Download
1 / 13
260 likes | 552 Views
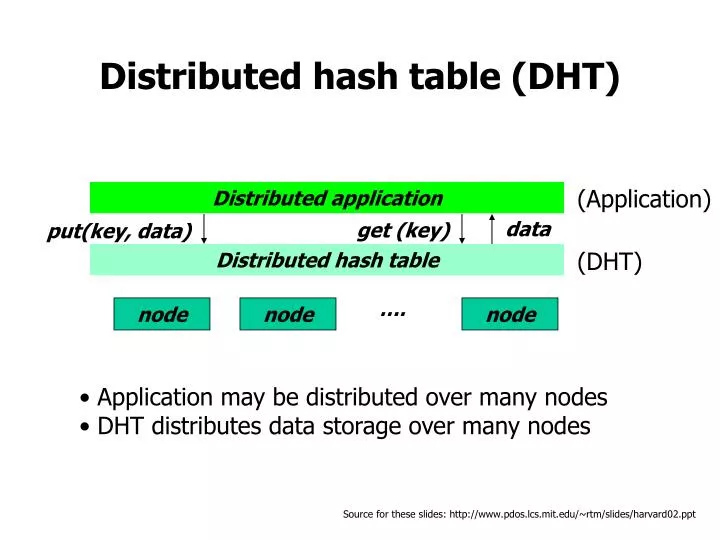
…. node. node. node. Distributed hash table (DHT). (Application). Distributed application. data. get (key). put(key, data). (DHT). Distributed hash table. Application may be distributed over many nodes DHT distributes data storage over many nodes.

E N D
…. node node node Distributed hash table (DHT) (Application) Distributed application data get (key) put(key, data) (DHT) Distributed hash table • Application may be distributed over many nodes • DHT distributes data storage over many nodes Source for these slides: http://www.pdos.lcs.mit.edu/~rtm/slides/harvard02.ppt
DHT interface • Interface: • Put(key, value) and get(key) value • API supports a wide range of applications • DHT imposes no structure/meaning on keys • Good infrastructure: many applications can share one DHT service (much as applications share the Internet) • Pools resources from many participants • Efficient due to statistical multiplexing • Fault-tolerant due to geographic distribution
The lookup problem N2 N1 N3 Put (Key=“title” Value=file data…) Internet ? Client Publisher Get(key=“title”) N4 N6 N5
Centralized lookup (Napster) N2 N1 SetLoc(“title”, N4) N3 Client DB N4 Publisher@ Lookup(“title”) Key=“title” Value=file data… N8 N9 N7 N6 Simple, but O(N) state and a single point of failure
Flooded queries (Gnutella) N2 N1 Lookup(“title”) N3 Client N4 Publisher@ Key=“title” Value=file data… N6 N8 N7 N9 Robust, but worst case O(N) messages per lookup
Routed queries (Chord, CAN, Tapestry, Pastry) N2 N1 N3 Client N4 Lookup(“title”) Publisher Key=“title” Value=file data… N6 N8 N7 N9
Lookup algorithm properties • Interface: lookup(key) IP address • Efficient: O(log N) messages per lookup • N is the total number of servers • Scalable: O(log N) state per node • Robust: survives massive failures
Chord IDs • Key identifier = SHA-1(key) • Node identifier = SHA-1(IP address) • SHA-1 distributes both uniformly • How to map key IDs to node IDs?
Chord Hashes a Key to its Successor Key ID Node ID N10 K5, K10 K100 N100 Circular ID Space N32 K11, K30 K65, K70 N80 N60 K33, K40, K52 • Successor: node with next highest ID
Basic Lookup N5 N10 N110 “Where is key 50?” N20 N99 “Key 50 is At N60” N32 N40 N80 N60 • Lookups find the ID’s predecessor • Correct if successors are correct
Successor Lists Ensure Robust Lookup 10, 20, 32 N5 20, 32, 40 N10 5, 10, 20 N110 32, 40, 60 N20 110, 5, 10 N99 40, 60, 80 N32 N40 60, 80, 99 99, 110, 5 N80 N60 80, 99, 110 • Each node remembers r successors • Lookup can skip over dead nodes to find blocks
Chord “Finger Table” Accelerates Lookups ½ ¼ 1/8 1/16 1/32 1/64 1/128 N80
Chord lookups take O(log N) hops N5 N10 N110 K19 N20 N99 N32 Lookup(K19) N80 N60