Download
1 / 20
200 likes | 295 Views
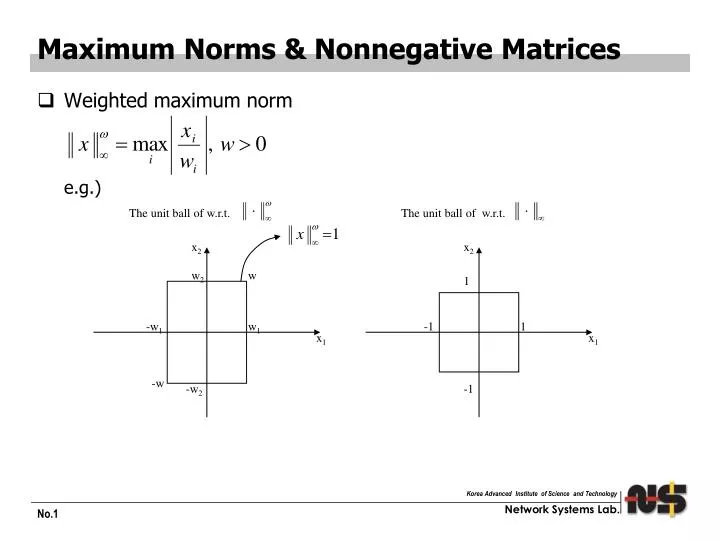
Maximum Norms & Nonnegative Matrices. Weighted maximum norm e.g.). The unit ball of w.r.t. The unit ball of w.r.t. x 2. x 2. w 2. w. 1. -w 1. w 1. -1. 1. x 1. x 1. -w. -w 2. -1. The induced matrix norm Proposition 6.2 (c) (b) If M ≥ 0, then

E N D
Maximum Norms & Nonnegative Matrices • Weighted maximum norm e.g.) The unitball of w.r.t. The unit ball of w.r.t. x2 x2 w2 w 1 -w1 w1 -1 1 x1 x1 -w -w2 -1
The induced matrix norm • Proposition 6.2 (c) (b) If M ≥ 0, then (d) Let M ≥ 0. Then, for any λ > 0, iff (e) (f) If (a) M ≥ 0 iff M maps nonnegative vectors into nonnegative vectors. x2 λw M ≥ 0 Mw w x1 -w -Mw -λw
1 2 • n x n matrix M to Graph G = (N,A) • N = {1, …… , n} • A = {(i,j) | i≠j & mij ≠ 0} • Definition 6.1 An n x n matrix M (n≥2) is called irreducible, if for every i,j N, a positive path in the graph G. e.g.)
Proposition 6.5 (Brouwer Fixed Point Theorem) Consider the unit simplex e.g.) If f: S S is a continuous fct. , then some w S such that f(w)=w. 1 S Unit Simplex 1
Proposition 6.6 (Perron-Frobenious Theorem) Let M ≥ 0. • If M is irreducible, then ρ(M) is an eigenvalue of M and some ω > 0 such that Mω = ρ(M)ω. Furthermore, such a ω is unique within a scalar multiple, i.e., if some v satisfies Mv = ρ(M)v, then v=αω. Finally, . (b)ρ(M) is an eigenvalue of M & there exists some ω≥0, ω≠0 such that Mω = ρ(M)ω. (c) For every ε > 0, there exists ω > 0 such that Proof) by yourself
e.g.) 1 2
Corollaries • Corollary 6.1 • Let . The followings are equivalent : • Corollary 6.2 • Given any square matrix M, there exists some such that iff • Corollary 6.3 • Given any square matrix M,
Convergence analysis using maximum norms • Def 6.2 • A square matrix A with entries is (row) diagonally dominant if • Prop 6.7 • If A is row diagonally dominant, then the Jacobi method for solving converges. proof) For , Therefore , for each i Therefore, Q.E.D
Prop. 6.8 Consider on nxn matrix associated to an iteration x: = Mx + b. Let be the corresponding Gauss-Seidel iteration matrix , that is , the iteration matrix obtained if the components in the original iteration are updated one at a time. Suppose that . Then . Proof) Assume that Let us fix some such that By prop 6.6(c) & prop 6.2(b) such that Therefore, (by Prop. 6.2 (d)) Equivalently for all i , - (*) Consider now some such that and let (Note that is not necessarily nonnegative)
We will prove by induction on i that Assuming that for Therefore, for every satisfying This implies that Q.E.D. • Prop. 6.8 implies that if
Prop. 6.9 (Stein-Rosenberg Theorems) • Consider where for and (This implies that the Jacobi iteration matrix is given by and for . That is ) (a) If , then restatement of Prop. 6.8 (b) If , then Proof) by yourself.
Prop. 6.8 implies that for nonnegative iteration matrices, if a Jacobi algorithm converges, then the corresponding Gauss-Seidel iteration also converges, and its convergence rate is no worse than that of the Jacobi algorithm. • Notice that the proofs of Prop. 6.8 and Prop. 6.9 remain valid when different updating orders of the components are considered. Nonnegative matrices possess some intrinsic robustness w.r.t. the order of updates! Key to asynchronous algorithms
Convergence Analysis Using Quadratic Cost Function • Consider where is a symmetric positive definite matrix. • Solve ( has a unique solution since is invertible) Find satisfying Define a cost fct. F is a strictly convex fct. ( is positive definite and by Prop. A.40 (d) ) minimizes iff , i.e. ,
Assume that is a symmetric positive definite matrix. • Def. A.11 A nxn square matrix is called positive definite if is real and for all , . It is called nonnegative definite if it is real and for all . • Prop. A.26 (a) For any real matrix , the matrix is symmetric and nonnegative definite. It is positive definite if and only if is nonsingular. (b) A square symmetric real matrix is nonnegative definite (positive definite) iff all of its eigenvalues are nonnegative (positive). (c) The inverse of a symmetric positive definite matrix is symmetric and positive definite.
The meaning of Gauss-Seidel method (&SOR) in term of cost fct. F. can be viewed as a coordinate descent method minimizing
Prop. 6.10 Let A be symmetric and positive definite, and let x* be the solution of Ax=b. (a) If , then the sequence {x(t)} generated by the SOR algorithm converges to x*. (b) If , then for every choice of x(0) different than x*, the sequence generated by the SOR algorithm does not converge to x*. • Prop. 6.11 If A is symmetric and positive definite and if is sufficiently small, then the JOR and Richardson’s algorithms converge to the solution of Ax=b. • Both are a special case of Prop. 2.1 and Prop. 2.2 of Section 3.2.
Conjugate Gradient Method • To accelerate the speed of convergence of the classical iterative methods • Consider - Assume that A is nxn symmetric and positive definite - If A is not, consider the equivalent problem . Then, is symmetric and positive definite (by Prop. A.26 (a) ) • For convenience, assume , i.e.,
The cost function • An iteration of the method has the general form is a direction of update is a scalar step size defined by the line minimization • Let
Steepest Descent Method • Conjugate Gradient method • Prop. 7.2. • For the conjugate gradient method, the following hold: The algorithm terminates after at most n steps; that is, there exists some t n such that g(t)=0 and x(t)=0.
Geometric interpretation • {s(t)} is mutually A-conjugate, that is, s(t)’As(r) = 0 if t r If A=I, s(t)’s(r) =0, if t r A=I A: Positive definite & symmetric X(0) X(0) Steepest Descent Conjugate gradient
















