Download

1 / 18
180 likes | 307 Views
Discovering Relational Patterns across Multiple Databases. Xingquan Zhu1 Xindong Wu ICDE 07. Outline. Introduction Preliminaries Discovering relational patterns Experiments Conclusion. Introduction.

E N D
Discovering Relational Patterns across Multiple Databases Xingquan Zhu1 Xindong Wu ICDE 07
Outline. • Introduction • Preliminaries • Discovering relational patterns • Experiments • Conclusion
Introduction • In a naïve sense, the problem of discovering relational patterns across multiple databases can be solved by three simple solutions: • (1) Sequential Pattern Verification (SPV) • (2) Parallel Pattern Mining (PPM) • (3) Collaborative Pattern Mining (CPM)
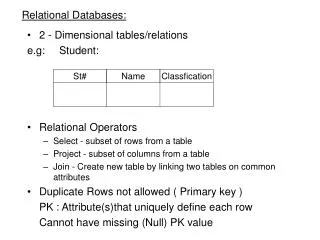
Preliminaries • Query 1: Finding the patterns that are frequent with a support level of α in either of the cancer datasets: D2, D3, or D4, but are significantly infrequent in D1. i.e., {(D2 | D3 | D4) ≥α} & {(D1 <β)} • Query 2: Finding the patterns that are frequent with a support level of α in all cancer datasets, but with support in Leukemia tissues higher than other cancers tissues. i.e., {(D2 | D3) ≥ D4 ≥α}
Preliminaries(cont) • Relationship factors: • X ≥ α (X > α) indicates that X is no less than α ( X is larger than α) • X ≤ α ( X < α) indicates that X is no larger than α ( X is less than α) • Operators: • X + Y indicates the operation of summing up the support values in both X and Y • X - Y indicates the operation of subtracting the support in Y from the support in X. • X & Y (X | Y) indicates the operation of X and Y ( X or Y) • |X| indicates the absolute support value in X • {ME > (NH | VT) >MA > (CT | RI) ≥α}
Preliminaries(cont) • Hybrid Frequent Pattern Tree Construction
Preliminaries(cont) • 3 • D1, D2, D3,…., DM • Denoting Rji the ranking order of item Ij in database Di • 3 • Si is the number of transactions in Di • S=S1+S2+..+SM
Discovering relational patterns • User Query Decomposition • All decomposed sub queries are placed into a Down Closure (DC) subset. • For example, the query {A ≥ B ≥ C ≥α} can be decomposed into three sub queries (A ≥α ), (B ≥α ), and (C ≥α ), and placed into the DC set. • A sub query like {(A+B+C) ≥α} complies with the down closure property, and can be directly put into the DC set.
Discovering relational patterns(cont) • Relational Pattern Discovery Using HFP-tree • Start from each of ai’s locations and track upwards towards the root. • Start from g, tracking from g upwards towards • the Root will produce a set {ecba}.
Discovering relational patterns(cont) • Replace the support of each item in the set by the current support and it will produce a path called hybrid prefix path (HPP). • {e | 1:0, c | 1:0, b | 1:0, a | 1:0}、{d | 1:1, b | 1:1, a | 1:1}、…….
Discovering relational patterns(cont) • Sum up all HPP’s frequencies. • Freqg={a | 4:2, b | 2:1, c | 2:2, d | 3:2, e | 1:0, f | 1:2}. • Dividing all the frequency values by the total number of transactions in each database. • D1=8 and D2=7, • Supg=={a | 0.5:0.29, b | 0.25:0.14, c | 0.25:0.29, d | 0.38:0.29, e | 0.13:0, f | 0.13:0.29}
Discovering relational patterns(cont) • User Query Decomposition • Q={D1 ≥ D2 ≥ 0.25} • DC={(D1 ≥ 0.25) AND (D2 ≥ 0.25)} • Comparing all items’ support values in Supi with the DC set will explicitly indicate that any of the following items • {b | 0.25:0.14}, {e | 0.13:0}, and {f | 0.13:0.29}
Discovering relational patterns(cont) • Prune out those unqualified items directly with filtered HPPs and build a Meta HFP-tree. • {c | 1:0, a | 1:0}, {d | 1:1, a | 1:1}, {d | 0:1, c | 0:1, a | 0:1}, {d | 1:0, c | 1:0, a | 1:0}, {d | 1:0, a | 1:0}, and {c | 0:1}
Discovering relational patterns(cont) • The mining process recursively calls the HFP-growth procedure, until the meta HFP-tree eventually contains one path only.
Discovering relational patterns(cont) • The recursive HFP-growth process will eventually lead to a meta HFP-tree containing one or zero path. At this stage, there is no need to grow patterns any further. • means the support value of the kth item in P and K is the number of items in P. • P={g | 4:3, d |3:2, a |3:2} then choose 3:2 • PSup={0.38:0.28}, which satisfy Q={D1 ≥ D2 ≥ 0.25},
Conclusion • SPV, PPM and CPM are all Apriori-based. DRAMA is FP-tree based. • We can see that DRAMA consistently outperforms both SPV and CPM with a significant runtime improvement. • Use it in streams ?