Download

1 / 72
800 likes | 1.11k Views
COM503 Parallel Computer Architecture & Programming. Lecture 2. Snoop-based Cache Coherence Protocols. Prof. Taeweon Suh Computer Science Education Korea University. Flynn’s Taxonomy. A classification of computers , proposed by Michael J. Flynn in 1966

E N D
COM503 Parallel Computer Architecture & Programming Lecture 2. Snoop-based Cache Coherence Protocols Prof. Taeweon Suh Computer Science Education Korea University
Flynn’s Taxonomy • A classification of computers, proposed by Michael J. Flynn in 1966 • Characterize computer designs in terms of the number of distinct instructions issued at a time and the number of data elements they operate on Source: Widipedia
Flynn’s Taxonomy (Cont.) • SISD • Single Instruction Single Data • Uniprocessor • Example: Your desktop (notebook) computer before the spread of dual or more core CPUs • SIMD • Single Instruction Multiple Data • Each processor works on its own data stream • But all processors execute the same instruction in lockstep • Example: MMX and GPU Picture sources: Wikipedia
SIMD Example • MMX (Multimedia Extension) • 64-bit registers == 2 32-bit integers, 4 16-bits integers, or 8 8-bit integers processed concurrently • SSE (Streaming SIMD Extensions) • 256-bit registers == 4 DP floating-point operations
Flynn’s Taxonomy (Cont.) • MISD • Multiple Instruction Single Data • Each processor executes different instructions on the same data • Not used much • MIMD • Multiple Instruction Multiple Data • Each processor executes its own instruction for its own data • Virtually, all the multiprocessor systems are based on MIMD Pic ture sources: Wikipedia
Multiprocessor Systems • Shared memory systems • Bus-based shared memory • Distributed shared memory • Current server systems (for example, Xeon-based servers) • Cluster-based systems • Supercomputers and datacenters
Clusters Supercomputer dubbed 7N (Cluster computer), 95th fastest in the world on the TOP500 in 2007 http://www.tik.ee.ethz.ch/~ddosvax/cluster/ https://www.jlab.org/news/releases/jefferson-lab-boasts-virginias-fastest-computer
Bus-based shared memory P P P $ $ $ Memory Distributed shared memory P P $ $ Memory Memory Interconnection Network Shared Memory Multiprocessor Models Our Focus today Fully-connected shared memory (Dancehall) P P P $ $ $ Interconnection Network Memory Memory
Some Terminologies • Shared memory systems can be classified into • UMA (Uniform Memory Access) architecture • NUMA (Non-Uniform Memory Access) architecture • SMP (Symmetric Multiprocessor) is an UMA example • Don’t be confused with SMT (Simultaneous Multithreading)
SMP (UMA) Systems Sandy Bridge based motherboard Antique (?) P-III based SMP P-III P-III $ $ Memory http://www.evga.com/forums/tm.aspx?m=1897631&mpage=1 http://news.softpedia.com/newsImage/Gigabyte-Also-Details-Its-Sandy-Bridge-Motherboard-Replacement-Program-2.jpg/
DSM (NUMA) Machine Examples • Nehalem-based systems with QPI Nehalem-based Xeon 5500 QPI: QuickPath Interconnect http://www.qdpma.com/systemarchitecture/SystemArchitecture_QPI.html
More Recent NUMA System http://www.anandtech.com/show/6533/gigabyte-ga7pesh1-review-a-dual-processor-motherboard-through-a-scientists-eyes http://ark.intel.com/products/64596/Intel-Xeon-Processor-E5-2690-20M-Cache-2_90-GHz-8_00-GTs-Intel-QPI http://www.intel.in/content/www/in/en/intelligent-systems/crystal-forest-server/xeon-e5-2600-e5-2400-89xx-ibd.html
Amdahl’s Law (Law of Diminishing Returns) • Amdahl’s law is named after computer architect Gene Amdahl • It is used to find the maximum expected improvement to an overall system • The speedup of a program using multiple processors in parallel computing is limited by the time needed for the sequential fraction of the program 1 Maximum speedup = (1 – P) + P / N • P: Parallelizable portion of a program • N: # processors Source: Widipedia
