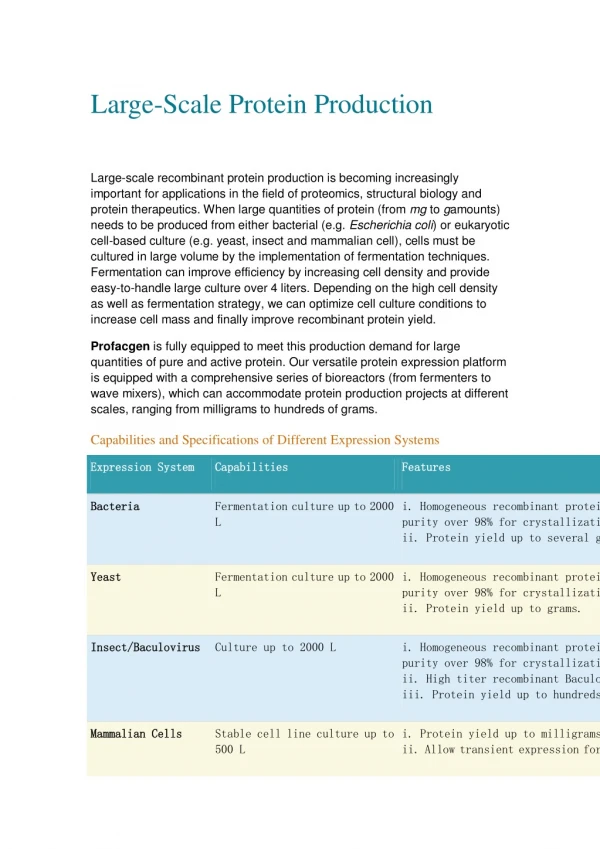
Download

1 / 26
260 likes | 382 Views
Job Failure Analysis and Its Implications in a Large-scale Production Grid. Hui Li Leiden University Dec 5, 2006. Outline. Background The Grid-level Workload Failure Analysis Temporal and Spatial Behavior Cross-correlation Implications Modeling Failure-aware Strategies Summary.

E N D
Job Failure Analysis and Its Implications in a Large-scale Production Grid Hui Li Leiden University Dec 5, 2006
Outline • Background • The Grid-level Workload • Failure Analysis • Temporal and Spatial Behavior • Cross-correlation • Implications • Modeling • Failure-aware Strategies • Summary IEEE eScience2006
Related Work • Failure Analysis, Modeling, and Fault-tolerance • Logs at the node level on Large-scale server clusters [Sahoo ‘04, Zhang ‘04] • Fault-tolerant resource management systems at the cluster and the Grid level [Hwang ‘03, Limaye ‘05] • Fault-tolerant techniques at the application level IEEE eScience2006
Our Approach • Another view of failures through workload data at the Grid level • Difficulty of monitoring and data collection in Grids compared with single systems (nodes, disks, networks, stacks of middleware, libraries, applications, human and policy issues, etc) • Higher level statistical analysis on failed jobs in Grids IEEE eScience2006
Motivation • Insights into … • What? -> types, distributions • Why? -> possible explanations • When? -> temporal behavior • Where? -> spatial behavior • How? -> Modeling and failure-aware strategies IEEE eScience2006
Workload Data • LHC Computing Grid • Data-intensive sciences • ~180 sites, 30k CPUs, 4 petabytes storage • Virtual Organizations • Resource Brokers • LCG Real Time Monitor developed by Imperial College London • Monitors most of the major RBs • Representative at the Grid level IEEE eScience2006
RTM view of LCG IEEE eScience2006
Workload Description • Comprehensive in terms of recorded attributes: timestamps, VO, user, RB, CE, WN, status • VOs: lhcb, atlas, cms, dteam, etc • Exponential decay (80%-20% rule) IEEE eScience2006
Summary statistics of jobs with different status IEEE eScience2006
Job failures by VOs IEEE eScience2006
Temporal Behavior IEEE eScience2006
Failure interarrival time IEEE eScience2006
Failure life span IEEE eScience2006
Spatial Behavior IEEE eScience2006
Short Summary • Temporal and spatial burstiness • Correlations in failure interarrival times and life span • A-L. Barabasi. The origin of bursts and heavy tails in human dynamics. Nature, 435:207-211, 2005. IEEE eScience2006
Cross-correlation IEEE eScience2006
Cross-correlation IEEE eScience2006
Modeling Hui Li and Michael Muskulus. Analysis and Modeling of Job Arrivals in a Production Grid, ACM Sigmetrics Performance Evaluation Review, December issue, 2006, to appear. http://www.liacs.nl/~hli IEEE eScience2006
Failure-aware Strategies • Shortcomings in the current scheduling strategies: • One-attribute resource ranking after matchmaking • Does not take the job arrival patterns into account • “Memoryless” of job failures IEEE eScience2006
Historical Awareness • Inspired by the fairshare scheme in the Maui scheduler • Track historical job failures at the Resource Broker level via “historical failure” (HF) IEEE eScience2006
Historical Failure IEEE eScience2006
Illustration IEEE eScience2006
Proactive Awareness • Bags instead of individual jobs • Dividing the jobs in a burst period into bags according to the CE “effective capacity”. • Hui Li. Machine Learning for Performance Predictions on Space-shared Computing Environments. Intl. Transactions on Systems Science and Applications, ISSN 1751-1461, invited paper, to appear. • Proactive Data replication IEEE eScience2006
Accountability • Efforts are needed both from the system and the client side • Negative effect of “place-holder” jobs • Users are held responsible for their behavior in the Grid, whether in terms of priority policies or money IEEE eScience2006
Summary • A comprehensive statistical analysis of job failures in a large-scale Grid • Summary statistics, temporal and spatial behavior, cross-correlation • Modeling and distribution fitting • Scheduling strategies for failure awareness IEEE eScience2006
Acknowledgements • Gidon Moont and David J. Colling (Imperial College London) • David Groep, Jeff Templon (NIKHEF) • Michael Muskulus (Mathematics, Leiden) IEEE eScience2006