Download

1 / 72
720 likes | 830 Views
Cooperation, Sampling and Models in Sensor Network Research. Outline A Brief History of Sensor Networks The Design Cycle Cooperation Scale Fault Detection. Greg Pottie Deputy Director CENS pottie@ee.ucla.edu CENS Seminar, Oct. 24, 2008. Acknowledgements

E N D
Cooperation, Sampling and Models in Sensor Network Research Outline A Brief History of Sensor Networks The Design Cycle Cooperation Scale Fault Detection Greg Pottie Deputy Director CENS pottie@ee.ucla.edu CENS Seminar, Oct. 24, 2008 Acknowledgements The cooperation and fault detection work reported here is due to Yu-Ching Tong and Kevin Ni, respectively . CENS is supported by the National Science Foundation
In the Beginning...the Network was Flat • Much research has focused upon sensor networks with some alternative assumption sets: • Memory, processing, and sensing will be cheap, but communications will be dear; thus in deploying large numbers of sensors concentrate on algorithms that limit communications but allow large numbers of nodes • For the sensors to be cheap, even the processing should be limited; thus in deploying even larger numbers of sensors concentrate on algorithms that limit both processing and communications • In either case, interesting theory can be constructed for random deployments with large numbers and flat architectures
cue Theory for Dense Flat Networks of Simple Nodes • Redundant communications pathways given unreliable radios • Data aggregation and distributed fusion • Scalability • Density/reliability/accuracy trades • Cooperative communication • Adaptive fidelity/network lifetime trades 1995 1996 Illustration: AWAIRS overview 1997 1997 1998 1999 2000 human observer transmit decision beamforming 2001 base stationhigh resolutionprocessing query for more information 2002 2003 high powerlow false alarm ratelow duty cycle 2004 low powerhigh false alarm ratehigh duty cycle 2005 2006 2007
What applications? • Early research concentrated on short-term military deployments • Can imagine that leaving batteries everywhere is at least as acceptable as leaving depleted uranium bullets; careful placement/removal might expose personnel to danger • Detection of vehicles (and even ID of type) and detection of personnel can be accomplished with relatively inexpensive sensors that don’t need re-calibration or programming in the field • Story was plausible…
But was this ever done? • Military surveillance • Largest outdoor deployment (10000 nodes or so) was hierarchical and required careful placement; major issues with radio propagation even on flat terrain • Vehicles are relatively easy to detect with aerial assets, and the major problem with personnel is establishment of intent; this requires a sequence of images • The major challenge is urban operations, which demands much longer-term monitoring as well as concealment • Science applications diverge even more in basic requirements • Scientists want to know precisely where things are; cannot leave heavy metals behind; many other issues • Will still want dense networks of simple nodes in some locations, but will be system component
Practical Design Constraints • Validation (=debugging) is usually very painful • One part design, 1000 parts testing • Never exhaustively test with the most reliable method • So how can we trust the result given all the uncertainties? • Not completely, so the design process deliberately minimizes the uncertainties through re-use of trusted components • But is the resulting modular model/design efficient? • Fortunately not for academics; one can always propose a more efficient but untestable design • Our goal: building systems for sequence of deployments that evolve with user goals
Universal Design Procedure • Begin with what we know • E.g., trusted reference experiment, prior model(s) • Validate a more efficient procedure • Exploit prior knowledge to test selected cases • Construct tools to assist debugging • Bake-off the rival designs or hypotheses • Requires tools for rapid evaluation of data • End result is solution of an inference problem P(X|Z) • Iterate • Different model components become trusted at different stages
Some Theory Problems • Model Uncertainty • Effects on deployment density, number of measurements needed given uncertainty at different levels • Data Search and Fusion • How to search and combine data from diverse sources depends upon context (model) information information • Cooperation Scale • How many nodes give most of the utility? • Data Integrity • Sufficiency of network components/measurements to trust inferences from the data
