Download

1 / 43
430 likes | 558 Views
Architecture and applications of the HEP multiprocessor computer system Burton J. Smith. Hayatsu Masakazu. 概要. HEP computer 商用の大規模科学並列計算機 MIMD architecture を採用 内容 ハードウェア、ソフトウェアの構造の紹介 プログラミングテクニックの議論. HEP コンピュータの構成 (1/2). MIMD architecture を採用した 大規模科学並列計算機

E N D
Architecture and applications of the HEP multiprocessor computer systemBurton J. Smith Hayatsu Masakazu
概要 • HEP computer • 商用の大規模科学並列計算機 • MIMD architecture を採用 • 内容 • ハードウェア、ソフトウェアの構造の紹介 • プログラミングテクニックの議論
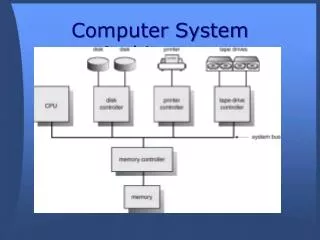
HEPコンピュータの構成(1/2) • MIMD architecture を採用した大規模科学並列計算機 • 複数のプロセッサが、パイプライン化された高速なパケットスイッチングネットワークで、共有データメモリとつながっている構造 • HEPの構成図(See Figure 1)
HEPコンピュータの構成(2/2) • 最大構成: プロセッサx16、データメモリモジュールx128、I/Oキャッシュモジュールx4 • 性能 • プロセッサ:10MIPS • スイッチのバンド幅:640Mbps(10 million 64 bit word per second) • データメモリモジュールのバンド幅:640Mbps • I/Oキャッシュ:256Mbpsのシーケンシャル・ランダムアクセスを維持できる
中身をちょいと詳しく • プロセッサとメモリ • スイッチ • I/O機構
プロセッサ • HEPプロセッサの内部構造(See Figure 2) • Process Status Word (PSW) • プログラムカウンタ、プロセスの状態情報を持つ • 制御ループ • キュー、インクリメンタ、パイプライン遅延からなる • PSWは制御ループの中を回る • データループ • レジスタメモリ、ファンクションユニットからなる • データはデータループの中を回る • 制御ループとデータループは8段にパイプライン化 (各段階100ns)
4種のメモリ • プログラムメモリ • プロセッサに固有、通常read-only • レジスタメモリ • プロセッサに固有 • 定数メモリ(レジスタメモリの一部?) • プロセッサに固有、管理者プロセスでのみ変更可 • データメモリ • プロセッサ間で共有、レジスタメモリとのデータの移動をStorage Function Unit (SFU) 操作で管理
ファンクションユニット • Scheduler(Storage) Function Unit (SFU) • ロード・ストア命令によるレジスタメモリとデータメモリ間のデータ転送を管理 • スイッチにデータメモリアドレス、リターンアドレス、データ(ストア命令のとき)を含むメッセージパケットを送る • 命令の実行が終わったプロセスを制御ループから取除き、応答パケットがスイッチから返るまで再挿入させない • 制御ループのキューと同様のキューを備え、メモリ参照命令の開始・終了時にプロセスは両者間を移動
制御命令 • 制御命令 • ロード・ストア、条件分岐やサブルーチン呼び出し(実行中PSWの更新) • プロセス生成・終了 • 一般ユーザ権限の場合、ユーザは小さなオーバーヘッドで並列性を制御できるようになる • 管理者権限の場合、ユーザはプロセスの管理やI/Oの実行をする管理者手続きが行える
同期機構(1/2) • レジスタメモリとデータメモリにアクセス状態を持たせる • データメモリのアクセス状態: full, empty • ロード命令はアドレスの場所が”full”になるまで待ち、読むと同時に”empty”を立てる。ストア命令はその逆 • レジスタメモリのアクセス状態:full, empty, reserved • 移動元が”full”で、移動先が”empty”のときに移動を行い、移動元を”empty”、(不可分性を保証するため)移動先のレジスタにデータが送られてくるまで”reserved”を立て、データがセットされたら”full”にする • “reserved”が立っているレジスタへの操作はできない
同期機構(2/2) • 命令実行失敗時 • レジスタのアクセス状態が原因の場合 • 単にキューに再挿入、プログラムカウンタは増加させない⇒ 次の順番が来たときに再実行 • データメモリのアクセス状態が原因の場合 • SFUキューに再挿入⇒ 次の順番が来たときに再要求
プロセスとタスク • 独立したプログラムに対するメモリ保護 • プログラムメモリのレジスタ、レジスタメモリ、データメモリの上限と下限をプロセスごとに決定 • タスク • 同じ保護領域をもつプロセスの集合 • プロセッサごとに最大7ユーザタスクと7管理者タスク • ユーザプロセスは同じタスク上にのみプロセス生成可 • 管理者プロセスはどのタスク上にもプロセスを生成可、どのタスク上のプロセスも終了可
