Download
1 / 1
100 likes | 464 Views
x. c. ×. /. +. y. s. ×. /. c. r 1. ×. r 1. s. +. r 2. ×. s. r 1. ×. r 2. c. ─. ×. r 2. State of the Art. Three types of previous implementations of Givens rotation for QR: [1] Square root free using Squared Givens Rotation (SGR) algorithm

E N D
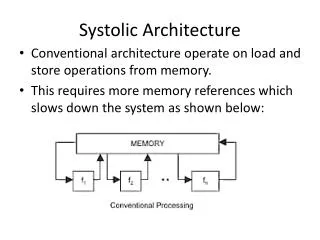
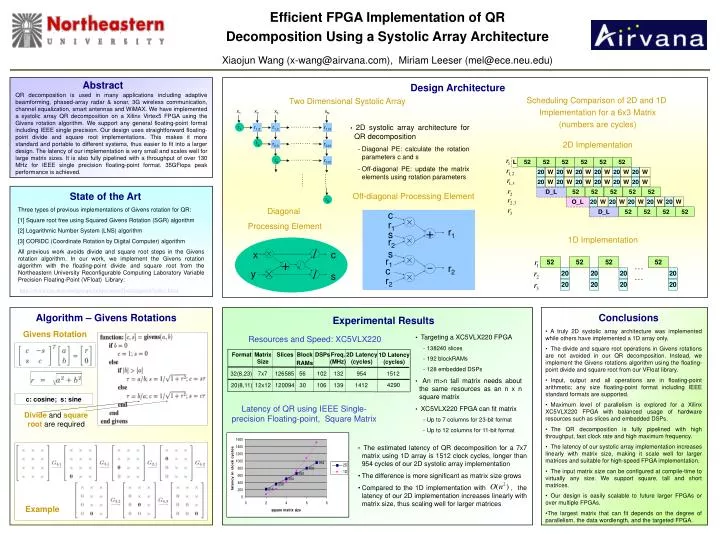
x c × / + y s × / c r1 × r1 s + r2 × s r1 × r2 c ─ × r2 State of the Art Three types of previous implementations of Givens rotation for QR: [1] Square root free using Squared Givens Rotation (SGR) algorithm [2] Logarithmic Number System (LNS) algorithm [3] CORIDC (Coordinate Rotation by Digital Computer) algorithm All previous work avoids divide and square root steps in the Givens rotation algorithm. In our work, we implement the Givens rotation algorithm with the floating-point divide and square root from the Northeastern University Reconfigurable Computing Laboratory Variable Precision Floating-Point (VFloat) Library: http://www.ece.neu.edu/groups/rcl/projects/floatingpoint/index.html Conclusions • A truly 2D systolic array architecture was implemented while others have implemented a 1D array only. • The divide and square root operations in Givens rotations are not avoided in our QR decomposition. Instead, we implement the Givens rotations algorithm using the floating-point divide and square root from our VFloat library. • Input, output and all operations are in floating-point arithmetic; any size floating-point format including IEEE standard formats are supported. • Maximum level of parallelism is explored for a Xilinx XC5VLX220 FPGA with balanced usage of hardware resources such as slices and embedded DSPs. • The QR decomposition is fully pipelined with high throughput, fast clock rate and high maximum frequency. • The latency of our systolic array implementation increases linearly with matrix size, making it scale well for larger matrices and suitable for high-speed FPGA implementation. • The input matrix size can be configured at compile-time to virtually any size. We support square, tall and short matrices. • Our design is easily scalable to future larger FPGAs or over multiple FPGAs. • The largest matrix that can fit depends on the degree of parallelism, the data wordlength, and the targeted FPGA. Efficient FPGA Implementation of QR Decomposition Using a Systolic Array Architecture Xiaojun Wang (x-wang@airvana.com), Miriam Leeser (mel@ece.neu.edu) Abstract Design Architecture QR decomposition is used in many applications including adaptive beamforming, phased-array radar & sonar, 3G wireless communication, channel equalization, smart antennas and WiMAX. We have implemented a systolic array QR decomposition on a Xilinx Virtex5 FPGA using the Givens rotation algorithm. We support any general floating-point format including IEEE single precision. Our design uses straightforward floating-point divide and square root implementations. This makes it more standard and portable to different systems, thus easier to fit into a larger design. The latency of our implementation is very small and scales well for large matrix sizes. It is also fully pipelined with a throughput of over 130 MHz for IEEE single precision floating-point format. 35GFlops peak performance is achieved. Scheduling Comparison of 2D and 1D Implementation for a 6x3 Matrix (numbers are cycles) Two Dimensional Systolic Array • 2D systolic array architecture for QR decomposition • Diagonal PE: calculate the rotation parameters c and s • Off-diagonal PE: update the matrix elements using rotation parameters 2D Implementation Off-diagonal Processing Element Diagonal Processing Element 1D Implementation Algorithm – Givens Rotations Experimental Results Givens Rotation • Targeting a XC5VLX220 FPGA • 138240 slices • 192 blockRAMs • 128 embedded DSPs • An m>n tall matrix needs about the same resources as an n x n square matrix • XC5VLX220 FPGA can fit matrix • Up to 7 columns for 23-bit format • Up to 12 columns for 11-bit format Resources and Speed: XC5VLX220 Format Matrix Size Slices Block RAMs DSPs Freq. (MHz) 2D Latency (cycles) 1D Latency (cycles) 1512 32(8,23) 7x7 126585 56 102 132 954 4290 20(8,11) 12x12 120094 30 106 139 1412 c: cosine; s: sine Latency of QR using IEEE Single-precision Floating-point, Square Matrix Divideandsquare root are required • The estimated latency of QR decomposition for a 7x7 matrix using 1D array is 1512 clock cycles, longer than 954 cycles of our 2D systolic array implementation • The difference is more significant as matrix size grows • Compared to the 1D implementation with , the latency of our 2D implementation increases linearly with matrix size, thus scaling well for larger matrices Example