Sampling Density, Model, and Objectives • Nyquist Sampling • High rate, but sufficient for perfect reconstruction (difficult objective) • Requires only knowledge of maximum frequency (weak model) • Compressive sensing • Rate depends on model and associated reconstruction algorithm (typically, much lower than Nyquist) • Random sampling together with solution of linear program and evaluation of a reconstruction algorithm required • Can have either perfect reconstruction or rate-distortion type of objective; key difficulty is basis (model) selection • Detection/Estimation theory • Sample to distinguish among two or more hypothesized models or parameters of models • Rate depends on how close the models are, how high the noise is, and what accuracy is required; e.g., allowing outage greatly relaxes the sampling requirements
Some Tradeoffs • Sampling Density vs. Cooperation Scale • Distributed algorithms for reconstruction or estimation usually pay only a small density penalty, with massive computational and communications reduction • Sampling Density vs. Model Certainty • Model knowledge has huge impact on sampling density • However, within compressive sensing regime not clear that finding “best” model is worth the effort compared to finding “good” ones • Sampling Density vs. Measurement Accuracy • Our results suggest relatively modest increase in density is sufficient to deal with faulty sensors • Low accuracy pays large density price; tradeoff similar to sigma-delta A/D • Sampling Density vs. Difficulty of Objective • Reduced fidelity of reconstruction, allowance of outages, etc. can vastly reduce the number of samples required
Search and Fusion • Utility of data depends upon context • That is, what modeling assumptions are made in its collection • “Raw” data always involves some model for the transducer, and usually compensation for confounding factors • Cannot attach certainty to measurements without this • More context information improves the ability for the data to be used for multiple purposes • Search is conducted on context information or model parameters • Data volume is too large, and data is meaningless without context • Instead search on identifying tags, either separately supplied or derived through signal processing associated with a model • Conflicting standards make fusion difficult • Standards are usually domain (or agency) specific • Huge variability in the models used for creation of context information
Cooperation Scale: Localization algorithm behavior In a localization scenario, only a handful of sensors more than minimum required yield most of the utility. More doesn’t really help that much. This behavior depends on the utility from the sensor. Does this happen often?
Best Case: Identical Utility • Suppose sensors yield identical utility, 1. The per sensor utility for k + 1-th sensor is: • and the marginal utility reduction from k-th sensor is
Identical Utility Utilities obtained in from the prior step, are simply • Note that when there we go from 9 to 10 sensors, 90% of utility is already present when we include the 10th sensor. The overall utility increases from 9 to 10 while the marginal utility decrease from 1/9 to 1/10. • While we can reach an arbitrary level of total utility in theory, the individual marginal utility diminish as the number of sensors increase.
Variable Utility • Even when sensors’ utilities are variable, similar behavior is obtained: Parameters: 10k trials, utility varies uniformly between 0.5 to 1.5 for each sensor.
Order Statistics • When we draw n random variables, what is the distribution for the k-th smallest within the n variables? • Order statistics answer this type of question. For the n-th IID random variable, each drawn according to fR(r), the order statistic for the k-th random variable is
Variable utility • Suppose the source is at the origin, and sensors are distributed in a disk, the distance r from the source to sensor is distributed according to the triangular distribution, fR(r) = 2r/R2, 0 < r < R
Variable utility, disk • From the order statistics, the PDF of the distance r for the k-th closest sensors out of n sensors is: Notice the high order roll off as distance increases.
Variable utility, disk 2 • Deploying more sensors can help the best one to be better, for a while But even there the relative benefit falls off quickly. Note that the next new sensors only provide a fraction of the utility and falls off rapidly.
So when does cooperation help? • When dealing with ‘other’ hazards of life such as fading. • It is well known that fading, while it can sometimes increase SNR, the chances are we will see significant degradation when we are observing the signal. • It is also well known that cooperation will get us around this problem. • So how many sensors should we use to mitigate the fading degradation?
