Download

1 / 25
260 likes | 387 Views
Zerlegung von Graphen. Gliederung:. Anwendungen Gewichtete Graphen Knotenseparator Kantenseparator Kernighan-Lin Algorithmus Fiduccia-Matteyes Algorithmus. Anwendungen. Probleme in Teilprobleme zu zerlegen um sie dadurch besser und schneller zu lösen

E N D
Gliederung: • Anwendungen • Gewichtete Graphen • Knotenseparator • Kantenseparator • Kernighan-Lin Algorithmus • Fiduccia-Matteyes Algorithmus
Anwendungen Probleme in Teilprobleme zu zerlegen um sie dadurch besser und schneller zu lösen z.B. Verteilung von Aufgaben gleichmäßig auf mehrere Prozessoren und gleichzeitig die Minimierung der notwendigen Kommunikation zwischen den Prozessoren
Es gibt viele Zerlegungsvarianten • Nach Anzahl der getrennten Kanten • Nach Anzahl der Knoten in den Teilgraphen
Graphen mit Gewichten Zerlegung des Graphen G = (V,E,Wv,We) • V = {v1, … , vn} Knoten • E = {e1k, … , eij} Kanten • Wv = Gewichte der Knoten • We = Gewichte der Kanten
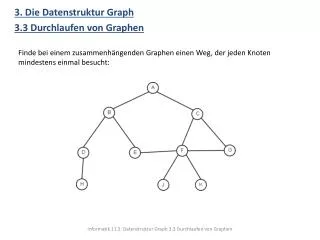
Separatoren Separatoren dienen zum Zerlegen eines Graphen, da diese den Graphen nach dem Entfernen teilen. Es gibt zwei Arten von Separatoren: • Knotenseparator • Kantenseparator
Knotenseparator Eine Knotenmenge C V zerlegt bzw. trennt einen Graph G = (V,E) in die Mengen A,B V , falls A,B,C eine Partitionierung von V ist und zwischen Knoten der Mengen A und B keine Kante existiert. In diesem Fall heißt das Tupel (A,B) Zerlegung und C trennende Knotenmenge des Graphen G. Ein Weg von einem Knoten aus A zu einem Knoten aus B muß über einen Knoten aus C laufen.
Kantenseparator Eine Kantenmenge Es E zerlegt bzw. trennt einen Graph G = (V,E) in die Mengen A,B V , falls A,B eine Partitionierung von V ist und zwischen Knoten der Mengen A und B nur Kanten der Menge Es existieren. In diesem Fall heißt das Tupel (A,B) Zerlegung und Es trennende Kantenmenge des Graphen G.
Der Kernighan-Lin Algorithmus I Der Kernighan-Lin Algorithmus verbessert eine vorgegeben Zerlegung G=A U B iterativ, in dem er versucht Gruppen von Knoten zwischen den Partitionen auszutauschen, so dass die Anzahl der Kanten zwischen A A und B minimiert wird. In der Praxis erreicht der Algorithmus bei einer guten Start-Zerlegung schnell ein Optimum.
Der Kernighan-Lin Algorithmus II gegeben Graph G=(V,E,We) und Zerlegung G= A U B in gleichgroße Teile. Das Ziel ist es gleichgroße Teilmengen X aus A und Y aus B zu finden, deren Vertauschung das Gesamtgewicht T aller Kanten zwischen A und B reduziert.