中身をちょいと詳しく • プロセッサとメモリ • スイッチ • I/O機構
スイッチ(1/5) • 同期的な任意個のノードからなるパケットスイッチネットワーク • 各ノードはその隣接物(プロセッサ、データメモリモジュール、他のノード)と3つの全二重ポートで接続 • 3つのポートから100ns毎に3つのメッセージを受け取る • ポート毎に全部で3つのルーティングテーブルを持つ • 目的地のアドレスとパケット送信の推奨ポートのIDを含む
スイッチ(2/5) • ポートの衝突が起こった場合 • メッセージをキューにためるのではなく、全てポートから出力 • 各メッセージは優先度(初期値1)を持っており、メッセージが誤ったルートで送信される度に1増やされる⇒届いたメッセージを新しいメッセージより優先して再挿入できる
スイッチ(3/5) • ポートは全二重でつながっているため、オイラー回路(全てのポートをただ一度通るような回路)の存在が保証 • そのようなオイラー回路では最大優先度15となり、目的地のアドレスとは無関係に他のメッセージと衝突しないことが保証 • ルーティングテーブルのデータと同様、オイラー回路の情報も初期化時にノードにロードされる
スイッチ(4/5) • 各スイッチノードは届いたメッセージのパリティ、送信ルートを検査する • ポートやノードの故障、それによるプロセッサやメモリでのエラーはルーティングテーブルを単に構成要素が減ったものとして再プログラムするだけで取り除くことができる • システムが分断されるのを避けるには、どの2ノード間も少なくとも2つの分離したパスが存在しなくてはならない • プロセッサやメモリとスイッチの間をつないでいるポートがどの方向も故障すると、プロセッサやメモリ自身が故障したのと同じになる
スイッチ(5/5) • スイッチ中のメッセージを伝播する際の遅延は、各ポートを通るごとに50ns • パイプラインの速さは100nsごとに各ポートにつき1メッセージ
中身をちょいと詳しく • プロセッサとメモリ • スイッチ • I/O機構
I/Oシステム • High Speed I/O Subsystem (HSIOS) • 最大4つのI/Oキャッシュを含む • I/Oキャッシュはスイッチと32個のI/Oチャンネルとの間のバッファの役割 • 各I/Oチャンネルは最大20Mbpsで同時に動作可
I/O制御 • I/OチャンネルはI/O control processor (IOCP) によって制御 • IOCPはI/O操作が完了したとき、管理者権限プロセスからのメッセージを受けたとき、割り込まれる • IOCPの役割は管理者のチャンネルへのI/Oリクエストのスケジューリング • I/Oスイッチに届いたメッセージはキューに入れられ、その先頭まで来たら実行される • ストア命令は数ミリ秒かかるが、制御ループに多くのプロセスが残っているならば、プロセッサのパフォーマンスは影響を受けない
ファイル • ファイル • ヘッダページと0個以上のデータページからなる • ヘッダはファイルが開かれている間キャッシュに蓄えられる • ヘッダは、データ自身または、データページのディスク中の場所を表すポインタと、キャッシュフレームの場所を保管 • 多重にファイルが開かれないよう、キャッシュされたページに参照カウンタがつく • ページはページの参照カウンタ、ヘッダはファイルの参照カウンタが0になったら、キャッシュから消される
ソフトウェア • Fortranの拡張 • プロセスの生成・終了 • 非同期変数
Fortranの拡張(1/2) • 明示的に並列アルゴリズムを記述するためにHEP Fortran に2種類の拡張を行った • 最初の拡張は、並列プロセス生成を許した • CREATE文は文法的にはCALLと同様で、サブルーチンを生成元と並列に走らせる • RESUME文は文法的にはRETURNと同様で、呼び出し元に返る
Fortranの拡張(2/2) • 2つ目の拡張はハードウェアによって提供されるアクセス状態をプログラマが使えるようにしたもの • “$”で始まる変数:「非同期変数」 • その変数の評価はその場所が”full”になるまで待たれ、フェッチするときに”empty”を立てる • 変数への代入は逆 • PURGE文は無条件にアクセス状態を”empty”にする • HEP Fortranは再入可能なコードを生成し、レジスタとデータメモリ中のローカル変数を必要に応じて動的に確保する
HEPプログラミング • 並列プログラムの手法について少々
HEP上での並列プログラミング • HEPのハードウェア・ソフトウェアは並列アルゴリズムの実現手段であるパイプライン化にピッタリ • アクセス状態”full”と”empty”はsingle-wordのキューを用いたプロセス間メッセージ通信のメカニズムと見ることができる • クリティカルセクションを、単にプロセスに 入るとき:あるメモリ領域を空にする 出るとき:そのメモリ領域を埋めるということをさせることで実現できる
プログラムの例(1/2) • 並列プログラムでよく、X = X op Y (ここで、opは可換で結合可能で、YはXに依存しない)を行うものがある • 例)$NPを用いたもの(See Figure 4)、ベクトルの内積計算等 • これを単に$X = $X op Yと書く時の問題 • 全てのプロセスが$Xにアクセスする際に競合を起こす • 最終的な$Xの値は様々なプロセスが独立な方法で利用可能でなければならない
