Download

1 / 18
180 likes | 404 Views
Prot é g é -2000. Prot é g é -2000 是美國 Stanford 大學 SMI ( Stanford medical informatics )研究所開發出來的一套本體論平台,它被定義成能夠減低知識擷取( Knowledge acquisition )障礙的一個工具。它擁有良好的介面,以利開發本體論工程,減少知識工作者在規劃或建立領域知識庫時所耗費的時間。它提供 Frame-base 的知識擷取,提供了一個開發推論引擎的環境,讓知識工作者可以架構一個健全的本體論系統。

E N D
Protégé-2000 • Protégé-2000 是美國Stanford 大學SMI ( Stanford medical informatics)研究所開發出來的一套本體論平台,它被定義成能夠減低知識擷取(Knowledge acquisition)障礙的一個工具。它擁有良好的介面,以利開發本體論工程,減少知識工作者在規劃或建立領域知識庫時所耗費的時間。它提供Frame-base 的知識擷取,提供了一個開發推論引擎的環境,讓知識工作者可以架構一個健全的本體論系統。 • 此外它也是一個Open source 的平台,此平台使用Java 程式語言所開發,任何人都可以更改其系統內部的Source code,所以使用者可以因應領域技術上的需求在系統裡加入所需的功能。
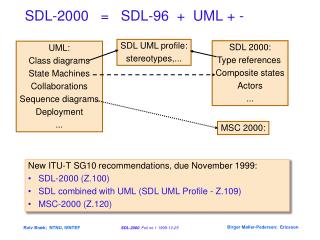
Protégé-2000 • Protégé-2000 系統的架構主要分為三層,分別是User Interface、Core Protégé-2000、Persistent Storage 所組成。 • 第一層User Interface 是和使用者最親近的一層,使用者可以在這層依據領域技術所需的功能定義自己的專有介面(widget),或者是以Plug-in 的方式在系統裡加入額外的介面功能。 • 第二層Core Protégé-2000 是系統的主要核心,它主要的功能是維持系統知識管理的階層架構以及關聯階層之間的推理。 • 第三層Persistent Storage 包含了二層,一層為儲存資料的實體,另一層為Knowledge-base Mapping,而Knowledge-base Mapping 這一層會將本體論及其實例對應到儲存資料的實體。
Protégé-2000 • Protégé-2000 的知識模組(Knowledge Model)裡包含了Class、Slot、Instance 三個主要的模組。 • Class 即類別,而Instance 則為實例,Slot 則稱為屬性或者稱關聯,其中Slot 的屬性是用於連結基本資料型態,而關聯所連結的則比較靈活,可以是一個Instance 或者Class,而Slot 的Constraint 稱作Facet。 • Protégé 2000支援本體論的主要元件有類別(Class) 及槽(Slot)。類別代表了知識的概念(Concept);槽描述類別的屬性(attributes)和關係(Relation)。屬性或關係差別在於屬性所連結的是基本資料型態,而關係所連結的可以是另一個Instance 或Class。知識實例則為Instance。類別與類別之間的關係除了支援一般化 (generalization)和特例化關係(specialization)之外,也支援Inverse Slot、Slot Override和多重繼承等。所謂的一般化和特例化關係是指類別間的階層關係,一般存在有繼承(Inherit)和實例(instance)的特性。Inverse Slot 是可以建立兩個相反Slot 的關聯,如”吃”與”被吃”;Slot Override可以在特定的Class 中建立同名異型的Slot;多重繼承為一個Class 可為多個Class 的子類別。
SMI知識本體發展程序 • (一)、決定領域和範圍,考慮知識本體所要涵蓋的領域為何、為什麼要用這個知識本體及何種型態的問題可由這個知識本體找到答案。 • (二)、考慮重複使用,包括內部及外部資源。為了避免重複開發、與其他知識本體互動及使用已被一些應用系統引用且驗證過的知識本體,如WordNet 與UMLS Semantic Net。 • (三)、列出重要的專用詞彙,思考會引用的詞彙有哪些、詞彙的屬性為何及會對這個詞彙談些什麼。 • (四)、定義類別及其層次結構,類別是領域的概念,是相似屬性要素的集合,而屬性值(Instance)即為概念的屬性值。下層與上層為子概念與父概念的層次關係(a subclass-superclass hierarchy),下層概念屬於(is-a)上層概念,蘋果是水果的子概念,所以蘋果屬於水果;紅酒是酒的子概念,所以紅酒屬於酒。多重繼承關係則一個父概念有多個子概念。一個子概念也可以有多個父概念,雜誌社的員工有專欄作家、編輯與記者;文章的作者有專欄作家、編輯與記者,專欄作家、編輯與記者屬於員工也屬於作者。
SMI知識本體發展程序 • (五)、定義屬性,描述概念屬性值的屬性及與其他屬性值間的關係。屬性的型態有本質的,如酒的氣味與顏色;外來的,如(b)酒的名稱與價錢。簡單屬性指原生的字串、數值、布林函數等;複合屬性則指包含或指向某一物件,如(c)酒(Wine)的製造商(maker)屬性指向酒廠(Winery)概念,而反過來酒廠(Winery)製造(produces)屬性指向了酒(Wine)概念,說明了不同物件可互為反向的複合屬性(Inverse Slot)。子概念繼承父概念所有屬性,子概念若有多個父概念,則繼承所有父概念的屬性。 • (六)、定義屬性值的條件限制,限定或描述可能的值之型態、個數及範圍。子概念雖繼承父概念所有的屬性,但子概念可窄化並覆蓋父概念所定義的值範圍,酒是法國酒的父概念、酒廠是法國酒廠的父概念,酒廠製造酒、法國酒廠製造法國酒。 • (七)、設定概念屬性值,建立知識本體最後程序為為概念屬性填上值,由於前一步驟已規範值的範圍與限制條件,所以若填入的值違反前項規範,可立刻由警示發現錯誤,一般知識整合工具都有提供此功能。
壽險客服文件知識本體 資料來源:簡月秀,2003
壽險知識本體 資料來源:簡月秀,2003
客服專員接到客戶來電查詢因嚴重急性呼吸道症候群(SARS)致死,可否獲得醫療費用與死亡保險金給付?客服專員接到客戶來電查詢因嚴重急性呼吸道症候群(SARS)致死,可否獲得醫療費用與死亡保險金給付?
