Download

1 / 21
230 likes | 400 Views
Basic Molecular Biology Information. Central Dogma of Molecular Biology. Concerns the flow of information in the cell. Nucleic Acids. Only 2 types: DNA and RNA linear chains of nucleotides DNA: 2 chains running anti-parallel twisted together into a double helix

E N D
Central Dogma of Molecular Biology • Concerns the flow of information in the cell.
Nucleic Acids • Only 2 types: DNA and RNA • linear chains of nucleotides • DNA: 2 chains running anti-parallel twisted together into a double helix • RNA: usually 1 chain of nucleotides, with secondary structure caused by base pairing between nucleotides on the same strand.
Nucleotides • Each nucleotide has 3 parts: sugar, phosphate, base. • Sugar is ribose (RNA) or deoxyribose (DNA) • Bases are attached to the 1’ carbon of the sugar • Base is purine or pyrimidine. • Purines: 2 carbon-nitrogen rings, adenine or guanine • Pyrimidines: 1 carbon-nitrogen ring, cytosine, thymine (DNA only), uracil (RNA only) • In the backbone, nucleotides are bonded together between the phosphate on the 5' carbon and the -OH on the 3' carbon. • Thus each nucleic acid has a free 5' phosphate on one end and a free 3' -OH on the other. • Used to write the polarity of the molecule: each nucleotide chain has a 5’ end and a 3’ end. • DNA has -H on 2' carbon of the sugar; RNA has -OH.
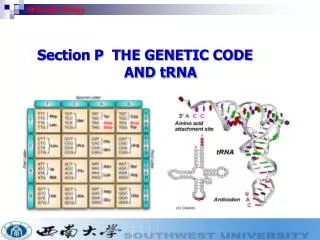
Base Pairing • A bonds with T (or U); G bonds with C. Held together by hydrogen bonds • A-T has 2 hydrogen bonds; G-C has 3. This makes G-C stronger and more stable at high temperatures. • In DNA, 2 antiparallel chains are held together by this pairing. • Implies that the amount of A = amount of T, and G = C in DNA. • But: GC content varies between species. Human DNA has 39.4% GC content (implying 60.6% A + T). • RNA is usually single stranded and held in a folded conformation by base pairing within the RNA molecule e.g. tRNA.
Replication • Main enzyme: DNA polymerase. Several other enzymes also involved (see below) • Replication is semiconservative: • DNA helix is opened up and unwound by a helicase • Each old strand gets a new strand built on it. • DNA polymerase can only add bases to the 3’ –OH group on a pre-existing nucleic acid that is base-paired with the template strand it is copying. This means that DNA synthesis starts with the enzyme primase synthesizing a short RNA primer. DNA polymerase then adds bases to this primer. • DNA polymerase can only add new bases to 3' end, so one strand is synthesized continuously (leading strand) and the other is built up of short fragments: discontinuous synthesis on the lagging strand. • The short (100-1000 bp ) DNA fragments, called Okazaki fragments, are built in the opposite direction of fork movement and then ligated together (by DNA ligase). • The whole process starts at several points on each chromosome and goes in both directions. Takes 8 hr to complete.
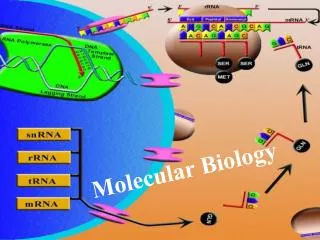
Transcription • Transcription is making an RNA copy of a short region of DNA. • Only part of the DNA is transcribed. A transcribed region is called a transcription unit, which is approximately equivalent to “gene”. • most transcription units code for proteins • some code for functional RNAs that never get translated into proteins (RNA genes). • When transcription starts, the DNA double helix is unwound and only one strand is used as a template for the RNA. • the template DNA strand is called the antisense strand, and the other DNA strand, not used in transcription is called the sense strand. This is because the sense strand has the same base sequence as the RNA transcript. Gene sequences are generally written as the sense strand. • Genes are oriented from 5' to 3' based on transcription direction (even though the template DNA is read 3' to 5'). Thus, 5' end of a gene is where transcription starts. Upstream and downstream also relate to this direction.
