Download

1 / 34
340 likes | 425 Views
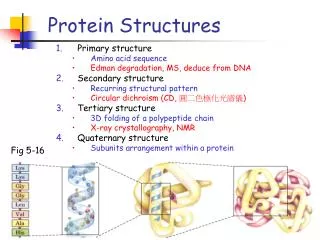
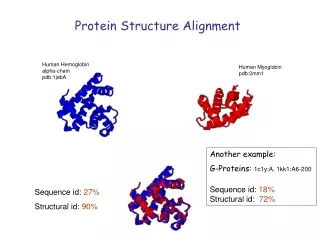
Fast Alignment of Protein Structures Based on Conformational Letters. Wei-Mou Zheng Institute of Theoretical Physics Academia Sinica. Introduction Conformational alphabet and CLESUM CLePAPS: Pairwise structure alignment BloMAPS: Multiple structure alignment Conclusion. Introduction

E N D
Fast Alignment of Protein Structures Based onConformational Letters Wei-Mou Zheng Institute of Theoretical Physics Academia Sinica
Introduction • Conformational alphabet and CLESUM • CLePAPS: Pairwise structure alignment • BloMAPS: Multiple structure alignment • Conclusion
Introduction • Protein structures comparison: an extremely important problem in structural and evolutional biology. • detection of local or global structural similarity • prediction of the new protein's function. • structures are better conserved → remote homology detection • Structural comparison → • organizing and classifying structures • discovering structure patterns • discovering correlation between structures & sequences → • structure prediction
Conformational alphabet and CLESUM The main difference of CLePAPS from other existing algorithms for structure alignment is the use of conformational letters. Conformational letters = discretized states of 3D segmental conformations. A letter = a cluster of combinations of three angles formed by Capseudobonds of four contiguous residues. (obtained by clustering according to the probability distribution.) Centers of 17 conformational letters
Similarity between conformational letters CLESUM: Conformational LEtter SUbstitution Matrix typical helix evolutionary + geometric typical sheet Mij = 20* log 2 (Pij/PiPj) ~ BLOSUM83, H ~ 1.05 constructed using FSSP representatives.
CLePAPS: Pairwise structure alignment • Structure alignment --- a self-consistent problem • Correspondence Rigid transformation • However, when aligning two protein structures, at the beginning we know neither the transformation nor the correspondence. • DALI, CE • VAST • STRUCTAL, ProSup • CLePAPS: Conformational Letters based Pairwise Alignment of Protein Structures • Initialization + iteration • Similar Fragment Pairs (SFPs); • Anchor-based; • Alignment = As many consistent SFPs as possible
SFPs Anchor-based superposition consistent anchor SFP inconsistent Collect as many consistent SFPs as possible
SFP = highly scored string pair • Fast search for SFPs by string comparison • CLESUM similarity score importance of SFPs • Guided by CLESUM scores, only the top few SFPs need to be examined • to determine the superposition for alignment, and hence a reliable greedy strategy becomes possible. similar seed the smaller kept Redundancy removal shaved
Selection of optimal anchor 3 5 4 rank 1 2 Example: Top K, K = 2; J = 5 2 Anchor 1 Anchor # of consistent SFBs = 4 # of consistent SFBs = 1 Top-1 SFB is globally supported by three other SFPs, while Top-2 SFB is supported only by itself.
‘Zoom-in’ d1 Anchor d2 d3 d1 > d2 > d3 successively reduced cutoffs for maximal coordinate difference
specificity 1/2 sensitivity 5/6 1 Flow chart of the CLePAPS algorithm
Finding SFPs of high CLESUM similarity scores • The greedy `zoom-in' strategy • Refinement by elongation and shrinking • The Fischer benchmark test • Database search with CLePAPS • Multiple solutions of alignments: repeats, symmetry, domain move • Non-topological alignment and domain shuffling
Multiple structure alignment • Multiple alignment carries significantly more information than pairwise alignment, and hence is a much more powerful tool for classifying proteins, detecting evolutionary relationship and common structural motifs, and assisting structure/function prediction. • Most existing methods of multiple structural alignment combine a pairwise alignment and some heuristic with a progressive-type layout to merge pairwise alignments into a multiple alignment. • like CLUSTAL-W, T-Coffee: MAMMOTH-mult, CE-MC • slow • alignments which are optimal for the whole input set might be missed • A few true multiple alignment tools: MASS, MultiProt
Vertical equivalency and horizontal consistency local similarity among consistent spatial structures arrangement for a pair
