Download

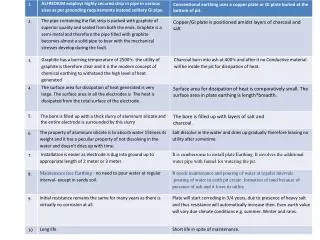
1 / 47
470 likes | 613 Views
A comparison of climate applications on accelerated and conventional architectures. Srinath Vadlamani Youngsung Kim and John Dennis ASAP-TDD-CISL NCAR. Presentation has two parts. The overall picture of acceleration effort and different techniques should be understood. [ Srinath V.]

E N D
A comparison of climate applications on accelerated and conventional architectures. • SrinathVadlamani • YoungsungKim • and John Dennis • ASAP-TDD-CISL NCAR
Presentation has two parts • The overall picture of acceleration effort and different techniques should be understood. [Srinath V.] • We use small investigative kernels to help teach us. • We use instrumentation tools to help us work with the larger code set. • The investigative DG_KERNEL shows what is possible if everything was simple. [Youngsung K.] • DG_KERNEL helped us understand the hardware. • DG_KERNEL helped us understand coding practices and software instructions to achieve superb performance.
Application and Scalability Performance (ASAP) team researching modern micro-architecture for Climate Codes • ASAP Personnel • SrinathVadlamani, John Dennis, Youngsung Kim, Michael Arndt, Ben Jamroz and Rich Loft • Active collaborators • Intel: Michael Greenfield, RuchiraSasanka, Sergey Egorov, Karthik Raman, and Mark Lubin • NREL: Ilene Carpenter
Climate codes ALWAYS NEED A FASTER SYSTEM. • Climate simulations simulate 100s to 1000s of years of activity. • Currently high resolution climate simulations rate is 2 ~ 3 simulated year per day (SYPD) [~40k pes]. • GPUs and Coprocessors can help to increase SYPD. • Many collaborators mandates the use of many architectures. • We must use these architectures efficiently for successful SYPD speed up, which requires knowing the hardware!
We have started the acceleration effort a specific platforms. • Conventional CPU based: • NCAR Yellowstone (Xeon: SNB) - CESM, HOMME • ORNL TITAN (AMD: Interlagos) - benchmark kernel • Xeon Phi based: • TACC Stampede - CESM • NCAR test system (SE10x changing to 7120) - HOMME • GPU based: • NCAR Caldera cluster (M2070Q) -HOMME • ORNL Titan(K20x) -HOMME • TACC Stampede (K20) - benchmark kernels only.
We can learn how to use accelerated hardware for climate codes by creating representative examples. • CESM is a large application so we need to create benchmarks kernels to understand the hardware. • Smaller examples are easier to understand and manipulate. • The first two kernels we have created are • DG_KERNEL from HOMME [detailed by Youngsung] • Standalone driver for WETDEPA_V2.
Knowing what can be accelerated is half the battle. • We created DG_KERNEL knowing it could be a well vectorized code (with help). • What if we want to start cherry picking subroutines and loops to try the learned techniques? • Instrumentation tools are available with teams that are willing to support your efforts. • Trace based tools offer great detail. • Profile tools present summaries upfront. • Previous NCAR-SEA conference highlighted such tools.
Extrae tracing can pick out problematic regions of a large code. • Extrae tracing tool developed at Barcelona Supercomputer Center • H. Servat, H. Labart, J. Gimenez • Automatic performance identification process is a BSC research project. • Produces a time series of communication and hardware counter events. • Paraver is the visualizer that also performs statistical analysis. • There are clustering techniques which uses a folding concept plus the research identification process to create “synthetic” traces with fewer samples.
Clustering groups with similar bad computational characteristics is a good guide. • Result of an Extrae trace of CESM on Yellowstone. • Similar to exclusive execution time.
Extrae tracing exposed possible waste of cycles. • Red: Instructions count. • Blue: d(INS)/dt
Paraveridentified code regions. • Trace identifies what code is active when. • We now examine code regions for characteristics amenable to acceleration.
small number of lines of code • ready to be vectorized Automatic Performance Identification highlighted these group’s subroutines.
wetdepa_v2 can be vectorized with recoding. • The subroutine has sections of double nested loops. • These loops are very long with branches. • Compilers will have trouble vectorizing loops containing branches. • The restructure started with breaking up loops. • We collected scalars into arrays for vector operations. • We broke up very long expressions into smaller pieces.
Vectorizing? • -vec-report=3,6 • Modification was for a small number of lines. • -O3 fast for orig. gave incorrect results • Code optimized Modification of the code does compare well with compiler optimization.
Modified wetdepa_v2 placed back in to CESM on SNB shows better use of resources. • 2.5% --> .7% of overall execution in CESM on Yellowstone.
Profilers are also useful tools for understanding code efficiency in the BIG code. • CAM-SE configuration was profiled on Stampede at TACC using TAU. • It provides different levels of introspection of subroutine and loop efficiency. • This process taught us some more about hardware counter metrics. • Initial investigation fits in the core-count to core-count comparison.
Long exclusive time on both devices is a good place to start looking. • Hot Spots can be associated with largest exclusive execution time. • Long time may be a branchy section of code.
