Download

1 / 5
50 likes | 138 Views
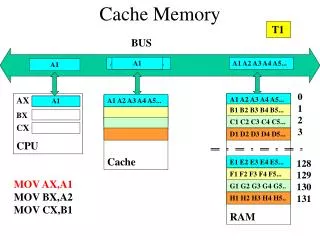
Cache memory. What? Small, but fast (SRAM) memory closest to the CPU registers in the memory hierarchy. Can be on the CPU (level 1 cache), or on the motherboard (level 2 cache, usually connected via a dedicated fast bus).

E N D
Cache memory • What? Small, but fast (SRAM) memory closest to the CPU registers in the memory hierarchy. Can be on the CPU (level 1 cache), or on the motherboard (level 2 cache, usually connected via a dedicated fast bus). • Why? Speed. Normal RAM memory is far too slow and connected to the CPU via a slow bus, relative to CPU speeds. The most important part of the memory hierarchy, for optimising the cost/ size/performance of computer memory. • Context? Relatively recent. Since 1990’s has become vital, since memory requirements are now much bigger and CPU speeds have way outstripped the rest of the system. We can now say that caches are the most important part of the computer for fast performance. • How? Cache works by keeping a local copy of the most frequently used data, which is therefore very quickly accessible to the CPU. When the CPU finds its data in the cache, that is a Hit (fast). When it doesn’t, that is a Miss which forces the CPU to get the data from main memory (slow). So cache Hit rate is very important. • Locality of reference Caches depend totally on this and would not work without it. Memory references (i.e. the sequence of addresses required from memory by the CPU) are clustered in time- i.e. the next few required addresses will be close in memory to the current one and to those of the recent past. This raises the ‘Hit Rate’ of the cache to well over 90%, usually. Locality of reference is a Software property, and will vary from one kind of software to another. So knowing about software characteristics is an important area of research (called Software Metrics)
CPU cache Main memory Single word transfer Block transfer Caches, more on How? • Basic idea • Main memory is divided into blocks ( of a few bytes - 8 or 16 or 32 etc) and the cache is divided into slots (sometimes called lines) of equal size. Data is then transferred between main memory and cache in block/slot sized chunks. • The CPU's memory management unit (MMU) has to check for a Hit or Miss in the cache and do all the follow through, every time a memory request is made by the CPU (i.e. almost at the clock speed!). So the MMU has to be a very fast bit of hardware. • Since the CPU might deal with data in the cache over some time, this copy of the data will become different from that held in main memory, so the main memory version (which must always be primary) needs to be updated - write through or write back.
Start RA is the Requested Address by the CPU * Policy required, unless Direct Mapped RA from CPU No Find RA’s block in main memory Allocate cache slot* Hit? Yes Fetch [RA] from cache Data [RA] to CPU Finish Load new block in cache MMU’s basic memory request cycle
Mappings - which main memory blocks go where in the cache • MM blocks have to locatable in the cache, obviously, so that the MMU knows where to look in the cache. This information comes from the mapping used. • Since there are always fewer cache slots than MM blocks, cache slots have to be shared, so MMU needs to know which particular MM block, out of the many possible, is currently actually in the cache. • Each cache slot therefore has a stored ‘Tag’. This identifies which particular MM block is currently resident, so enables the MMU to determine a Hit or a Miss. • Direct mapping. • Every MM block is allocated one fixed slot in the cache • So easy to implement in hardware • But the MM blocks which share the slot may be needed equally frequently and around the same time, so they will constantly be shoving each other out of the slot - causing lots of Misses.
Mappings - continued • Fully Associative Mapping • Every MM block can be placed in any slot in the cache. • The most flexible organisation - allows the maximum number of currently well used MM blocks to be in the cache at the same time. • But MMU needs to check the tags of all the cache slots to find out if the block it wants is resident, since the block might be anywhere (for a Hit) or not in the cache at all (for a Miss). • Since the MMU has to do this for every new RA, it must be done with very fast hardware (no time to look at all the cache tags sequentially). • The fast hardware to store cache tags and allow then to be examined in parallel is called Associative RAM and very very expensive - but you have (some) in your PC at home. • Set Associative Mapping, e.g. 2 way, 4 way 8 way etc • Is therefore a compromise. • Each MM block can be place in one of a limited set of cache slots (2,4,8 etc). • Experiment shows that fully associative caches are not needed • MM blocks are rarely excluded from the cache when they are still ‘current’ • There is less expensive associative RAM needed to make the cache. • As in associative mapping, when there is a Miss, somebody has to choose which cache slot to use, from the set and therefore which MM block to kick out of the cache. This requires some kind of policy, guided by extra bits kept in the tag, essentially telling how important the block currently in residence is.