So when does cooperation help? 2 • A handful will be sufficient to significantly reduce outage probability, just as in point to point communications. Outage: to reach same utility as the optimal sensor with no fading Outage: to reach a fixed utility goal
Asymptotic Considerations • What happens when we have a large number of sensors? • There are large variety of configurations possible, but we will assume the following • Source at origin, and sensors surrounding it • Constant deployment density (additional sensors are placed further away from the source) • All sensors have identical statistical performance, and differ only by their distances • Coherent combining possible (i.e. Maximal Ratio Combining, MRC), e.g., for a detection problem
Utility Metric and deployment model • By using MRC, the metric is SNR. In addition, with this setup, we only need to consider distance between the source and the sensors: • A minimum separation distance of eis enforced to avoid infinite utility. • Sensors will be deployed within a uniform annulus between eand R.
Expected utility Single sensor expected utility • a>2 • a=2 • Aggregated utility under constant density is proportional to n, the number of sensors • M represents the constant factor
Aggregated Utility Utility grows logarithmically for a =2. a > 2 has bounded utility under constant density deployment condition. The slight decrease in utility when ais large is an artifact of ebecause the order statistic of the closest sensor is sensitive to the stay out region and the aggregated utility is sensitive to the nearest sensors distribution.
Conclusion: Localization Problem • Utilities are dominated by the few that have the most utility. • For the purpose of estimation, a large number of sensors help a priori by placing a sensor closer to the source, but will not help during the estimation process after the sensors were placed and the event of interest is taking place. • Under constant density, even with a large number of sensors, cooperation is not helpful in significantly increasing the aggregated utility.
Other Cooperation Problems • Examination of other utility functions • How broad is the class of problems to which our basic conclusions apply? • Examination of related problems • Quantized observations • Tracking • Estimation of continuous phenomena (e.g., fields) or extraction of statistics • Coverage
Coverage Utility • In the following, we will consider the coverage type of utility (e.g., fraction of region with acceptable detection probability). If the goal is to cover the field, as we add sensors, how does cooperation among sensors transform the problem?
Coverage Utility, 2 • Cooperation greatly improves utility: In the previous lattice type deployment, cooperation gives us the coverage we need significantly sooner. However, as before, a small number of neighboring nodes yields most of the utility
Another Reason to Cooperate: Data Integrity 30 • Sensors are exposed to harsh environments. • This leads to failures or malfunctions in sensors. • Many deployments have had to discard data due to faulty data: • While examining the micro-climate over the volume of a redwood tree, only 49% of the data could be used. [TPS05] • A deployment at Great Duck Island classified 3%-60% of data as faulty [SMP04]
Sensor Faults Temperature data from a buoy in a NAMOS deployment at Lake Fulmor Faulty data leads to uncertain scientific inferences Goal is to reliably identify faults as they occur so that we can immediately take action to either repair or replace sensors.
Why is it hard to detect faults? For sensor networks, we do not know the true value of the phenomenon. Faults can only be defined in reference to models of expected behavior Anomalous data may not necessarily be faulty If we develop a model based off of sensor data, how do we know this model will be accurate? How can we ensure faulty sensors influence fault detection?
Outline Sensor network data fault types and their underlying causes and features A maximum a posterior method for selecting a subset of non-faulty sensors Application of a Bayesian data modeling method to the field of fault detection End-to-end Bayesian system to detect faulty sensor data
What is the purpose of a taxonomy? A list of the most commonly seen faults serves as a basis of what to expect in a real deployment These faults can be incorporated into a system to accurately identify faults. When testing systems, we can inject faults into a test data set. In analyzing data, anomalous data can be checked against this list to eliminate simple cases and causes.