プログラムの例(2/2) • この問題を避ける一つの方法(see figure. 5) • 各P個のプロセスに対しlog Pの場所が必要となる • この方法は同時にXの最後の値を計算し、それをPプロセスにO(log P)の時間でブロードキャストする • 適切な伝達ネットワークで実現される • ここで、IからKを計算する関数は常に全単射であり、$Aの要素間で衝突は起こらない(唯一つのプロセスが$Aのある要素を埋めたり空にしたりする)
その他の例 • 他の重要なプログラミングテクニック:プロセス自身にそのスケジュールをさせること • 自己スケジューリングは各プロセスに動的に自分が終わったら次の計算をするようにできる • 実行しようとしている独立な計算ステップが利用可能なプロセス数を大幅に上回るとき • 各ステップの実行時間が大きくばらつくとき • 依存と優先度を持つ複雑な場合、多くの計算を自己スケジューリングで行える • Doループの原版(figure 6)と自己スケジューリング版(figure 7)
まとめ • HEP computerは独創的でとても柔軟な構造 • モジュール構造はMIMDコンピュータにとって独創的 • 全てのメモリ領域での自然な同期機構により、並列アルゴリズムの開発の自由度が上がる • ユーザが動的にプロセスを制御できるメカニズムは多くの並列性を得るのにとても有利
Performance Measurements on HEP – A Pipelined MIMD ComputerHarry F. Jordan Hayatsu Masakazu
概要 • HEPコンピュータのパイプラインに注目したパフォーマンス測定 • 内容 • HEPコンピュータアーキテクチャの説明 • 2つの並列ベンチマークの結果の解析
アーキテクチャの概略 • (詳しい中身は省略) • メモリアクセスに2つの方法 • ローカルメモリしか触らない操作 パイプライン長さ: 8 step (1step=100ns) • 共有データメモリを触る操作 パイプライン長さ: 20~30 step (1step=100ns) • このパイプラインの長さによる影響を見る!!
パフォーマンス測定 • プロセッサ1個で測定 • 並列性を得る方法は大きく分けて2つ • 独立したジョブを複数走らせる • アルゴリズムを並列化して1つのジョブの実行時間を減らす • 2つの並列ベンチマークのスピードアップを解析 • 多くの独立した計算 • 1つの再帰のある計算
ベンチマーク1 • 正整数を引数にするガンマ関数の計算 • 階乗計算を用いる場合 • Simpson の積分ルールを用いる場合 • ほとんどの計算は積分を含んでおり、その結果は0~2MM(通常 MM=50)の間隔で繰越される • 同期のオーバーヘッドは非常に小さい
ベンチマーク1の結果の評価(1/3) • 実行時間対プロセス数をFigure 3に示した • 特徴 • Npが小さい時には実行時間が1/Npで減少⇒パイプラインの効果 • Np=10, 13, 14, 25, 50 で不連続⇒MM=50なので、プロセスに均等に仕事が渡るとき実行時間が減る • ローカルメモリを使うか否かの差⇒ローカル800ns, スイッチ2μsの差があるが、Npが大きくなるとその影響が小さくなる(30%→5%)⇒プロセス数が大きくなるとパイプラインの長さはパフォーマンスにあまり影響を与えない
ベンチマーク1の結果の評価(2/3) • プロセス数の増加による効果を見るために effective parallelism (EFP) を導入 • 定性的には、他から何の干渉も受けずに全プロセスLが走る場合EFP(L)=L • 定量的には
ベンチマーク1の結果の評価(3/3) • EFP(L)をFigure 4 に示した • ローカルメモリを使う場合は、18台を超えると 一定になる⇒パイプライン使用の限度が関係している • ローカルメモリを使わなかった場合は、18台以降も増加⇒全てのメモリアクセスをスイッチを通して行うことで、パイプラインの実効長が長くなる⇒パイプラインが一杯になるまでもっと多くのプロセスが必要になった
ベンチマーク2 • 再帰計算が足し算の前半に出てくる計算 • forI:=2 toNdoV(I):=V(I)+V(I-1) • N=16の時の並列アルゴリズムを図示したものをFigure 5に、擬似コードをFigure 6に示す
ベンチマーク2の結果の評価(1/2) • 1要素あたりの実行時間対ベクタの長さをFigure 7に示した • 特徴 • 並列アルゴリズムは最初はフォークする際のオーバーヘッドが大きいけれど、Nが大きくなるにつれその影響は無視できるようになる • 不連続な点がある⇒アルゴリズムの性質上、2の累乗のところで変わる
ベンチマーク2の結果の評価(1/2) • スピードアップ • Nが十分大きいとき、並列版は逐次版の4倍の速さ • 遅くなる要因 • 足し算の回数の増加 • 同期にかかる遅延 • その他アルゴリズムが複雑になるにつれ現れる様々な物 • 遅くなる要因と相殺、さらにそれを上回る並列化の影響
まとめ • 2つの計算(そのままで並列実行に向くもの、向かないもの)について議論した • 両者とも、並列HEP計算機の上で非常によい性能を示した • パイプラインを用いれば、より広いアルゴリズム(あまり並列性がないものでも)の性能の向上が見込めるのではないだろうか