WB & WT Caches Writeback Writethrough CPU core CPU core Cache Cache X= 100 X= 300 X= 100 X= 300 Memory Memory X= 100 X= 100 X= 300
Definition of Coherence • Coherence is a property of a shared-memory architecture giving the illusion to the software that there is a single copy of every memory location, even if multiple copies exist • A multiprocessor memory system is coherent if the results of any execution of a program can be reconstructed by a hypothetical serial order P-III P-III $ $ Memory Modified Slide from Prof. H.H. Lee in Georgia Tech
Definition of Coherence • A multiprocessor memory system is coherent if the results of any execution of a program can be reconstructed by a hypothetical serial order • Implicit definition of coherence • Write propagation • Writes are visible to other processes • Write serialization • All writes to the same location are seen in the same order by all processes Slide from Prof. H.H. Lee in Georgia Tech
Why Cache Coherency? • Closest cache level is private • Multiple copies of cache line can be present across different processor nodes • Local updates (writes) leads to incoherent state • Problem exhibits in both write-through and writeback caches Core i7 CPU Core CPU Core .. Reg File Reg File L1 I$ (32KB) L1 D$ (32KB) L1 I$ (32KB) L1 D$ (32KB) L2 Cache (256KB) L2 Cache (256KB) L3 Cache (8MB) - Shared Slide from Prof. H.H. Lee in Georgia Tech
read? read? X= 100 X= 100 Writeback Cache w/o Coherence P P P write Cache Cache Cache X= 100 X= 505 Memory X= 100 Slide from Prof. H.H. Lee in Georgia Tech
Read? X= 505 X= 100 X= 505 Writethrough Cache w/o Coherence P P P write Cache Cache Cache X= 100 X= 505 Memory X= 100 Slide from Prof. H.H. Lee in Georgia Tech
Cache Coherence Protocols According to Caching Policies • Write-through cache • Update-based protocol • Invalidation-based protocol • Writeback cache • Update-based protocol • Invalidation-based protocol
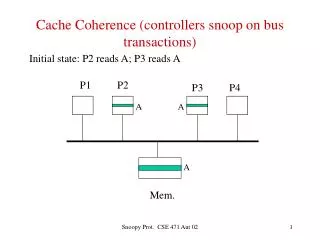
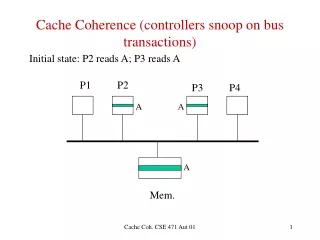
Bus Snooping based on Write-Through Cache • All the writes will be shown as a transaction on the shared bus to memory • Two protocols • Update-based Protocol • Invalidation-based Protocol Slide from Prof. H.H. Lee in Georgia Tech
Bus Snooping • Update-based Protocol on Write-Through cache P P P write Cache Cache Cache X= 505 X= 100 X= 505 X= 100 Memory Bus transaction X= 100 X= 505 Bus snoop Slide from Prof. H.H. Lee in Georgia Tech
X= 505 Bus Snooping • Invalidation-based Protocol on Write-Through cache P P P Load X write Cache Cache Cache X= 100 X= 100 X= 505 Memory X= 100 X= 505 Bus transaction Bus snoop Slide from Prof. H.H. Lee in Georgia Tech
Processor-initiated Transaction Bus-snooper-initiated Transaction A Simple Snoopy Coherence Protocol for a WT, No Write-Allocate Cache PrWr / BusWr PrRd / --- Valid PrRd / BusRd BusWr / --- Invalid Observed / Transaction PrWr / BusWr Slide from Prof. H.H. Lee in Georgia Tech
How about Writeback Cache? • WB cache to reduce bandwidth requirement • The majority of local writes are hidden behind the processor nodes • How to snoop? • Write Ordering Slide from Prof. H.H. Lee in Georgia Tech
Cache Coherence Protocols for WB Caches • A cache has an exclusive copy of a line if • It is the only cache having a valid copy • Memory may or may not have it • Modified (dirty) cache line • The cache having the line is the owner of the line, because it must supply the block Slide from Prof. H.H. Lee in Georgia Tech
update update Update-based Protocol on WB Cache • Update data for all processor nodes who share the same data • Because a processor node keeps updating the memory location, a lot of traffic will be incurred P P P Store X Cache Cache Cache X= 505 X= 505 X= 100 X= 100 X= 505 X= 100 Memory Bus transaction Slide from Prof. H.H. Lee in Georgia Tech
