Download
1 / 17
170 likes | 351 Views
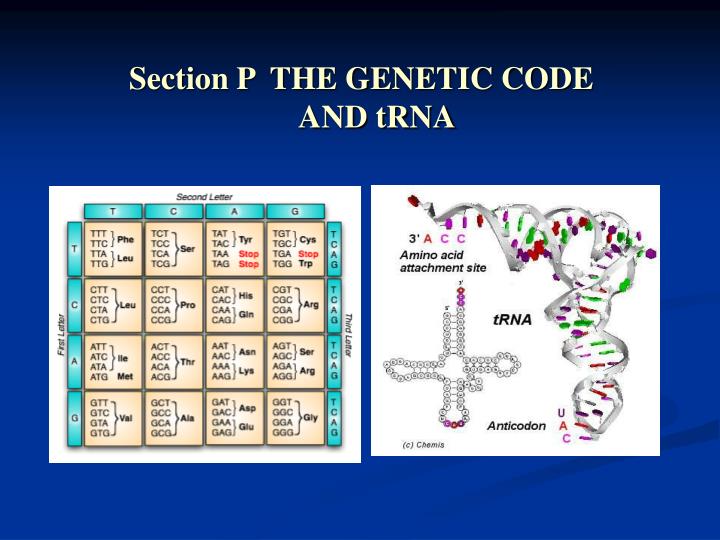
Section P THE GENETIC CODE AND tRNA. Content. P1-THE GENETIC CODE P2 -tRNA STRUCTURE AND FUNCTION. Nature Deciphering Feature Effect of mutation. Universality ORFs Overlapping genes. THE GENETIC CODE. The genetic code: how do nucleotides specify 20 amino acids?

E N D
Content P1-THE GENETIC CODE P2 -tRNA STRUCTURE AND FUNCTION
Nature Deciphering Feature Effect of mutation Universality ORFs Overlapping genes THE GENETIC CODE
The genetic code: how do nucleotides specify 20 amino acids? • 4 different nucleotides (A, G, C, U/T) • Possible codes: • 1 letter code 4 AAs <20 • 2 letter code 4 x 4 = 16 AAs <20 • 3 letter code 4 x 4 x 4 = 64 AAs >>20 • Three letter code with 64 possibilities for 20 amino acids suggests that the genetic code is degenerate (i.e., more than one codon specifies the same amino acid).
Evidence that the genetic code is a triplet code: • 1960s: Francis Crick et al. • Studied frameshift mutations in bacteriophage T4 (& E. coli), induced by the mutagen proflavin. • Proflavin adds or deletes base pairs. • Two ways to identify mutant T4: • Growth with E. coli B: • r+(wild type) turbid plaques • rII (mutant) clear plaques • Growth with E. coli K12(): • r+(wild type) growth • rII(mutant) no growth
Discovered that frameshift mutations (addition or deletion) resulted in a different sequence of amino acids. • Also discovered that r+ mutants treated with proflavin could be restored to the wild type (revertants). • deletion (-) corrects addition (+) or vice versa Fig. 6.6
Combination of three r+ mutants routinely yielded revertants, unlike other multiple combinations.
Characteristics of the genetic code (written as in mRNA, 5’ to 3’): Code is triplet. Each 3 nucleotide codon in mRNA specifies 1 amino acid. Code is comma free. mRNA is read continuously, 3 bases at a time without skipping bases (not always true, translational frameshifting is known to occur). Code is non-overlapping. Each nucleotide is part of only one codon and is read only once. Code is almost universal. Most codons have the same meaning in different organisms (e.g., not true for mitochondria of mammals). Code is degenerate. 18 of 20 amino acids are coded by more than one codon. Met and Trp are the only exceptions. Many amino acids are four-fold degenerate at the third position. Code has start and stop signals. ATG codes for Met and is the usual start signal. TAA, TAG, and TGA are stop codons and specify the the end of translation of a polypeptide. Wobble occurs in the tRNA anti-codon. 3rd base is less constrained and pairs less specifically.
