Download
1 / 44
460 likes | 976 Views
SIECI NEURONOWE. Wykład III. Wprowadzenie w tematykę sieci neuronowych.

E N D
SIECI NEURONOWE Wykład III
Wprowadzenie w tematykę sieci neuronowych Sieć neuronowa jest paradygmatem matematycznym modelującym czynności biologicznego systemu neuralnego i służącym do obliczeń. W 1943 roku McCulloch, neurobiolog, i Pitts, statystyk, opublikowali papier zatytułowany „A logical calculus of ideas imminent in nervous activity.” w biuletynie bio - fizyki matematycznej. Papier ten zainspirował rozwój nowoczesnych komputerów, lub jak nazwał je John von Neumann „mózgów elektronicznych”. W mniej więcej tym samym okresie Frank Rosenblatt zainspirowany tą publikacją rozpoczął badania nad modelem matematycznym oka, co ostatecznie doprowadziło do opisania pierwszej generacji sieci neuronowych, znanych pod nazwą perceptronów.
PODSTAWY BIOLOGICZNE DZIAŁANIA NEURONU Jako obiekt badań sieci neuronowe stanowią bardzo uproszczony, ale bogaty i ciekawy model rzeczywistego biologicznego systemu nerwowego - pewnych fragmentów naszego mózgu. Podstawowym elementem strukturalnym, z którego buduje się sieci neuronowe są sztuczne neurony. Ich pierwowzorem są komórki neuronowe budujące mózg człowieka. Każdy z neuronów jest specjalizowaną komórką biologiczna, mogącą przenosić i przetwarzać złożone sygnały elektrochemiczne.
Rys. 1 Budowa biologicznego neuronu Jądro - "centrum obliczeniowe" neuronu. Akson - "wyjście" neuronu. Wzgórek aksonu - stąd wysyłany jest sygnał wyjściowy. Dendryt – „wejście” neuronu. Synapsa - . Może ona zmienić moc sygnału napływającego poprzez dendryt.
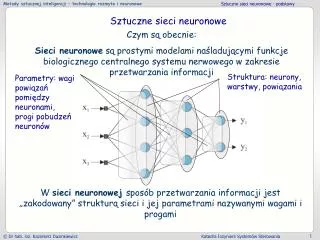
Model neuronu McCulloch’a i Pitts’a. Wszystkie z wielu istniejących modeli sieci neuronowych opisanych w przeciągu 50 lat od ich wymyślenia posiadają wspólny element znany pod nazwą neuronu oraz połączenia o strukturze sieciowej pomiędzy neuronami. Wejścia to dendryty, lub ściślej: sygnały przez nie nadchodzące. Wagi to cyfrowe odpowiedniki modyfikacji dokonywanych na sygnałach przez synapsy. Blok sumujący to odpowiednik jądra, blok aktywacji to wzgórek aksonu, a wyjście - to akson. Zaznaczam, że fakt, iż na rysunku są trzy dendryty, jest czysto przypadkowy.
Model neuronu McCulloch’a i Pitts’a. Na przedstawionym rysunku, każdy z neuronów składa się z funkcji sieci i funkcji aktywacji. Funkcja sieci określa w jaki sposób wejścia sieci { yj; 1 ≤ j ≤ N }są łączone wewnątrz neuronu. Na rysunku jest przedstawiona kombinacja liniowa opisana wzorem { wj ; 1 ≤ j ≤ N } są parametrami nazywanymi wagami synaptycznymi. Wielkość jest nazywana biasem lub progiem.
W literaturze zostały opisane inne metody kombinacji wejścia, są one zestawione w tabeli poniżej:
Wyjście neuronu, oznaczone przez ai na powyższym rysunku jest powiązane z wejściem neuronu o oznaczeniu ui poprzez liniowe lub nieliniowe przekształcenie zwane funkcją aktywacji: a = f(u) Tabela przedstawia zarówno funkcje aktywacji jak i ich pochodne (o ile takowe istnieją). Zarówno w przypadku funkcji sigmoidalnej jak i tangensa hiperbolicznego pochodna może być obliczona wprost na podstawie znajomości f(u).
funkcja Wzór funkcji Wzór pochodnej Sigmoida Tangens hiperboliczny Sinusoida Cosinusoida (bez nazwy) Tabela 1wzory nieliniowych funkcji aktywacji i ich pochodnych
Ryscharakterystyki sigmoidalnych funkcji aktywacji Rys funkcja aktywacji liniowa i skoku jednostkowego
Wybór funkcji aktywacji zależy od rodzaju problemu jaki stawiamy przed siecią do rozwiązania. Dla sieci wielowarstwowych najczęściej stosowane są funkcje nieliniowe, gdyż neurony o takich charakterystykach wykazują największe zdolności do nauki, polegające na możliwości odwzorowania w sposób płynny dowolnej zależności pomiędzy wejściem a wyjściem sieci. Umożliwia to otrzymanie na wyjściu sieci informacji ciągłej a nie tylko postaci: TAK - NIE.
