Download

1 / 27
290 likes | 442 Views
Vector Space Model. CS 652 Information Extraction and Integration. Introduction. Docs. Index Terms. doc. match. Ranking. Information Need. query. Introduction.

E N D
Vector Space Model CS 652 Information Extraction and Integration
Introduction Docs Index Terms doc match Ranking Information Need query
Introduction • A ranking is an ordering of the documents retrieved that (hopefully) reflects the relevance of the documents to the user query • A ranking is based on fundamental premises regarding the notion of relevance, such as: • common sets of index terms • sharing of weighted terms • likelihood of relevance • Eachset of premises leads to a distinct IR model
Algebraic Set Theoretic Generalized Vector (Space) Latent Semantic Index Neural Networks Structured Models Fuzzy Extended Boolean Non-Overlapping Lists Proximal Nodes Classic Models Probabilistic Boolean Vector (Space) Probabilistic Inference Network Belief Network Browsing Flat Structure Guided Hypertext IR Models U s e r T a s k Retrieval Browsing
Basic Concepts Each document is described by a set of representative keywords or index terms Index terms are document words (i.e. nouns), which have meaning by themselves for remembering the main themes of a document However, search engines assume that all words are index terms (full text representation)
Basic Concepts • Not all terms are equally useful for representing the document contents • The importance of the index terms is represented by weights associated to them • Let • kibe an index term • djbe a document • wij is a weight associated with (ki,dj ),which quantifies the importance of ki for describing the contents of dj
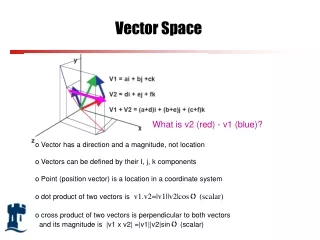
The Vector (Space) Model • Define: • wij > 0 whenever ki dj • wiq>= 0 associated with the pair (ki,q) • vec(dj ) = (w1j, w2j, ..., wtj),document vectorof dj • vec(q) = (w1q, w2q, ..., wtq),query vectorof q • The unitary vectors vec(di) and vec(qj) are assumed to be orthonormal (i.e., index terms are assumed to occur independently within the documents) • Queries and documents are represented as weighted vectors
The Vector (Space) Model j dj q i Sim(q,dj ) = cos() = [vec(dj) vec(q)] / |dj | |q| = [ti=1wij wiq ] / ti=1wij2 ti=1wiq2 where is the inner product operator & |q| is the length of q Since wij0and wiq 0, 1 sim(q, dj ) 0 A document is retrieved even if it matches the query terms only partially
The Vector (Space) Model • Sim(q, dj ) = [ti=1 wij wiq ] / |dj | |q| • How to compute the weights wijand wiq? • A good weight must take into account two effects: quantification of intra-document contents (similarity) • tf factor, the term frequency within a document quantification of inter-documents separation (dissi- milarity) • idf factor, the inverse document frequency • wij = tf(i, j) idf(i)
The Vector (Space) Model • Let, • N be the total number of documents in the collection • nibe the number of documents which containki • freq(i, j), theraw frequency of kiwithin dj • A normalizedtf factor is given by • f(i, j) = freq(i, j) / max(freq(l, j)), • where the maximum is computed over all terms which occur within the document dj • The inverse document frequency (idf)factor is • idf(i) = log (N / ni ) • the log is used to make the values of tf and idf comparable. It can also be interpreted as the amount of information associated with term ki.
The Vector (Space) Model • The best term-weighting schemes use weights which are give by • wij = f(i, j) log(N / ni) • the strategy is called a tf-idf weighting scheme • For the query term weights, a suggestion is • Wiq = (0.5 + [0.5 freq(i, q) / max(freq(l, q))]) log(N/ni) • The vector model with tf-idf weights is a good ranking strategy with general collections • The VSM is usually as good as the known ranking alternatives. It is also simple and fast to compute
The Vector (Space) Model • Advantages: • term-weighting improves quality of the answer set • partial matching allows retrieval of documents that approximate the query conditions • cosine ranking formula sorts documents according to degree of similarity to the query • A popular IR model because of its simplicity & speed • Disadvantages: • assumes mutuallyindependence of index terms (??); • not clear that this is bad though
Naïve Bayes Classifier CS 652 Information Extraction and Integration
Bayes Theorem The basic starting point for inference problems using probability theory as logic
Bayes Theorem .008 .992 .98 .02 .03 .97 P(+|cancer)P(cancer)=(.98).008=.0078 P(+|~cancer)P(~cancer)=(.03).992=.0298
Naïve Bayes Subtleties m-estimate of probability
Learning to Classify Text • Classify text into manually defined groups • Estimate probability of class membership • Rank by relevance • Discover grouping, relationships • Between texts • Between real-world entities mentioned in text
How to Improve • More training data • Better training data • Better text representation • Usual IR tricks (term weighting, etc.) • Manually construct good predictor features • Hand off hard cases to human being