Highly similar fragment block (HSFB) Attributes of HSFB: width, positions, depth, score, consensus Horizontal consistency of two HSFBs similar seed template inconsistent superposition consistent c a&c b pivot a a&b anchor HSFB
1. Creating HSFBs create HSFBs using the shortest protein as a template sort HSFBs according to depths, then to scores derive redundancy-removed HFSBs by examining position overlap If the new HSFB has a high proportion of positions which overlaps with existing HSFBs, remove it. 2. Selecting optimal HSFB for each HSFB in top K select the pivot protein based on the HSFB consensus; superimpose anchored proteins on the pivot; find consistent HSFBs; A consistent HSFB contains at least 3 consistent SFPs. select the best HSFB which admits most consistent HSFBs;
3. Building scaffold build a primary scaffold from the consistent HSFBs; update the transformation using the consistent HSFBs; recruit aligned fragments; improve the scaffold; create average template; 4. Dealing with unanchored proteins Unanchored protein: has no member in the anchor HSFB which is supported by enough number of consistent SFPs. for each unanchored protein if (members are found in colored HSFBs) find top K members; Try to use ‘colored’ HSFBs other than the anchor HSFB. else search for fragments similar to the scaffold, and select top K; pairwisely align the protein on the template;
5. Fingding missing motifs find missing motifs by registering atoms in spatial cells; Only patterns shared by the pivot protein have a chance to be discovered above. Two ways for discovering ‘missing motifs’: by searching for maximal star-trees and by registering atoms in spatial cell. The latter: We divide the space occupied by the structures after superimposition into uniform cubic cells of a finite size, say 6A. The number of different proteins = cell depth. Sort cells in descending order of depth. from cells to ‘octads’ find fragments in octads find aligned fragments 6. Final refinement refine the alignment and the average template;
Conclusion • CLePAPS and BLOMAPS distinguish themselves from other existing algorithms for structure alignment in the use of conformational letters. • Conformational alphabet: aptly balance precision with simplicity • CLESUM: a proper measure of similarity between states • fit the e-congruent problem • CLESUM extracted from the database FSSP contains information of structure database statistics, which reduces the chance of accidental matching of two irrelevant helices. evolutionary + geometric = specificity gain • For example, two frequent helices are geometrically very similar, • but their score is relatively low. • CLESUM similarity score can be used to sort the importance of SFPs for a greedy algorithm. Only the top few SFPs need to be examined.
Conclusion Greedy strategies: HSFBs instead of SFBs Use the shortest protein to generate HSFB Use consensus to select pivot Top K --- guided by scores Optimal anchor HSFB Missing motifs Tested on 17 structure datasets Faster than MASS by 3 orders
* * * Overall algorithm of BLOMAPAS * * * create HSFBs using the shortest protein as a template; sort HSFBs; derive redundancy-removed HFSBs; for each HSFB in top K select the pivot protein based on the HSFB consensus; superimpose anchored proteins on the pivot; find consistent HSFBs; select the best HSFB which admits most consistent HSFBs; build a primary scaffold from the consistent HSFBs; update the transformation using the consistent HSFBs; recruit aligned fragments; improve the scaffold; create average template; for each unanchored protein if (members are found in colored HSFBs) find top K members; else search for fragments similar to the scaffold, and select top K; pairwisely align the protein on the template; find missing motifs by registering atoms in spatial cells; refine the average template;