Topologia sieci neuronowej. • Wymagane cechy funkcji aktywacji to: • ciągłe przejście pomiędzy swoją wartością maksymalną a minimalną (np. 0 - 1) • łatwa do obliczenia i ciągła pochodna • możliwość wprowadzenia do argumentu parametru beta do ustalania kształtu krzywej • Najczęściej stosowanymi są funkcje: sigmoidalna zwana też krzywą logistyczną ( o charakterze unipolarnym; przyjmuje ona wartości pomiędzy 0 a 1 ) oraz tangens hiperboliczny (o charakterze bipolarnym; wartości pomiędzy -1 a 1). Oczywiście każdą z nich można przeskalować tzn. sigmoidę do bipolarnej a tangensoidę do unipolarnej.
Topologia sieci neuronowej. W sieci neuronowej wiele neuronów jest połączonych ze sobą wzajemnie dla przeprowadzenia obliczeń rozproszonych. Konfiguracja wzajemnych połączeń może być opisana za pomocą grafu skierowanego. Graf skierowany składa się z węzłów (w przypadku sieci neuronowych z neuronów jak i wyjść) i krzywych skierowanych (w przypadku sieci neuronowych są to połączenia synaptyczne). Topologia może być skategoryzowana zarówno jako cykliczna lub acykliczna. Sieć neuronowa z topologią acykliczną nie posiada pętli sprzężenia zwrotnego. Tego rodzaju sieć neuronowa jest używana najczęściej do nieliniowej aproksymacji pomiędzy jej wejściami i wyjściami.
Jak pokazano na rys. cykliczna sieć neuronowa zawiera co najmniej jedno połączenie utworzone przez krzywą skierowaną. Sieć taka jest także znana pod nazwą sieci rekurencyjnej. Posiadanie przez sieć rekurencyjną pętli sprzężenia zwrotnego prowadzi do stworzenie systemu modelowania nieliniowego zawierającego pamięć wewnętrzną. Rekurencyjne sieci neuronowe często charakteryzują się skomplikowanym zachowaniem i pozostają do dzisiejszego dnia poważnym przedmiotem badań w dziedzinie sieci neuronowych. (a) topologia acykliczna (b) topologia cykliczna
Topologia sieci neuronowej. • W sieci neuronowej możemy rozróżnić kilka rodzajów neuronów: • warstwy wejściowej • warstw ukrytych • warstwy wyjściowej • z tym, że jest to podział bardziej formalny niż merytoryczny, gdyż różnice funkcjonalne pomiędzy tymi typami raczej nie występują. Można natomiast stosować w różnych warstwach różne funkcje aktywacji i współczynniki beta.
PODSTAWOWE ARCHITEKTURY SIECI NEURONOWYCH • Sposoby połączenia neuronów między sobą i ich wzajemnego współdziałania spowodowały powstanie różnych typów sieci. Każdy typ sieci jest z kolei ściśle powiązany z odpowiednią metodą doboru wag (uczenia). • Sieć jednokierunkowa jednowarstwowa • Właściwości sieci: • W sieci tej neurony ułożone są w jednej warstwie, zasilanej jedynie z wejść. • Połączenie węzłów wejściowych z neuronami warstwy wyjściowej jest zwykle pełne (każde wejście jest połączone z każdym neuronem). • Przepływ sygnałów występuje w jednym kierunku, od wejścia do wyjścia.
Węzły wejściowe nie tworzą warstwy neuronów ponieważ nie zachodzi w nich żaden proces obliczeniowy. • Sieć tego rodzaju nazywa się perceptronem jednowarstwowym. neurony warstwy wyjściowej Węzły wejściowe Rys chemat jednokierunkowej jednowarstwowej sieci neuronowej
Sieć jednokierunkowa wielowarstwowa • Właściwości sieci: • Występuje co najmniej jedna warstwa ukryta neuronów, pośrednicząca w przekazywaniu sygnałów miedzy węzłami wejściowymi a warstwą wyjściową. • Sygnały wejściowe są podawane na pierwszą warstwę ukrytą neuronów, a te z kolei stanowią sygnały źródłowe dla kolejnej warstwy. • Sieci jednokierunkowe wielowarstwowe wykorzystują najczęściej funkcję aktywacji o nieliniowości typu sigmoidalnego. • Sieć tego rodzaju nazywana jest perceptronem wielowarstwowym.
Rys Schemat jednokierunkowej wielowarstwowej sieci neuronowej.