update update Update-based Protocol on WB Cache • Update data for all processor nodes who share the same data • Because a processor node keeps updating the memory location, a lot of traffic will be incurred P P P Store X Load X Cache Cache Cache X= 333 X= 505 X= 333 X= 505 X= 333 X= 505 Hit ! Memory Bus transaction Slide from Prof. H.H. Lee in Georgia Tech
invalidate invalidate Invalidation-based Protocol on WB Cache • Invalidate the data copies for the sharing processor nodes • Reduced traffic when a processor node keeps updating the same memory location P P P Store X Cache Cache Cache X= 100 X= 100 X= 505 X= 100 Memory Bus transaction Slide from Prof. H.H. Lee in Georgia Tech
Invalidation-based Protocol on WB Cache • Invalidate the data copies for the sharing processor nodes • Reduced traffic when a processor node keeps updating the same memory location P P P Load X Cache Cache Cache X= 505 X= 505 Miss ! Snoop hit Memory Bus transaction Bus snoop Slide from Prof. H.H. Lee in Georgia Tech
Invalidation-based Protocol on WB Cache • Invalidate the data copies for the sharing processor nodes • Reduced traffic when a processor node keeps updating the same memory location Store X P P P Store X Store X Cache Cache Cache X= 444 X= 987 X= 505 X= 333 X= 505 Memory Bus transaction Bus snoop Slide from Prof. H.H. Lee in Georgia Tech
MSI Writeback Invalidation Protocol • Modified • Dirty • Only this cache has a valid copy • Shared • Memory is consistent • One or more caches have a valid copy • Invalid • Writeback protocol: A cache line can be written multiple times before the memory is updated Slide from Prof. H.H. Lee in Georgia Tech
MSI Writeback Invalidation Protocol • Two types of request from the processor • PrRd • PrWr • Three types of bustransactions posted by cache controller • BusRd • PrRd misses the cache • Memory or another cache supplies the line • BusRdX (Read-to-own) • PrWr is issued to a line which is not in the Modified state • BusWB • Writeback due to replacement • Processor does not directly involve in initiating this operation Slide from Prof. H.H. Lee in Georgia Tech
PrRd / --- PrRd / --- PrWr / BusRdX PrRd / BusRd MSI Writeback Invalidation Protocol(Processor Request) PrWr / BusRdX PrWr / --- Modified Shared Invalid Processor-initiated Slide from Prof. H.H. Lee in Georgia Tech
BusRd / Flush BusRd / --- BusRdX / Flush BusRdX / --- MSI Writeback Invalidation Protocol(Bus Transaction) Modified Shared • Flush data on the bus • Both memory and requestor will grab the copy • The requestor get data from either • Cache-to-cache transfer; or • Memory Invalid Bus-snooper-initiated Slide from Prof. H.H. Lee in Georgia Tech
BusRd / Flush BusRd / --- BusRdX / Flush BusRdX / --- BusRd / Flush MSI Writeback Invalidation Protocol(Bus transaction) Another possible Implementation Modified Shared Invalid • Anticipate no more reads from this processor • A performance concern • Save “invalidation” trip if the requesting cache writes the shared line later Bus-snooper-initiated Slide from Prof. H.H. Lee in Georgia Tech
MSI Writeback Invalidation Protocol PrWr / BusRdX PrWr / --- PrRd / --- BusRd / Flush BusRd / --- Modified Shared PrRd / --- BusRdX / Flush BusRdX / --- PrWr / BusRdX Invalid PrRd / BusRd Processor-initiated Bus-snooper-initiated Slide from Prof. H.H. Lee in Georgia Tech
X=10 S --- --- BusRd Memory S MSI Example P1 P2 P3 Cache Cache Cache Bus BusRd MEMORY X=10 Processor Action State in P2 State in P3 Bus Transaction Data Supplier State in P1 P1 reads X Slide from Prof. H.H. Lee in Georgia Tech
X=10 X=10 S S BusRd --- --- S --- BusRd BusRd Memory Memory S S MSI Example P1 P2 P3 Cache Cache Cache Bus MEMORY X=10 Processor Action State in P2 State in P3 Bus Transaction Data Supplier State in P1 P1 reads X P3 reads X Slide from Prof. H.H. Lee in Georgia Tech
X=10 --- S I BusRdX --- --- S --- BusRd BusRd Memory Memory S S --- M BusRdX I MSI Example P1 P2 P3 Cache Cache Cache X=-25 S M X=10 Bus MEMORY X=10 Processor Action State in P2 State in P3 Bus Transaction Data Supplier State in P1 P1 reads X P3 reads X P3 writes X Slide from Prof. H.H. Lee in Georgia Tech
