Download

1 / 36
360 likes | 591 Views
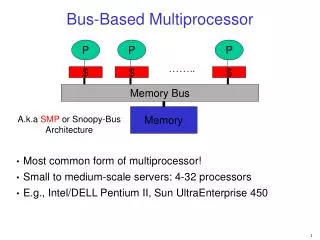
UMA Bus-Based SMP Architectures. The simplest multiprocessors are based on a single bus. Two or more CPUs and one or more memory modules all use the same bus for communication. If the bus is busy when a CPU wants to read memory, it must wait. Adding more CPUs results in more waiting.

E N D
UMA Bus-Based SMP Architectures • The simplest multiprocessors are based on a single bus. • Two or more CPUs and one or more memory modules all use the same bus for communication. • If the bus is busy when a CPU wants to read memory, it must wait. • Adding more CPUs results in more waiting. • This can alleviated by having a private cache for each CPU.
Snooping Caches • With caches a CPU may have stale data in its private cache. • This problem is known as the cache coherence or cache consistency problem. • This problem can be controlled by algorithms called cache coherence protocols. • In all solutions, the cache controller is specially deigned to allow it to eavesdrop on the bus, monitoring all bus requests and taking action in certain cases. • These devices are called snooping caches.
MESI Cache Coherence Protocol • When a protocol has the property that not all writes go directly through to memory (a bit is set instead and the cache line is eventually written to memory) we call it a write-back protocol. • One popular write-back protocol is called the MESI protocol. • It is used by the Pentium II and other CPUs. • Each cache entry can be in one of four states: • Invalid - the cache entry does not contain valid data • Shared - multiple caches may hold the line; memory is up to date
MESI Cache Coherence Protocol • Exclusive - no other cache holds the line; memory is up to date • Modified - the entry is valid; memory is invalid; no copies exist • Initially all cache entries are invalid • The first time memory is read, the cache line is marked E (exclusive) • If some other CPU reads the data, the first CPU sees this on the bus, announces that it holds the data as well, and both entries are marked S (shared) • If one of the CPUs writes the cache entry, it tells all other CPUs to invalidate their entries (I) and its entry is now in the M (modify) state.
MESI Cache Coherence Protocol • If some other CPU now wants to read the modified line from memory, the cached copy is sent to memory, and all CPUs needing it read it from memory. They are marked as S. • If we write to an uncached line and the write-allocate is in use, we will load the line, write to it and mark it as M. • If write-allocate is not in use, the write goes directly to memory and the line is not cached anywhere.
UMA Multiprocessors Using Crossbar Switches • Even with all possible optimizations, the use of a single bus limits the size of a UMA multiprocessor to about 16 or 32 CPUs. • To go beyond that, a different kind of interconnection network is needed. • The simplest circuit for connecting n CPUs to k memories is the crossbar switch. • Crossbar switches have long been used in telephone switches. • At each intersection is a crosspoint - a switch that can be opened or closed. • The crossbar is a nonblocking network.
Sun Enterprise 1000 • An example of a UMA multiprocessor based on a crossbar switch is the Sun Enterprise 1000. • This system consists of a single cabinet with up to 64 CPUs. • The crossbar switch is packaged on a circuit board with eight plug in slots on each side. • Each slot can hold up to four UltraSPARC CPUs and 4 GB of RAM. • Data is moved between memory and the caches on a 16 X 16 crossbar switch. • There are four address buses used for snooping.
UMA Multiprocessors Using Multistage Switching Networks • In order to go beyond the limits of the Sun Enterprise 1000, we need to have a better interconnection network. • We can use 2 X 2 switches to build large multistage switching networks. • One example is the omega network. • The wiring pattern of the omega network is called the perfect shuffle. • The labels of the memory can be used for routing packets in the network. • The omega network is a blocking network.
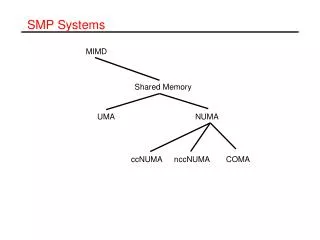
NUMA Multiprocessors • To scale to more than 100 CPUs, we have to give up uniform memory access time. • This leads to the idea of NUMA (NonUniform Memory Access) multiprocessors. • They share a single address space across all the CPUs, but unlike UMA machines local access is faster than remote access. • All UMA programs run without change on NUMA machines, but the performance is worse. • When the access time to the remote machine is not hidden (by caching) the system is called NC-NUMA.
