Download

1 / 24
240 likes | 520 Views
Genome Annotation. Now that you’ve assembled your genome, what is next? GENOME ANNOTATION What is that? Why is it important? How do you do it?. Challenges to Genome Annotation ?. Finding genes involves computational methods as well as experimental validation

E N D
Now that you’ve assembled your genome, what is next? • GENOME ANNOTATION • What is that? • Why is it important? • How do you do it?
Challenges to Genome Annotation? • Finding genes involves computational methods as well as experimental validation • Computational methods are often inadequate, and often generate erroneous ‘gene’ (false positive) sequences which: • Are missing exons • Have incorrect exons • Over predict genes • Where the 5’ and 3’ UTR are missing
What kinds of things are we looking to annotate? • CDS - coding sequences • mRNA • Alternative RNA • Promoter and Poly-A Signal • Pseudogenes • ncRNA
Pseudogenes • Could be as high as 20-30% of all Genomic sequence predictions could be pseudogene • Non-functional copy of a gene • Processed pseudogene • Retro-transposon derived • No 5’ promoters • No introns • Often includes polyA tail • Non-processed pseudogene • Gene duplication derived • Both include events that make the gene non-funtional • Frameshift • Stop codons • We assume pseudogenes have no function, but we really don’t know!
Noncoding RNA (ncRNA) • ncRNA represent 98% of all transcripts in a mammalian cell • ncRNA have not been taken into account in gene counts • cDNA • ORF computational prediction • Comparative genomics looking at ORF • ncRNA can be: • Structural • Catalytic • Regulatory • tRNA – transfer RNA: involved in translation • rRNA – ribosomal RNA: structural component of ribosome, where translation takes place • snoRNA – small nucleolar RNA: functional/catalytic in RNA maturation • Antisense RNA: gene regulation/silencing?
Covariance model searches are extremely compute intensive. A small model (like tRNA) can search a sequence database at a rate of around 300 bases/sec. The compute time scales roughly to the 4th power of the length of the RNA, so larger models quickly become infeasible without significant compute resources.
BLAST • Seeks high-scoring segment pairs (HSP) • pair of sequences that can be aligned without gaps • when aligned, have maximal aggregate score (score cannot be improved by extension or trimming) • score must be above score threshold S • Public Search engines • WWW search formhttp://www.ncbi.nlm.nih.gov/BLAST • Unix command lineblastall -pprogname -d db -i query > outfile
Which Matrix? • Triple-PAM strategy (Altschul, 1991) • PAM 40 Short alignments, highly similar • tblastn against ESTs • PAM 120 • PAM 250 Longer, weaker local alignments • Looking in the twilight zone • BLOSUM (Henikoff, 1993) • BLOSUM 90 Short alignments, highly similar • BLOSUM 62 Most effective in detecting known members of a protein family • Standard on NCBI server – works in most cases • BLOSUM 30 Longer, weaker local alignments
Protein coding genes in prokaryotes, and simple eukaryotes • Use ORF finder http://www.ncbi.nlm.nih.gov/gorf/orfig.cgi • Simple ATG/Stop • Simple link to FASTA formatted files and BLAST. • Problems: • In frame Methionine • Small protein • Solution: comparative genomics
Figure 11 from: Methods in comparative genomics: genome correspondence, gene identification and regulatory motif discovery. Kellis M, Patterson N, Birren B, Berger B, Lander ES. J Comput Biol. 2004;11(2-3):319-55. Saccharomyces cerevisiae. Saccharomyces paradoxus, Saccharomyces mikatae, Saccharomyces bayanus
Ab initio gene identification • Goals • Identify coding exons • Seek gene structure information • Get a protein sequence for further analysis • Relevance • Characterization of anonymous DNA genomic sequences • Works on all DNA sequences
