Download

1 / 37
370 likes | 516 Views
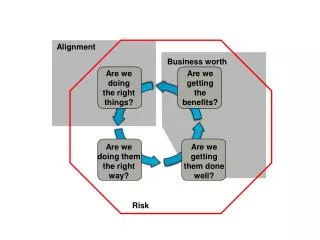
ALIGNMENT. How do we tell whether two macromolecules are similar? Why?. SEQUENCE STRUCTURE FUNCTION. Alignments. DNA:DNA polypeptide:polypeptide. Alignments. One-to-One One-to-Database Many-to-Many. Origins of Sequence Similarity. Homology common evolutionary descent

E N D
ALIGNMENT How do we tell whether two macromolecules are similar? Why? SEQUENCE STRUCTURE FUNCTION Chuck Staben
Alignments • DNA:DNA • polypeptide:polypeptide Chuck Staben
Alignments • One-to-One • One-to-Database • Many-to-Many Chuck Staben
Origins of Sequence Similarity • Homology • common evolutionary descent • Similarity in function • convergence • Chance History Necessity Serendipity Chuck Staben
MISMATCH Similarity GAACAAT ||||||| 7/7 OR 100% GAACAAT GAACAAT ||| ||| 6/7 OR 84% GAATAAT Chuck Staben
Mismatches GAACAAT ||| ||| 6/7 OR 84% GAATAAT Same?? GAACAAT ||| ||| 6/7 OR 84% GAAGAAT Chuck Staben
Count this? Terminal Mismatch GAACAATttttt ||| ||| aaaccGAATAAT 6/7 OR 84% Chuck Staben
INDEL INDELS GAAgCAAT ||| |||| 7/7 OR 100% GAA*CAAT (alignment-challenged?) Chuck Staben
vs. GAAggggCAAT ||| |||| GAA****CAAT Indels, cont’d GAAgCAAT ||| |||| GAA*CAAT Chuck Staben
Similarity Scoring • Terminal mismatches (0) • Match score (10) • Mismatch penalty (-9) • Gap penalty (50) • Gap extension penalty (3) DNA Defaults-Bestfit Chuck Staben
DNA Scoring GGGGGGGGGG |||||***** 5(10)-5(9)=5 GGGGGAAAAAGGGGG GGGGG*****GGGGG |||||***** ||||| 10(10)-50-5(3)=35 GGGGGAAAAAGGGGG Chuck Staben
Absurdity of Low Gap Penalty GATCGCTACGCTCAGC A.C.C..C..T Perfect similarity, Every time! Chuck Staben
Algorithms Optimal Score=Optimal Alignment Needleman-Wunsch Dynamic Programming Optimal Local Alignment Smith-Waterman Chuck Staben
Programs • BESTFIT • Smith-Waterman • SINGLE BEST SIMILARITY • GAP • Needleman-Wunsch • End-to-end ALWAYS • COMPARE/DOTPLOT • COMPLETE surface of comparison Chuck Staben
BESTFIT vs GAP 1 ggggg 5 ||||| 3 ggggg 7 1 ...gggggaaaaaggggccccc 19 || |||| || 1 gggggttttttttggggtttcc 22 Chuck Staben
Statistical Significance RaNdOmIzE Quality: 50 Length: 5 Similarity: 100.000 Identity: 100.000 Average quality, 20 randomizations: 34.2 +/- 9.4 Quality > RANDOM + 2() Chuck Staben
Program Limitations • BESTFIT • 1000 vs 10,000 • GAP • 1000 vs 1000 • COMPARE • 1000 vs 1000 Memory Chuck Staben
Protein Similarity • Identity-Easy WEAK Alignments • Chemical Similarity • L vs I, K vs R… • Evolutionary Similarity Chuck Staben
Single-Base Evolution CAU=H CAC=H CGU=R UAU=Y CAA=Q CCU=P GAU=D CAG=Q CUU=L AAU=N Chuck Staben
Substitution Matrices • PAM-Dayhoff • BLOSUM-Henikoff Chuck Staben
PAM-Dayhoff • Related proteins, substitutions constrained by evolution and function • “accepted” by evolution (point accepted mutation) • 1 PAM::1% divergence • PAM120=closely related proteins • PAM250=divergent proteins • Log/odds approach Chuck Staben
BLOSUM-Henikoff&Henikoff • Align “BLOCKS” • Merge blocks at given % similar to one sequence • Calculate “target” frequencies • BLOSUM62=62% similar blocks • good general purpose • BLOSUM30 • weak similarities Chuck Staben
BLOSUM62 Chuck Staben
BLOSUM62-2 Glu Asp Gln Lys Arg His Gly Ala GAA GAU CAA AAA AGA CAUGGA GCA GAG GAC CAG AAG AGG CACGGG GCG Chuck Staben
Gaps • No general theory!! • G+L(n) • indel mutations rare • variation in length “easy” Chuck Staben
Alignment Statistics • Ungapped, local alignments (HSPs) • extreme value, not normal distribution • S(observed score) vs expected distribution p • E=expected number, chance alignments • K, distribution parameters “chance of finding a needle in a haystack depends on the size of the haystack” Chuck Staben
“Real” Alignments • Multiple HSPs • Karlin-Altshcul Sum Statistics • Heuristic qualities • alignments proceed end-to-end ???? Chuck Staben
Real Alignments Protein-Protein Close-Distant DNA-DNA Chuck Staben
Phylogeny GCG Myoglobin Chuck Staben
Cow-to-Pig 88% identical Chuck Staben
Cow-to-Pig cDNA 80% Identity (88% at aa!) Chuck Staben
DNA similarity reflects polypeptide similarity Chuck Staben
Coding vs Non-coding Regions 90% in Coding 74% in Non-coding Chuck Staben
Third Base of Codon Hypervariable 28 third base 11 second 8 first Chuck Staben
Cow-to-Fish Protein 42% identity 51% similairity Chuck Staben
Cow-to-Fish DNA 48% similairity Significant Chuck Staben
Protein vs DNAAlignments • Polypeptide similarity > DNAs • Coding DNA > Non-coding • 3rd base of codon hypervariable • Moderate Distance poor DNA similarity Chuck Staben