降血脂藥物領域本體論 資料來源:黃崇益等,2007
降血脂藥物方法本體論 基本規則(P) • 基本規則可分為一般化準則(General Criteria)及數字型準則(Numeric Criteria)。描述基本規則的語法為,(P):= {領域值} + {運算子} + {邏輯值}。例如,P1 ::= Age > 45歲。我們可以用一個類別來表示一條基本規則,基本規則類別可以用六個特徵屬性(槽)來描述,以建立基本規則的實例。 • (1) SLOT 1_label(標籤值):描述基本規則實例的名稱,型別為字串(String) 。 • (2) SLOT 2_domain(領域值):描述其所屬上層領域類別,我們將基本規則在Protégé 2000歸類在Medical_Term類別下,型別為類別(Class)。 • (3) SLOT 3_operator(運算子):規則所需的運算子,以便作用於領域值及邏輯值,允許的運算子值為{>、>=、=、<=、<、eq、neq},型別為符號(Symbol)。 • (4) SLOT 4_Constraint_Value(特定條件值):可填邏輯值{true、false}或數值),型別為字串(String)。 • (5) SLOT 5_mapping table(表格對應值):型別為類別(Class),為SLOT 2_domain(領域值)所對應到系統工作記憶區暫存資料庫的表格名稱(table name)。 • SLOT 6_mapping field(欄位對應值):型別為類別(Class),為SLOT 4_Constraint_Value(特定條件值)對應到系統工作記憶區暫存資料庫的表格欄位名稱(table field name)。藉由slot 5和slot 6的定義,Protégé 2000可以從醫療資訊系統中獲取相對應的資料,支援基本規則實例的推論決策,達到連線檢核的目的。
降血脂藥物方法本體論 複合規則(C): • 複合規則(C)由兩個或兩個以上的基本規則(P)所組成。例如,病患心電圖檢查是否為缺血性(has anoxia EKG Findings),這是一條複合規則,因為它是由兩條基本規則「病患是否有做心電圖檢查(has EKG test)」及「病患心電圖檢查是否為缺血性(has EKG anoxia)」所組合而成。 • Protégé 2000我們將複合規則在置於N_ary_Criterion這個類別下,其父類別為複合規則(Composite Rules)。複合規則類別可以用三個特徵屬性(槽Slot)來描述,分別說明如下。 • (1) SLOT 1_label(標籤值):型別為字串(String),描述複合規則實體的名稱。 • (2) SLOT 2_operator(運算子):型別為符號(Symbol),允許的值為邏輯運算子{AND、OR、NOT}等。 • (3) SLOT 3_criteria(準則):實例名稱,型別為實例類別,不但包含基本規則,也包含複合規則。
降血脂藥物方法本體論 • 若病人沒有類似的心血管疾病,必須符合下列條件便可以使用降血脂藥物。 • 1. TG(Triglyceride中性脂肪濃度) >= 200mg/dl,並且需同時合併有TC/HDL-C>5或是HDL-C<40mg/dl ) • 2. 非藥物治療操過三個月且未達治療目標(TG < 200mg/dl)。 • 首先將規定分解成基本規則,分別命名為P1, P2, P3, 和P4。 • P1 ::= TG >= 200; • P2 ::= TC/HDL-C > 5; • P3 ::= HDL-C < 40; • P4 ::= absence of drug treatment before 3 months; • 其次定義複合規則,分別命名為C1, C2, C3, 和C4。 • C1 ::= P1 AND P2; • C2 ::= P1 AND P3; • C3 ::= P4 AND P1; • 最後由複合規則組成符合使用降血脂藥物的目標,命名為G1 (Give dyslipidemia drugs)。則G1 ::= (C1 OR C2) AND C3; 以Protégé 2000 建置的方法本體論 。