Download
1 / 1
10 likes | 107 Views
Optimizing Average Precision using Weakly Supervised Data. Aseem Behl 1 , C.V. Jawahar 1 and M. Pawan Kumar 2 1 IIIT Hyderabad, India, 2 Ecole Centrale Paris & INRIA Saclay, France. Aim. Latent Structural SVM ( LSSVM ). Optimization. CCCP Algorithm – Guarantees local optimum solution.

E N D
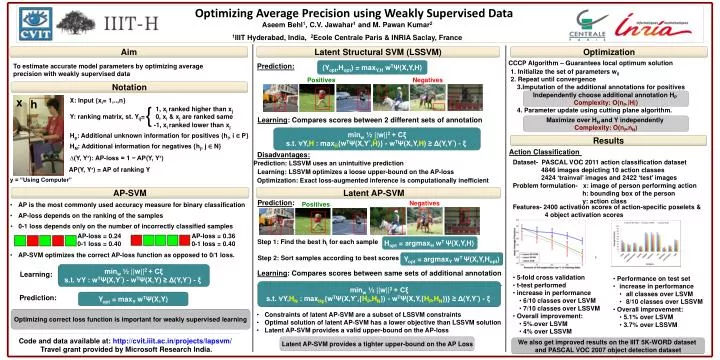
Optimizing Average Precision using Weakly Supervised Data Aseem Behl1, C.V. Jawahar1 and M. Pawan Kumar2 1IIIT Hyderabad, India, 2Ecole Centrale Paris & INRIA Saclay, France Aim Latent Structural SVM (LSSVM) Optimization CCCP Algorithm – Guarantees local optimum solution (Yopt,Hopt) = maxY,HwTΨ(X,Y,H) Prediction: To estimate accurate model parameters by optimizing average precision with weakly supervised data • Initialize the set of parameters w0 • Repeat until convergence • 3.Imputation of the additional annotations for positives • 4. Parameter update using cutting plane algorithm. Positives Negatives Notation Independently choose additional annotation HP Complexity: O(nP.|H|) x X: Input {xi= 1,..,n} h { 1, xi ranked higher than xjY: ranking matrix, st. Yij= 0, xi & xj are ranked same -1, xi ranked lower than xj Learning: Compares scores between 2 different sets of annotation Maximize over HN and Y independently Complexity: O(nP.nN) minw ½ ||w||2 + Cξs.t. ∀Y,H: maxĤ{wTΨ(X,Y*,Ĥ)} - wTΨ(X,Y,H) ≥ Δ(Y,Y*) - ξ Hp: Additional unknown information for positives {hi, i ∈ P} Results HN: Additional information for negatives {hj, j ∈ N} Action Classification Disadvantages: ∆(Y, Y∗): AP-loss = 1 − AP(Y, Y∗) Dataset- PASCAL VOC 2011 action classification dataset 4846 images depicting 10 action classes 2424 ‘trainval’ images and 2422 ‘test’ images Prediction: LSSVM uses an unintuitive prediction AP(Y, Y∗) = AP of ranking Y • Learning: LSSVM optimizes a loose upper-bound on the AP-loss y = “Using Computer” Optimization: Exact loss-augmented inference is computationally inefficient Problem formulation- x: image of person performing action h: bounding box of the person y: action class AP-SVM Latent AP-SVM Prediction: Negatives Positives • AP is the most commonly used accuracy measure for binary classification Features-2400 activation scores of action-specific poselets & 4 object activation scores • AP-loss depends on the ranking of the samples • 0-1 loss depends only on the number of incorrectly classified samples AP-loss = 0.240-1 loss = 0.40 AP-loss = 0.360-1 loss = 0.40 Hopt = argmaxHwT Ψ(X,Y,H) • Step 1: Find the best hi for each sample • Step 2: Sort samples according to best scores • AP-SVM optimizes the correct AP-loss function as opposed to 0/1 loss. • Yopt = argmaxYwT Ψ(X,Y,Hopt) C minw ½ ||w||2 + Cξs.t. ∀Y: wTΨ(X,Y*) - wTΨ(X,Y) ≥ Δ(Y,Y*) - ξ Learning: Compares scores between same sets of additional annotation Learning: • 5-fold cross validation • t-test performed • increase in performance • 6/10 classes over LSVM • 7/10 classes over LSSVM • Overall improvement: • 5% over LSVM • 4% over LSSVM • Performance on testset • increase in performance • all classes over LSVM • 8/10 classes over LSSVM • Overall improvement: • 5.1% over LSVM • 3.7% over LSSVM minw ½ ||w||2 + Cξs.t. ∀Y,HN: maxHp{wTΨ(X,Y*,{HP,HN}) - wTΨ(X,Y,{HP,HN})} ≥ Δ(Y,Y*) - ξ Yopt= maxYwTΨ(X,Y) Prediction: Optimizing correct loss function is important for weakly supervised learning • Constraints of latent AP-SVM are a subset of LSSVM constraints • Optimal solution of latent AP-SVM has a lower objective than LSSVM solution • Latent AP-SVM provides a valid upper-bound on the AP-loss C Code and data available at: http://cvit.iiit.ac.in/projects/lapsvm/ Travel grant provided by Microsoft Research India. Latent AP-SVM provides a tighter upper-bound on the AP Loss We also get improved results on the IIIT 5K-WORD dataset and PASCAL VOC 2007 object detection dataset