Gene-Finding Strategies Genomic Sequence Content-Based Site-Based Comparative • Inferences basedon sequence homology: • Protein sequence with similarity to translated product of query • Modular structure of proteins usually precludes finding complete gene • Bulk properties ofsequence: • Open reading frames • Codon usage • Repeat periodicity • Compositional complexity • Absolute properties ofsequence: • Consensus sequences • Donor and acceptor splice sites • Transcription factor binding sites • Polyadenylation signals • “Right” ATG start • Stop codons out-of-context
Gene-Finding Methods Genomic Sequence Rule-Based Neural Network • Cutoff method: • Criteria applied sequentially to identify possible exons • Rank or eliminate candidates from consideration based on pre-determined cutoff at each step • Composite method: • Criteria applied in parallel • Training sets used to optimize performance • Weight scores in order of importance
Evaluation Statistics TP TP TN FN FP TN FN Actual Predicted Sensitivity Fraction of actual coding regions that are correctly predicted as coding Specificity Fraction of the prediction that is actually correct Correlation Combined measure of sensitivity and specificity, Coefficient ranging from –1 (always wrong) to +1 (always right)
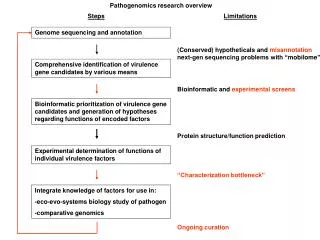
The Process • Compute the prediction • Confirm with biological sequences (also with computational tools) • Integrate all of this • Annotate genome (often via a GUI: Graphical User Interface) • Validate • Re-annotate/Update • Check it twice • Submit to GenBank
Lots of Software: • EnsEMBL (EBI) • Sequin (NCBI) • PseudoCAP (SFU) • GMOD (CSHL) • Pegasys (UBiC) • Apollo (EBI/Berkeley) • GeneMark (Georgia Institute of Tech) • GeneScan (MIT) • GenomeThreader (University of Hamberg) • HMMgene (Technical University of Denmark)
GenBank Features -10_signal -35_signal 3'clip 3'UTR 5'clip 5'UTR attenuator CAAT_signal CDS conflict C_region D-loop D_segment enhancer exon GC_signal gene iDNA intron J_segment LTR mat_peptide misc_binding misc_difference misc_feature misc_recomb misc_RNA misc_signal misc_structure modified_base mRNA N_region old_sequence polyA_signal polyA_site precursor_RNA primer_bind prim_transcript promoter protein_bind RBS repeat_region repeat_unit rep_origin rRNA satellite scRNA sig_peptide snoRNA snRNA S_region stem_loop STS TATA_signal terminator transit_peptide tRNA unsure variation V_region V_segment
GenBank Features: the important ones -10_signal -35_signal 3'clip 3'UTR 5'clip 5'UTR attenuator CAAT_signal CDS conflict C_region D-loop D_segment enhancer exon GC_signal gene iDNA intron J_segment LTR mat_peptide misc_binding misc_difference misc_feature misc_recomb misc_RNA misc_signal misc_structure modified_base mRNA N_region old_sequence polyA_signal polyA_site precursor_RNA primer_bind prim_transcript promoter protein_bind RBS repeat_region repeat_unit rep_origin rRNA satellite scRNA sig_peptide snoRNA snRNA S_region stem_loop STS TATA_signal terminator transit_peptide tRNA unsure variation V_region V_segment
Gene Prediction Caveats • Predictions are of protein coding regions • Do not detect non-coding areas (5’ and 3’ UTR) • Non-coding RNA genes are missed • Predictions are for “typical” genes • Must predict a beginning and an end • Partial or multiple genes are often missed • Training sets may be biased • Methods are sensitive to G+C content • Weighting of factors may be inordinately biased
Genome annotation problems: • Assembling the genome • Analysis & interpretation • Lack of consistency from gene to gene • Lack of consistency from person to person • Lack of controlled vocabulary • Parts we don’t know • Bacteria vs mammals • Graphical user interface • Gene expression/molecular interactions • Dimensions • Updates and maintenance
The ideal annotation of “MyGene” All clones All SNPs Promoter(s) MyGene All mRNAs All proteins • All protein modifications • Ontologies • Interactions (complexes, pathways, networks) • Expression (where and when, and how much) • Evolutionary relationships All structures
Some Concluding remarks • Trust but verify • Beware of gene prediction tools! • Always use more than one gene prediction tool and more than one genome when possible. • Active area of bioinformatics research, so be mindful of the new literature in this .