Zostało udowodnione, że przy odpowiedniej liczbie neuronów, sieć MLP posiadająca tylko dwie warstwy ukryte jest zdolna do aproksymacji dowolnie złożonego odwzorowania – określa się taką sieć neuronową terminem uniwersalnego aproksymatora..
Nauka sieci MLP przy użyciu algorytmu wstecznej propagacji. Kluczowym problemem w zastosowaniu sieci MLP jest dobranie odpowiedniej macierzy wag. Zakładając warstwową strukturę sieci MLP, wagi przekazujące dane do każdej kolejnej warstwy sieci tworzą macierz wag (warstwa wejścia nie posiada wag z uwagi na brak neuronów w tej warstwie). Wartości tych wag są obliczane przy użyciu algorytmu nauczania ze wsteczną propagacją.
Znajdowanie wag dla przypadku sieci MLP składającej się z pojedynczego neuronu. Dla wygody, rozważymy prosty przypadek sieci składającej się z pojedynczego neuronu w celu zilustrowania tej metody. Dla uproszczenia wyjaśnień rysunek przedstawia neuron rozdzielony na dwie części: część sumacyjną obliczającą funkcję sieci u, oraz nieliniową funkcję aktywacji z = f(u).
Wyjście z jest porównywane z pożądaną wartością celu d, a ich różnica e = d – z, jest obliczana. Istnieją dwa wejścia x1 oraz x2 z odpowiadającymi im wagami w1, w2. Wejście oznaczone stałą ‘1’ jest biasem oznaczanym na poprzednich rysunkach za pomocą symbolu . Na tym rysunku bias jest oznaczony symbolem w0. Funkcja sieci jest obliczana na podstawie wzoru: gdzie x0 = 1, W = [ w1 w2 w3 ] jest macierzą wag i x = [ 1 x1 x2 ]T jest wektorem wejściowym.
Mając do dyspozycji zestaw przykładów do nauki sieci {(x(k),d(k));1≤k≤K}, nauka sieci MLP ze wsteczną propagacją błędu rozpoczyna się od podania na wejście sieci K przykładów i obliczenia odpowiednich wyjść{z(k);1≤k≤K}. W tym przypadku używamy początkowego oszacowania dla macierzy wag. Następnie suma błędów kwadratowych jest obliczana na podstawie wzoru: Celem jest dopasowanie macierzy wag W tak by zmniejszyć błąd E. Prowadzi to do problemu nieliniowej optymalizacji metodą najmniejszych kwadratów. Istnieje wiele algorytmów optymalizacyjnych, które można zastosować do rozwiązania tego problemu.
Zazwyczaj te algorytmy opierają się na podobnej iteracyjnej zależności: Gdzie W(t) jest korektą bieżących wartości wag W(t). Różne algorytmy używają odmiennych form W(t). Ta część koncentruje się na metodzie ‘najwyższego spadku gradientu’, która jest także podstawą algorytmu nauczania ze wsteczną propagacją. Pochodna skalarnej wielkości E z uwzględnieniem poszczególnych wag jest obliczana w następujący sposób: dla i = 0, 1, 2...
gdzie: Stąd: Podstawiając powyższe równanie może być wyrażone jako:
δ(k) jest błędem sygnału e(k) = d(k) – z(k) modulowanego przez pochodną funkcji aktywacji f’(u(k)) i w związku z tym przedstawia wielkość korekty potrzebnej do zastosowania względem wagi wi dla przykładu xi(k). Wynikający z tego wzór korekty wagi ma postać: Jeżeli użyjemy funkcji sigmoidalnej to δ(k) jest obliczane jako:
Należy zauważyć, że pochodna f’(u) może być obliczona dokładnie bez użycia aproksymacji. Wagi zostają poprawiane w każdej epoce. W tym przypadku K przykładów do nauki sieci jest użytych do poprawienia wartości wag jeden raz. W związku z tym mówimy, że ilość epok jest równa K. W praktyce, ilość epok może się wahać od jednej do max ilości przykładów.
Wsteczna propagacja w sieci MLP Jak dotąd zostało omówione jak dopasować wagi sieci składającej się z pojedynczego neuronu. Ta sekcja opisuje sposób nauczania sieci składającej się z wielu neuronów. Na początek kilka nowych oznaczeń zostaje wprowadzonych na podstawie, których będzie dokonywanie rozróżnienie neuronów na różnych warstwach sieci. Na rysunku poniżej funkcja sieci i wyjście odpowiadające k - temu przykładowi j – tego neuronu (L – 1) – tej warstwy są oznaczone jako oraz . Warstwa wejściowa jest oznaczona jako warstwa zerowa.
W szczególności . Wyjście jest podane do i – tego neuronu L – tej warstwy poprzez wagę synaptyczną oznaczoną , lub dla uproszczenia ponieważ będziemy się zajmować wzorem na korektę wagi dla pojedynczej epoki nauczania.