Transcription Process • The primary enzyme used for transcription isRNA polymerase • There are 3 types of RNA polymerase: pol2 does the protein coding genes, while pol1 and pol3 do ribosomal RNA and other structural RNA genes. • RNA polymerase binds to a promoter sequence just upstream from the transcription starting point, with the help of several proteins called transcription factors. • some transcription factors are used for all transcriptions, but others are very specific for cell type, hormonal stimulus, developmental time, etc. • RNA polymerase then moves in a 3’ direction, adding new RNA nucleotides to the growing RNA molecule.
Gene Regulation • Much of the control of gene expression occurs at the point of transcription. • Transcription regulation is based on interactions between transcription factors (proteins) and DNA sequences near the gene . • transcription factors are trans-acting: they diffuse freely through the cell and affect any DNA sequence they can bind to. • in contrast, DNA sequences near the gene are cis-acting: they can only affect transcription of the gene they are next to. (and not, for example, the same gene on the other homologous chromosome). • Types of cis-acting sequence: • promoters: several short regions within 100 bp of transcription start, especially the TATA box, which are all similar to TATAAA. • enhancers: can be up to several kilobases from the gene, either upstream or downstream, and in either orientation. Increase transcription level. • silencers: similar to enhancers, but opposite effect. • Genes are also affected by the region of chromosome they are in: some areas are highly condensed and unable to be transcribed (depending on cell type).
RNA Processing • The RNA molecule that results for RNA polymerase transcribing a gene is called a primary transcript. It is an exact copy of the DNA. Before it can be translated into protein, it must be processed, then transported to the cytoplasm. RNA processing has 3 steps: • Splicing out of introns, which are non-protein coding regions in the middle of protein-coding genes. . Most genes are interrupted by introns: up to 99% of the gene in some cases. Exons are the regions of genes that code for protein. Primary transcript contains introns, but spliceosomes (RNA/protein hybrids) splice out the introns. There are signals on the RNA for this, but it can vary between tissues (alternative splicing). • 5' cap: a 7-methyl guanine linked 5’ to 5’ with the first nucleotide of the RNA. • 3' poly A tail: several hundred adenosines added to 3’ end. Signal for poly A marks end of gene, but transcription continues past this without having a definite end point. All except histone genes have poly A. Stability of mRNA is probable reason for it. • After processing, the RNA is called messenger RNA, and it gets transported to the cytoplasm.
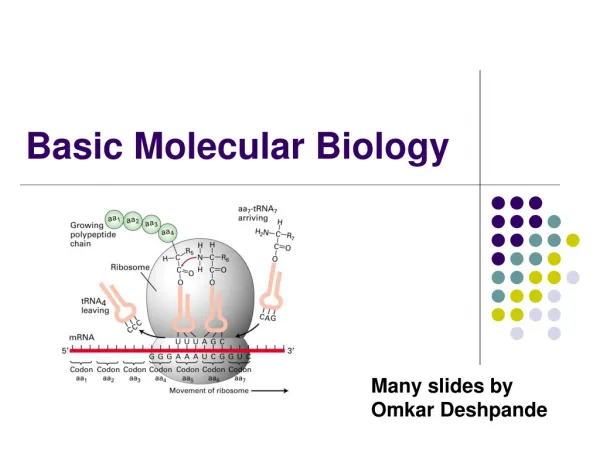
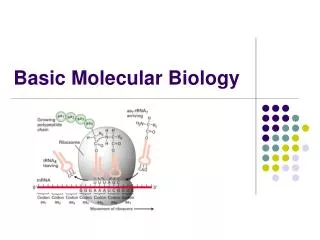
Translation • In cytoplasm, messenger RNA molecules are translated into polypeptides by ribosomes (RNA/protein hybrids). • Starts at first AUG in the messenger RNA, goes to first stop codon. (So, only one polypeptide per messenger RNA.) Open reading frame (ORF): region between a start codon and a stop codon. • Protein is synthesized from N terminus to C-terminus, based on free NH2 and COOH groups on the polypeptide. These correspond to the ribosome moving down the messenger RNA from 5’ end to 3’ end. • There are 5' and 3' untranslated regions (UTRs) on the RNA. • Most mRNA molecules are translated multiple times. • transfer RNA: short RNA molecules with several modified bases that act as adapters between codons on the mRNA and the amino acids.
