is increased hit time
Set Associative Diagram • The number of index bits is log2(n) where n is the number of sets in the cache, not blocks as in a direct mapped cache.
Replacing a Cache Block • I n a direct mapped cache there isn't a problem, there is only one block to replace. In a set associative cache we have to decide which block to replace. • The most commonly used scheme is least recently used (LRU), the block that has been unused the longest time is replaced. LRU is hard to implement for a set associativity higher than 2. • The replacement scheme used is an approximation (קירוב) of LRU called pseudo LRU. • Some caches use a random replacement scheme which isn't much worse than true LRU. • The miss rates for gcc when using set associative caches are (for spice the results are the same for all 3 sizes):Associativity I-cache D-cache Combined 1 2.0% 1.7% 1.9% 2 1.6% 1.4% 1.5% 2 1.6% 1.4% 1.5%
Miss Rates for Set Associative Caches • The block size is 32 bytes. The applications are the SPEC92 benchmarks.
The 3 Cs • Cache misses can be divided into 3 categories: • Compulsory misses: Misses that are caused because the block was never in the cache. These are also called cold-start misses. Increasing the block size reduces compulsory misses. Too large a block size can cause capacity misses and increases the miss penalty. • Capacity misses: Misses caused when the cache can't contain all the blocks needed during a program's execution. The block was in the cache, was replaced and now is needed again. Enlarging the cache reduces capacity misses. Enlarging to much raises the access time. • Conflict misses: Occur in direct mapped and set associative caches. Multiple blocks compete for the same set. Increasing associativity reduces conflict misses. But a too high associativity increases access time.