Assumptions • All sensor network data forwarded to central location for data processing • Local processing may occur to reduce communication costs • Tradeoff between data/inference quality vs. decentralization/communication costs • No communication faults corrupting data packets. • Missing data is not a sign of a fault • Alternate view has merit in cases such as expected heartbeat messages • No malicious attacks on the network
Data Modeling • Models are mathematical representations of expected behavior for both non-faulty and faulty data. • Can be defined as a range of values: • Relative humidity is between 0% and 100% • Temperature is greater than 0K • Can be a well defined formulaic model that can generate simulated data: • Temperature = A * time + B. • In the absence of ground truth, faults can only be defined by models of expected behavior • Human input necessary for modeling and updates by providing vital contextual knowledge.
Sensor network features • Features – describes data, system or environment useful in fault detection • Used to detect or explain the cause of faults • Aids in systematically defining faults. • Three classes of features: • Environment features: sensor location, rainy weather, microclimate models • System features: sensor transducer/ADC performance, sensor age, battery state, noise • Data features: mean/variance, correlation, gradient
Sensor Network Data Faults • Faults have varying levels of importance dependent on context: • Some still hold informational value and can be used to make inferences at lower fidelity • Some are totally uninterpretable and must be discarded • Two overlapping approaches to defining a fault • “Data-centric” view: describe faults by characteristics of the data behavior • “System” view: define a physical malfunction with a sensor and describe what type of features this will exhibit in the data • Multiple faults may occur at the same time and may be related
Data-centric view Raw humidity readings from a NIMS deployment Outlier: an isolated sample or sensor that significantly deviates from the expected temporal or spatial models of the data.
System-centric view Temperature at node 103 in NAMOS sensors at Lake Fulmor Connection or hardware fault: typically requires replacement or repair of a sensor Frequently manifested as unusually high or low readings.
Low Battery • Low Battery: not only indication of sensor life, but can cause less reliable data Temperature and voltage levels from nearby motes in an Intel-Berkeley Lab experiment
Design Principles • Sensor network fault detection design principles: • We must model or restrict ourselves to a model of the phenomenon we are sensing • Based upon this model, we must determine the expected behavior of the data using available data • We must determine when sensor data conforms to the expected behavior of the network or phenomenon • We must remedy problems or classify behavior as either acceptable or faulty and update our models
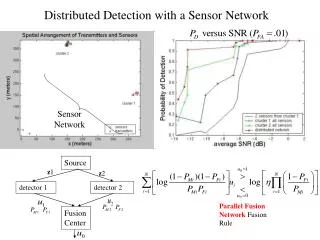
Online fault detection algorithm • First develop an online fault detection system with immediate decisions. • Two phase system: • Bayesian maximum a posteriori selection of a subset of agreeing sensors which are used to model the expected phenomenon behavior • Judgment of fault or non-fault based upon this expected behavior.
Additional Assumptions • First assume sensors will have the same trends (slopes). • Later will further restrict to all sensors measuring the same values. • Non-faulty data is locally linear. • No large data gaps • Gaussian noise model for simplicity • At least sensors are not faulty at any given time
System Flow Linear model calculation Window size selection Offset bias removal Likelihood parameter estimation Posterior calculation MAP Selection Restriction to a physical model with assumptions Hysteresis for decision stability Phase one Determination of Fault/non-Fault Neyman-Pearson computation Likelihood calculation Calculation of model of agreeing Subset Determination of sensor expected behavior Phase two
Results Real Data: four sensors from the Cold Air Drainage experiment in James Reserve Detection Rate: 75.9% False Detection rate: 11.8%
Hierarchical Bayesian space-time (HBST) modeling Introduce a new modeling technique that is more capable of representing sensor network data. Utilize the HBST modeling approach of [WBC98] and adapt it for fault detection. Not perfect but more accurate and more robust than linear AR modeling
Measurement Process • At time we observe data from sensors • is a vector of the observations • Noise process is spatially independent normally distributed
Phenomenon Process Combination of three main components with additive an additive noise component
Phenomenon Process Site specific mean vector: A first order linear regression assumes site specific mean has a linear trend in space. Combination of three main components with additive an additive noise component