1ak6-aa sasgvqVADEVCRIFYDMkvrkcstpeeikkrkKAVIFCLSADKKCIIVEEGKeilvgdvgvtitDPFKHFVGMLPEKD 1cfyB-aa vaVADESLTAFNDLKLGKKY---------KFILFGLNDAKTEIVVKETStd----------PSYDAFLEKLPEND 1cnuA-aa giaVSDDCVQKFNELKLGHQH---------RYVTFKMNASNTEVVVEHVGgpn---------ATYEDFKSQLPERD 1f7sA-aa asgmaVHDDCKLRFLELKAKRTH---------RFIVYKIEEKQKQVVVEKVGqpi---------QTYEEFAACLPADE 1cfyB-ss ceECHHHHHHHHHHHHHCCC CEEEEEECCCCCEEEEEEEEcc CCHHHHHCCCCCCC Core **1111111111111*** xaaaaaa******bbbbbbb **22222xxxxxxx 1ak6-cl mkobbeCCAJJKJJIKJKmlnmgalpjkmjjjcBMEDEEQCQNOLQCFBGNCLqdbahjmklnleCGCMJHJJKMEAJL 1cfyB-cl CCAJJHHHHHHHIKKAPL---------BLDEEECCAHOMLDECPLEEbg----------PGAJJHIJJGCAKL 1cnuA-cl fCCAJJIJIHHHHKKKAPL---------BLDEFECCAHOMLDECBLEEcai---------GFAHJIKJIGCAKL 1f7sA-cl dceDCAJJIHHHHHHIKKAML---------BLDEEEDPPJKOGDECBLEFcal---------EDAHHHHJJMCAIL 1ak6-aa CRYALYDASFETkesrke--ELMFFLWAPELAPLKSKMIYASSKDAIKKKFQGIKHECQANGPeDLNRACIAEKLGGsl 1cfyB-aa CLYAIYDFEYEIngNEGKRSKIVFFTWSPDTAPVRSKMVYASSKDALRRALNGVSTDVQGTDFsEVSYDSVLERVSR 1cnuA-aa CRYAIFDYEFQV--DGGQRNKITFILWAPDSAPIKSKMMYTSTKDSIKKKLVGIQVEVQATDAaEISEDAVSERAKK 1f7sA-aa CRYAIYDFDFVT-aENCQKSKIFFIAWCPDIAKVRSKMIYASSKDRFKRELDGIQVELQATDPte 1cfyB-ss CEEEEEEEEEEEccCCEEEEEEEEEEECCCCCCHHHHHHHHHHHHHHHHHCCCCCEEEEECCHhHHCHHHHHHHHHC Core xccccc****** ******dddddddxxxxxx333333333333333*******eeeeexx4 44x444******* 1ak6-cl EECEEEAFBLDEbkfnge--BEFCEPOGEAIGCAJIIIKIJKJJIIIJJKJMKPOLBGEEPLAjJJGAHJKKKINIJkq 1cfyB-cl DEDEDEBFEEDEcnOMCQEEECEEEBEBEAJGCAHHHHHHHIIMHJKIHIGENGBLEEBEPLAjHKGAIHIHJHIK 1cnuA-cl DEDEDEAFEEDB--NOGCEEEBFEEBEBEAJGCAHHHHIIHHIMIIIHHHMENBBLEEEEBLAiIIGAJIIIJJII 1f7sA-cl DEDEDEBBEEDF-aJOGCEFDCEEFBEBEAIGCAJHHHHHHHIMIHHHJHMENBBLEEDFEDPj The alignment of four CL proteins to the template for the CL-GL ensemble. two additional helices indexed as 1 and 2, “x”: capping; ‘*’: submotifs specific to CL
FSSP representative pairs with the same first three family indices are used to construct CLESUM. amino acids a.b.c.u.v.w avpetRPNHTIYINNLNEKIKKDELKKSLHAIFSRFGQILDILVSRS... a.b.c.x.y.z ahLTVKKIFVGGIKEDT....EEHHLRDYFEQYGKIEVIEIMTDRGS conformational letters a.b.c.u.v.wCCPMCEALEEEENGCPJGCCIHHHHHHHHIKMJILQEPLDEEEBGAIK a.b.c.x.y.z ...BBEBGEDEENMFNML....FAHHHHHKKMJJLCEBLDEBCECAKK NAB++; NBA++;
1, Fast search for SFPs by merely string comparison 2, Width 20 for specificity + width 8 for sensitivity 3, Optimal anchor SFP selected by checking consistency 4, Avoid local trap by ’zoom-in’ The running time for the 68 pairs of the Fischer benchmark is less than 2% of that of the downloaded CE local version. Next steps 1, BLOMAPS: fast multiple structure alignment; SFPs → Highly Similar Fragment Blocks (HFBs) 2, Include biochemical information into CLESUM by amino acid clustering. Entropic clustering: AVCFIWLMY (h) + DEGHKNPQRST (p)
Entropic h-p clustering: AVCFIWLMY and DEGHKNPQRST CLESUM-hh (lower left) and CLESUM-pp (upper right)
Rigid transformation for Superimposition Finding the rotation R and the translation T to minimize If the two sets of points are shifted with their centers of mass at the origin, T=0. Let X3xn any Y3xn be the sets after shift. . Introduce = , the objective function is defined as where Lagrange multipliers are g and symmetric matrix L, representing the conditions for R to be an orthogonal and proper rotation matrix. constraint: where M is symmetric, and S = diag(si), si= 1 or -1. |C| = |R||M| = |M| = |D||S|. Singular values are non-negative, |D|>0. Finally, |S| = sgn(|C|), and
initial correspondence (anchor SFP) optimal transformation for the correspondence no end Convergent? yes Correspondence updating by adding consistent SFPs
Protein structure alphabet: discretization of 3D continuous structure states • Bridge 2’ structure and 3D structure • Enhance correlation between sequence and structure • Fast structure comparison • Structure prediction (transplant 2’ structure prediction methods for 3D)
Default parameters of CLePAPS Symbol Value Meaning 20 length of long SFPs 350 similarity threshold for long SFPs 10 number of long SFPs used as seed candidates 50 number of long SFPs for building a star-tree 8 length of short SFPs for blank-filling 0 similarity threshold for short SFPs 4 minimum length of aligned fragments 5A distance cutoff for evaluating overall alignment 10A separation threshold for star construction 8A separation cutoff for blank-filling in first run 6A separation cutoff for blank-filling in second run 5A separation cutoff for blank-filling in third run 0.1 maximal difference for rotational matrix entries of two ‘identical' alignments