Genetic Code • Three bases of DNA or RNA code for 1 amino acid = codon. • Since there are 4 bases, there are 43 = 64 codons. 61 of these code for amino acids, while the last 3 are stop codons that end the translation process. • Most amino acids have more than 1 possible codon: code is degenerate. Most variation is in third position of codon. • Nearly all organisms use the same code, with minor variations mostly in mitochondria and chloroplasts. • human mitochondria use a slightly altered genetic code • All translations start with ATG, methionine.
Proteins • Proteins: one or more polypeptides plus (optionally) co-factors • polypeptides: linear chain of amino acids, coded for by genes • co-factors: can be single atoms: metal ions commonly, or small organic molecules: heme, vitamins like riboflavin or biotin or thiamin
Amino Acids • Amino acid structure: amino group, acid group, side chain • amino covalently bonded to acid: peptide bond (= amide) • types of side chain: acidic, basic, uncharged polar, non-polar (some non-polar are very small and not very hydrophobic) • also: cysteine-cysteine bridges, proline-induced bends
Protein Structure • Classification of protein structure: • primary: amino acid sequence; • secondary : alpha helix, beta sheet, random coil (i.e. something more complex); • tertiary: overall shape of polypeptide; • quaternary: how all subunits and co-factors fit together.
Forces holding proteins together • primary structure = amino acids covalently bonded together • hydrogen bonds • based on electronegativity differences: C or H vs. O or N • H... H-O, both within the molecule and with water. • Involved in the 2 main secondary structural characteristics: alpha helix and beta pleated sheet (and beta turn), which involve interactions between C=O and NH2 groups of the peptide. • ionic bonds between charged groups (acidic, basic, polypeptide ends, co-factors) • hydrophobic forces. groups that can't form H-bonds with water tend to cluster together--they are excluded from the water, like oil droplets. Form interiors of proteins and membrane-spanning regions. • Van der Waals forces: very mild attraction of all atoms with strong repulsion if they get too close.
Protein folding • Mostly spontaneous to most stable configuration. • Some proteins are assisted by chaperone proteins, which also assist in recovery from heat shock by causing re-folding to proper configuration. Thus, chaperone proteins are also often called heat shock proteins. • However, predicting protein structure from the primary sequence is (so far) an unsolved and very difficult problem in biochemistry.
Post-translational modification • Addition of various groups: • Glycosylation: adding sugars. occurs in smooth ER. Mostly for proteins that are secreted or on outside of plasma membrane or inside of lysosomes. Large blocks of sugars added. Proteins called glycoproteins. • N-glycosylation : Occurs on asparigine (Asn). • O-glycosylation: On serine (Ser) or threonine (Thr) • Phosphorylation: adding phosphates. An important way to active various enzymes , especially for turning genes on and off. On serine, threonine, or tyrosine. • Adding lipids: so proteins get anchored to membrane. Various names depending on which lipid is added. For example, myristoyation, prenylation, palmitoylation, etc. Proteins called lipoproteins. • Others as well. • Cleavage. Often the N-terminal Met is removed. Other regions can also be removed: middle region of insulin, removal of signal peptides.
Localization • How do proteins get to the proper location in the cell? • Polypeptides often contain signal sequences that cause protein to end up in proper organelle, or be secreted, or become embedded in the membrane. Often a leader sequence (or signal sequence) at N terminus that is then removed. • Best known is for secretion into ER, into membrane, and extracellular: About 20 mostly hydrophobic amino acids at the N-terminus of the polypeptide. A Signal Recognition Particle (RNA/protein hybrid) recognizes this during translation and guides ribosomes to the rough ER where translation finishes. • Also signals for nucleus, lysosome, mitochondria. Some are internal to protein and not removed.