P2 tRNA STRUCTURE AND FUNCTION • tRNA primary structure The linear sequence (primary structure) of tRNA is 60-95 nt long, most commonly 76. • tRNA secondary structure The cloverleaf structure is a common secondary structural representation of tRNA molecules which shows the base pairing of various regions to form foer stems (arms) and three loops. • tRNA tertiary structure Nine hydrogen bonds form between the bases(mainly the invariant ones) in the single-stranded loops and fold the secondary structure into an L-shaped tertiary structure, with the anticodon and amino acid acceptor stems at opposite ends of the molecule.
tRNA structure Fig. 2. tRNA structure. (a) Cloverleaf structure showing the invariant and semi-variant nucleotides, where I = inosine, Ψ = pseudouridine, R = purine, Y = pyrimidine and * indicates a modification. (b) Tertiary hydrogen bonds between the nucleotides in tRNA are shown as dashed lines. (c) The L-shaped tertiary structure of yeast tRNATyr. Part (c) reproduced from D.M. Freifelder (1987) Molecular Biology, 2nd Edn.
1. The 5'-terminal phosphate group. 2. The acceptor stem is a 7-bp stem made by the base pairing of the 5'-terminal nucleotide with the 3'-terminal nucleotide (which contains the CCA 3'-terminal group used to attach the amino acid). The acceptor stem may contain non-Watson-Crick base pairs. 3. The CCA tail is a CCA sequence at the 3' end of the tRNA molecule. This sequence is important for the recognition of tRNA by enzymes critical in translation. In prokaryotes, the CCA sequence is transcribed. In eukaryotes, the CCA sequence is added during processing and therefore does not appear in the tRNA gene. 4. The D arm is a 4 bp stem ending in a loop that often contains dihydrouridine. 5. The anticodon arm is a 5-bp stem whose loop contains the anticodon. 6. The T arm is a 5 bp stem containing the sequence TΨC where Ψ is a pseudouridine. 7. Bases that have been modified, especially by methylation, occur in several positions outside the anticodon. The first anticodon base is sometimes modified to inosine (derived from adenine) or pseudouridine (derived from uracil).
P2 tRNA STRUCTURE AND FUNCTION tRNA function When charged by attachment of a specific amino acid to their 3’-end to become aminoacyl-tRNA , tRNA molecules act as adapor molecules in protein synthesis. Aminoacylation of tRNA First, the aminoacyl-tRNA synthetase attaches adenosine monophosphate(AMP) to the –COOH group of the amino acid to creat an aminoacyl adenylate intermediate. Then the appropriate tRNA displaces the AMP. Aminoacyl-tRNA synthetases The synthetase enzymes contact their cognate tRNA by the inside of its L-shaped and use certain parts of the tRNA, called identity elements, to distinguish these similar molecules from one another. Proofreading Proofreading occurs when a synthetase carries out step 1 of the aminoacylation reaction with the wrong, but chemically similar, amino acid. It will not carry out step 2, but will hydrolyze the aminoacyl adenylate instead.
First, the aminoacyl-tRNA synthetase attaches adenosine monophosphate(AMP) to the –COOH group of the amino acid to creat an aminoacyl adenylate intermediate. Then the appropriate tRNA displaces the AMP. Fig. 3. Formation of aminoacyl-tRNA.
Aminoacyl-tRNA synthetases catalyze amino acid-tRNA joining reaction which is extremely specific. • Nomenclature of tRNA-synthetases and charged tRNAs Amino acid: serine Cognate tRNA: tRNAser Cognate aminoacyl-tRNA synthetase: seryl-tRNA synthetase Aminoacyl-tRNA: seryl-tRNAser
The ynthetases have to be able to distinguish between about 40 similarly shaped, but different, tRNA molecules in cells, and they use particular parts of the tRNA molecules, called identity elements, to be able to do this. Fig. 4. Identity elements in various tRNA molecules.
Proofreading • Proofreading occurs at step 2 when a synthetase carries out step 1 of the aminoacylation reaction with the wrong, but chemically similar, amino acid. • Some synthetase enzymes that have to distinguish between two chemically similar amino acids can carry out a proofreading step. If they accidentally carry out step 1 of the aminoacylation reaction with the wrong amino acid, then they will not carry out step 2. Instead they will hydrolyze the amino acid adenylate. This proofreading ability is only necessary when a single recognition step is not sufficiently discriminating. Discrimination between the amino acids Phe and Tyr can be achieved in one step because of the -OH group difference on the benzene ring, so in this case there is no need for proofreading.