Der Kernighan-Lin Algorithmus III Man benötigt • E(a) = Summe aller Gewichte der Kanten zwischen a in A und Knoten in B → Externes Gewicht I(a) = Summe aller Gewichte der Kanten zwischen a und den restlichen Knoten in A → Internes GewichtD(a) = E(a)-I(a) Differenz der Kantengewichte intern und extern • anolog E(b), I(a), D(a)
Der Kernighan-Lin Algorithmus IV Das Vertauschen von a aus A und b aus B ergibt für newT:newT= T - ( D(a)+D(b) - 2*w(a,b)) = T - gain(a,b) gain(a,b) ist ein Maß für die Verbesserung der Zerlegung beim tausch von a und b, kann auch negativ sein
Kernighan-Lin Algorithmus 0. Berechne TRepeat1. Berechne D(n) für alle n2. Demarkiere alle Knoten in G3. while unmarkierte Knoten vorhanden Finde ein umarkiertes Paar (a,b) für das gain(a,b) maximal ist Markiere a und b Berechne D(n) für alle noch unmarkierten n endwhile ...nun gibt es eine Reihe von Paaren (a1,b1)...(ak,bk) und den entsprechende gains, gain(1)...gain(k) ...k=|V|/2 in der Reihenfolge, in der sie markiert wurden4. Wähle ein j, so daß Summe i=1..j der gain(i) maximal ist. 5. if die Summe > 0 ist dann A= A -(a1,...,aj) U (b1,....bj) B= B -(b1,...,bj) U (a1,....aj) ... Vertauschen der Knoten T=T-Summe endifAbbruch wenn Summe <=0
Fiduccia-Matteyes Algorithmus Unterschied zu Kernighan-Lin Algorithmus: Man vertauscht in jeder Iteration jeweils nur einen Knoten a oder b und lässt einen gewissen Unterschied in der Anzahl an Knoten pro Teilgebiet zu z.B. |A| < (1 + e)|B|, e ≈ 0,1 D(a) = Abnahme des „edge-cuts", falls man Knoten a in das Gebiet B verschiebt.
Fiduccia-Matteyes Algorithmus • 1 Repeat • 2 Compute edge-cut T = cost(A,B) for initial A,B • 3 Compute D(v) for initial A, B with V = A U B • 4 Initialize two queues (QA,QB) with highest D(v) on top • 5 Unmark all nodes in V • 6 While there are nodes v in queue QA,QB that can be moved • 7 v = TopNode(QA,QB) • 8 Mark node v and move it in the other subgraph • 9 Remove node v from selected queue QA or QB • 10 Update gains of adjacent vertices v • 11 Order priority queue QA and QB • 12 Update T = TD(v) ..O(j1j) • 13 Endwhile • 14 Until T 0
Fiduccia-Matteyes Algorithmus • Auswahl des Knoten v aus den Priority Queues QA und QB • 15 node v = TopNode(QA,QB) • 16 /* Auswahl des Knotens v aus QA oder QB */ • 17 a := TopNode in queue QA • 18 b := TopNode in queue QB • 19 /* Falls ein Teilgebiet gr¨osser als (1 + e) ist, • 20 dann w¨ahle Knoten v des kleineren Gebietes. */ • 21 if ((|A| > (1 + e)|B|) or (|B| > (1 + e)|A|)) then • 22 select the node v from smaller domain • 23 else • 24 if (D(a) < D(b)) select node b to move • 25 if (D(a) > D(b)) select node a to move • 26 if (D(a) = D(b)) select node from smaller domain • Graph-Partitionierung – p. 32/55
Zusammenfassung • Kernighan/Lin und FM benötigen eine Anfangs-Partitionierung V = A U B • – Ursprünglich nahm man eine zufällige erste Graph Partitionierung und verbesserte diese durch mehrere K/L-Iterationen (1972). • – Für grössere Probleme ist die Komplexität zu hoch →FM. • Es kann sein, dass „gain(k)" negativ ist, falls aber spätere „gains" positiv sind, dann • kann der endgültige Gewinn auch positiv werden. Damit ist gewährleistet, dass „lokale • Minima" überwunden werden können.
Quellen • http://informatik.unibas.ch/lehre/ss03/algorechnen/online/folien/lekt10.pdf • http://kbs.cs.tu-berlin.de/teaching/sose2005/cc/Folien/cc9_4.pdf • http://www.infosun.fmi.uni-passau.de/~chris/down/Partitionierungsverfahren.pdf • http://http.cs.berkeley.edu/~demmel/cs267/lecture18/lecture18.html