Aby znaleźć równanie adaptacji wagi, należy obliczyć W powyższym równaniu wyjście może zostać obliczone poprzez zaprezentowanie k – tego przykładu x(k) na sieć MLP z wagami ustawionymi do . Jednakże błąd nie jest znany i musi być obliczony osobno. Przypominamy, że błąd jest równy . Rysunek poniżej przedstawia jak w sposób iteracyjny oblicza się z oraz z wag (L + 1) – tej warstwy sieci.
Należy zauważyć, że jest podawane do wszystkich M neuronów (L + 1) - tej warstwy sieci Stąd:
Równanie z poprzedniego slajdu opisuje wsteczną propagację, która oblicza zmianę błędu wstecz od warstwy wyjściowej w kierunku do warstwy wejściowej, przechodząc od warstwy do warstwy.
Dopasowanie wartości wag z uwzględnieniem momentu i szumu. Znając wartość zmiany błędu, wagi zostaną dopasowane do zmodyfikowanej zależności opisującej wartość wag: Po prawej stronie równania, drugie wyrażenie jest gradientem średniego błędu kwadratowego obliczonego względem
Trzeci człon jest określany mianem momentu. Zapewnia on mechanizm do adaptacyjnego dopasowywania rozmiaru kroku. Gdy wektory gradientów w kolejnych epokach wskazują na ten sam kierunek, efektywny rozmiar kroku będzie się zwiększać (nabierać momentu). Kiedy kolejne wektory gradientów tworzą ścieżkę poszukiwania o kształcie łamanej, kierunek gradientu będzie regulowany przez ten człon momentu w celu zminimalizowania średniego błędu kwadratowego.
Istnieją dwa parametry, których wartości muszą zostać określone: stopień uczenia (lub rozmiar kroku , oraz stała momentu μ. Oba te parametry powinny mieć wartości z zakresu [ 0 1 ]. W praktyce często przyjmuje mniejsze wartości, np. 0 < < 0.3, a μ jest zazwyczaj większe, np. 0.6 < μ < 0.9. Ostatni człon opisuję losowy szum, który ma małe znaczenie jeżeli drugi lub trzeci człon mają większe wartości. Kiedy poszukiwanie kryterium podziału osiąga lokalne minimum lub płaszczyznę, wielkość odpowiadającego mu wektora gradientu lub wartości momentu najprawdopodobniej obniży się. W takiej sytuacji człon szumu może pomóc algorytmowi uczenia wyjść z lokalnego minimum i kontynuację poszukiwania globalnie optymalnego rozwiązania.
W trakcie uczenia sieci często utykają w minimach lokalnych, dla których wartości sygnałów wyjściowych sieci y różnią się znacznie od wartości żądanych d tych sygnałów. Mówi się wówczas, że sieć nie została prawidłowo nauczona. Utykanie to jest spowodowane wielomodalnością funkcji celu, która wobec założonych nieliniowych zależności obowiązujących wewnątrz sieci, może charakteryzować się ogromną liczbą minimów lokalnych. Poniższy rysunek (po lewej) przedstawia trójwymiarowy wykres funkcji celu zdefiniowanej jako błąd średniokwadratowy Dla jednego neuronu o 2 wagach W0 i W1 realizujących dwu klas danych.
Na rysunku (po prawej) odpowiadający mu wykres linii ekwipotencjalnych. W zależności od punktu startu trajektoria rozwiązania zdąża albo do minimum globalnego na środku wykresu, albo trafia na wąską dolinę wyprowadzającą rozwiązanie poza zakres objęty rysunkiem
Przykład sieci neuronowej w matlabie %Program – projekt sieci neuronowej typu BP o dwóch warstwach. %definicja wektora wejściowego; P= [0:5:85]; %definicja wektora celu T=[0 20 47 67 83 93 96 93 88 83 75 60 35 15 3 0 0 0 ] % inicjalizacja sieci S1 = 65; %ilość neuronów warstwy pierwszej [w1,b1,w2,b2] = initff(P,S1,’tansig’,T,’purelin’); %przyjęcie wartości wag i biasów w1 b1 w2 b2 %trening sieci; % Parametry treningu; df = 100; me = 8000; eg = 0.02; lr = 0.0001; tp = [df me eg lr]; %trwa trening sieci. [w1,b1,w2,b2,ep,tr] = trainbp(w1,b1,’tansig’,w2,b2,’purelin’,P,T,tp); A = simuff(P, w1,b1,’tansig’,w2,b2,’purelin’) echo off
Przykład wykorzystanie sieci neuronowych Aproksymacja funkcji Punkty co 10mm; S1= 40 (neurony); 5000 epok
Punkty co 5mm; S1 = 10; 5000 epok
5mm; 50 neuronów; 5000 epok