BusRd --- --- --- S BusRd BusRd Memory Memory S S --- --- M S BusRdX BusRd P3 Cache S I MSI Example P1 P2 P3 Cache Cache Cache S X=-25 --- I X=-25 M S Bus MEMORY X=-25 X=10 Processor Action State in P2 State in P3 Bus Transaction Data Supplier State in P1 P1 reads X P3 reads X P3 writes X P1 reads X Slide from Prof. H.H. Lee in Georgia Tech
X=-25 S BusRd --- --- S --- BusRd BusRd Memory Memory S S --- --- S S S M BusRd BusRd BusRdX P3 Cache Memory S I S MSI Example P1 P2 P3 Cache Cache Cache X=-25 S X=-25 S M Bus MEMORY X=10 X=-25 Processor Action State in P2 State in P3 Bus Transaction Data Supplier State in P1 P1 reads X P3 reads X P3 writes X P1 reads X P2 reads X Slide from Prof. H.H. Lee in Georgia Tech
MESI Writeback Invalidation Protocol • To reduce two types of unnecessary bus transactions • BusRdX that snoops and converts the block from S to M when only you are the sole owner of the block • BusRd that gets the line in S state when there is no sharers (that lead to the overhead above) • Introduce the Exclusive state • One can write to the copy without generating BusRdX • Illinois Protocol: Proposed by Pamarcos and Patel in 1984 • Employed in Intel, PowerPC, MIPS Slide from Prof. H.H. Lee in Georgia Tech
PrWr / --- PrRd, PrWr / --- PrRd / --- PrWr / BusRdX PrWr / BusRdX PrRd / BusRd (not-S) PrRd / --- PrRd / BusRd (S) MESI Writeback Invalidation (Processor Request) Exclusive Modified Invalid Shared S: Shared Signal Processor-initiated Slide from Prof. H.H. Lee in Georgia Tech
BusRd / Flush Or ---) BusRdX / --- BusRd / Flush BusRdX / Flush BusRd / Flush* BusRdX / Flush* MESI Writeback Invalidation Protocol(Bus Transactions) • Whenever possible, Illinois protocol performs $-to-$ transfer rather than having memory to supply the data • Use a Selection algorithm if there are multiple suppliers (Alternative: add an O state or force update memory) Exclusive Modified Invalid Shared Bus-snooper-initiated Flush*: Flush for data supplier; no action for other sharers Modified Slide from Prof. H.H. Lee in Georgia Tech
BusRdX / --- BusRd / Flush BusRdX / Flush BusRd / Flush* BusRdX / Flush* MESI Writeback Invalidation Protocol(Illinois Protocol) PrWr / --- PrRd, PrWr / --- PrRd / --- Exclusive Modified BusRd / Flush (or ---) PrWr / BusRdX PrWr / BusRdX PrRd / BusRd (not-S) Invalid Shared S: Shared Signal Processor-initiated Bus-snooper-initiated PrRd / --- Flush*: Flush for data supplier; no action for other sharers PrRd / BusRd (S) Slide from Prof. H.H. Lee in Georgia Tech
CPU0 CPU1 L2 L2 System Request Interface Crossbar Mem Controller Hyper- Transport MOESI Protocol • Introduce a notion of ownership ─ Owned state • Similar to Shared state • The O state processor will be responsible for supplying data (copy in memory may be stale) • Employed by • Sun UltraSparc • AMD Opteron • In dual-core Opteron, cache-to-cache transfer is done through a system request interface (SRI) running at full CPU speed Modified Slide from Prof. H.H. Lee in Georgia Tech
PrRd / --- PrRd / --- PrRd, PrWr / --- PrWr / --- PrWr / BusRdX PrRd / BusRd (not-S) PrWr / BusRdX PrRd / --- PrRd / BusRd (S) MOESI Writeback Invalidation Protocol(Processor Request) Exclusive Modified PrWr/ BusRdX Owned Invalid Shared S: Shared Signal Processor-initiated
BusRd / Flush (Or ---) BusRd / Flush BusRd/ Flush BusRdX/ Flush BusRdX / --- BusRd / Flush BusRdX/ Flush BusRd / Flush MOESI Writeback Invalidation Protocol(Bus Transactions) Exclusive Modified Owned Invalid Shared BusRd / Flush* BusRdX/ Flush* BusRd / --- BusRdX/ --- Bus-snooper-initiated Flush*: Flush for data supplier; no action for other sharers
BusRd / Flush BusRd/ Flush BusRdX/ Flush BusRdX / --- BusRdX/ Flush BusRd / Flush MOESI Writeback Invalidation Protocol(Bus Transactions) Exclusive Modified Owned Invalid Shared BusRd / --- BusRdX/ --- Bus-snooper-initiated