NUMA Multiprocessors • When coherent caches are present, the system is called CC-NUMA. • It is also sometimes known as hardware DSM since it is basically the same as software distributed shared memory but implemented by the hardware using a small page size. • One of the first NC-NUMA machines was the Carnegie Mellon Cm*. • This system was implemented with LSI-11 CPUs (the LSI-11 was a single-chip version of the DEC PDP-11). • A program running out of remote memory took ten times as long as one using local memory. • Note that there is no caching in this type of system so there is no need for cache coherence protocols.
Cache Coherent NUMA Multiprocessors • Not having a cache is a major handicap. • One of the most popular approaches to building large CC-NUMA (Cache Coherent NUMA) multiprocessors currently is the directory-based multiprocessor. • Maintain a database telling where each cache line is and what its status is. • The db is kept in special-purpose hardware that responds in a fraction of a bus cycle.
DASH Multiprocessor • The first directory-based CC-NUMA multiprocessor, DASH (Directory Architecture for SHared Memory), was built at Stanford University as a research project. • It has heavily influenced a number of commercial products such as the SGI Origin 2000 • The prototype consists of 16 clusters, each one containing a bus, four MIPS R3000 CPUs, 16 MB of global memory, and some I/O equipment. • Each CPU snoops on its local bus, but not on any other buses, so global coherence needs a different mechanism.
DASH Multiprocessor • Each cluster has a directory that keeps track of which clusters currently have copies of its lines. • Each cluster in DASH is connected to an interface that allows the cluster to communicate with other clusters. • The interfaces are connected in a rectangular grid. • A cache line can be in one of three states • UNCACHED • SHARED • MODIFIED • The DASH protocols are based on ownership and invalidation.
DASH Multiprocessor • At every instant each cache line has a unique owner. • For UNCACHED or SHARED lines, the line’s home cluster is the owner • For MODIFIED lines, the cluster holding the one and only copy is the owner. • Requests for a cache line work there way out from the cluster to the global network. • Maintaining memory consistency in DASH is fairly complex and slow. • A single memory access may require a substantial number of packets to be sent.
Sequent NUMA-Q Multiprocessor • The DASH was an important project, but it was never a commercial system. • As an example of a commercial CC-NUMA multiprocessor, consider the Sequent NUMA-Q 2000. • It uses an interesting and important cache coherence protocol called SCI (Scalable Coherent Interface). • The NUMA-Q is based on the standard quad board sold by Intel containing four Pentium Pro CPU chips and up to 4 GB of RAM. • All these caches are kept coherent by using the MESI protocol.
Sequent NUMA-Q Multiprocessor • Each quad board is extended with an IQ-Link board plugged into a slot designed for network controllers. • The IQ-Link primarily implements the SCI protocol. • It holds 32 MB of cache, a directory for the cache, a snooping interface to the local quad board bus and a custom chip called the data pump that connects it with other IQ-Link boards. • It pumps data from the input side to the output side, keeping data aimed at its node and passing other data unmodified. • Together all the IQ-link boards form a ring.
Distributed Shared Memory • A collection of CPUs sharing a common paged virtual address space is called DSM (Distributed Shared Memory). • When a CPU accesses a page in its own local RAM, the read or write just happens without any further delay. • If the page is in a remote memory, a page fault is generated. • The runtime system or OS sends a message to the node holding the page to unmap it and send it over. • Read-only pages may be shared.
Distributed Shared Memory • Pages, however, are an unnatural unit for sharing, so other approaches have been tried. • Linda provides processes on multiple machines with a highly structured distributed shared memory. • The memory is accessed through a small set of primitive operations that can be added to existing languages such as C and FORTRAN. • The unifying concept behind Linda is that of an abstract tuple space. • Four operations are provided on tuples:
Distributed Shared Memory • out, puts a tuple into the tuple space • in, retrieves a tuple from the tuple space. • The tuples are addresses by content, rather than by name. • read is like in but it does not remove the tuple from the tuple space. • eval causes its parameters to be evaluated in parallel and the resulting tuple to be deposited in the tuple space. • Various implementations of Linda exist on multicomputers. • Broadcasting and directories are used for distributing the tuples.
Distributed Shared Memory • Orca uses full-blown objects rather than tuples as the unit of sharing. • Objects consist of internal state plus operations for changing the state. • Each Orca method consists of a list of (guard, block-of-statements) pairs. • A guard is a Boolean expression that does not contain any side effects, or the empty guard, which is simply true. • When an operation is invoked, all of its guards are evaluated in an unspecified order.
Distributed Shared Memory • If all of them are false, the invoking process is delayed until one becomes true. • When a guard is found that evaluates to true, the block of statements following it is executed. • Orca has a fork statement to create a new process on a user-specified processor. • Operations on shared objects are atomic and sequentially consistent. • Orca integrates shared data and synchronization in a way not present in page-based DSM systems.