Possible speedup can be achieved with a gain in Vectorization Intensity (VI) • Low VI is a candidate for acceleration techniques • High VI could be misleading. • Note: The VI metric is defined differently on Sandybridge and Xeon Phi. http://icl.cs.utk.edu/projects/papi/wiki/PAPITopics:SandyFlops
CESM on KNC not competitive today. • FC5 ne16g37 • 16 MPI ranks/node • 1 rank/core • 8 nodes • Single thread
Hybrid-parallelism is promising for CESM on KNC • FCIDEAL ne16ne16 • Stampede: 8 nodes • F03 use of allocatable derived type components to overcome threading issue [all –O2] • Intel compiler and IMPI • KNC 4.6x slower • Will get better with Xeon Phi tuning techniques
Part 1. Conclusion: We are hopeful to see speedup on accelerated hardware. • CESM is running on the TACC Stampede KNC cluster. • We are more familiar with possibilities on GPUs and KNCs by using climate code benchmark kernels. • Kernels are useful for discovering acceleration strategies and hardware investigations. Results are promising. • We now have tracing and profiling tool knowledge to help identify acceleration possibilities with in the large code base. • We have strategies for symmetric operation as a very attractive mode of execution. • Though CESM is not competitive on a KNC cluster today, the kernel experience shows what is possible.
Performance Tuning Techniquesfor GPU and MIC ASAP/TDD/CISL/NCAR Youngsung Kim
Contents • Introduction • Kernel-based approach • Micro-architectures • MIC performance evolutions • CUDA-C performance evolutions • CPU performance evolutions along with MIC evolutions • GPU programming : Open ACC, CUDA Fortran, and F2C-ACC • One source consideration • Summary
Motivation of kernel-based approach • What is a kernel? • A small computation-intensive part of existing large code • Represent characteristics of computations • Benefit of kernel-based approach • Easy to manipulate and understand • CESM: >1.5M LOC • Easy to convert to various programming technologies • CUDA-C, CUDA-Fortran, OpenACC, and F2C-ACC • Easy to isolate issues for analysis • Simplify hardware counter analysis
DG kernel • Origin* • a kernel derived from the computational part of the gradient calculation in the Discontinuous Galerkin formulation of the shallow water equations from HOMME. • Implementation from HOMME • Similar to “dg3d_gradient_mass” function in “dg3d_core_mod.F90” • Calculate gradient of flux vectors and update the flux vectors using the calculated gradient *: D. Nair, Stephen J. Thomas, and Richard D. Loft: A discontinuous Galerkin global shallow water model, Monthly Weather Review, Vol. 133, pp 876-888
DG KERNEL – source code • Source code !$OMP PARALLEL ... DOie=1,nelem DOii=1,npts k=MODULO(ii-1,nx)+1 l=(ii-1)/nx+1 s2 = 0.0_8 DOj = 1, nx s1 = 0.0_8 DOi = 1, nx s1 = s1 + (delta(l,j)*flx(i+(j-1)*nx,ie) * & der(i,k) + delta(i,k) * & fly(i+(j-1)*nx,ie) * der(j,l))*gw(i) END DO ! i loop s2 = s2 + s1*gw(j) END DO ! j loop grad(ii,ie) = s2 END DO ! iiloop END DO ! ieloop !$OMP PARALLEL DOie=1,nelem DOii=1,npts flx(ii,ie) = flx(ii,ie)+ dt*grad(ii,ie) fly(ii,ie) = fly(ii,ie)+ dt*grad(ii,ie) END DO ! Iiloop END DO ! ieloop • Floating point operations • No dependancy between elements • # of elements • Can be calculated from source code analytically • Ex.) When nit=1000, nelem=1024, nx=4(npts=nx*nx) ≈ 2 GFLOP • OpenMP • Two OpenMP Parallel regions for Do loops on element index(ie)
Micro-architectures • CPU • Conventional multi-core: 1 ~ 16+ cores/~256-bit vector registers • Many programming language: Fortran, C/C++, etc. • Intel SandyBridge E5-2670 • Peak performance(2 Sockets): 332.8 DP GFLOPS(Estimated by presenter) • MIC • Based on Intel Pentium cores with extensions including wider vector registers. • Many core and wider vector: 60+ cores/512-bit vector registers • Limited programming language(extensions only from Intel): C/C++, Fortran • Intel KNC( a.k.a. MIC) • Peak Performance(7120): 1.208 DP TFLOPS • GPU • Many light-weight threads: ~2680+ threads(threading & vectorization) • Limited programming language(extensions): CUDA-C, CUDA-Fortran, OpenCL, OpenACC, F2C-ACC, etc. • Peak performances • Nvidia K20x: 1.308 DP TFLOPS • Nvidia K20: 1.173 DP TFLOPS • Nvidia M2070Q: 515.2 GFLOPS
The best performance results from CPU, GPU, and MIC 6.6x 5.4x MIC
MIC evolution • Compiler options • -mmic • Environmental variables • OMP_NUM_THREADS=240 • KMP_AFFINITY = 'granularity=fine,compact' • Native mode only • No cost of memory copy between CPU and MIC • Supports from Intel • R. Sasanka 15.6x
MIC ver. 1 • Source modification • NONE • Compiler options • -mmic –openmp –O3
MIC ver. 2 • Source code i = 1 s1 = (delta(l,j)*flx(i+(j-1)*nx,ie)*der(i,k) + delta(i,k)*fly(i+(j-1)*nx,ie)*der(j,l))*gw(i) i = i + 1 s1 = s1 + (delta(l,j)*flx(i+(j-1)*nx,ie)*der(i,k) + delta(i,k)*fly(i+(j-1)*nx,ie)*der(j,l))*gw(i) i = i + 1 s1 = s1 + (delta(l,j)*flx(i+(j-1)*nx,ie)*der(i,k) + delta(i,k)*fly(i+(j-1)*nx,ie)*der(j,l))*gw(i) i = i + 1 s1 = s1 + (delta(l,j)*flx(i+(j-1)*nx,ie)*der(i,k) + delta(i,k)*fly(i+(j-1)*nx,ie)*der(j,l))*gw(i) • Compiler options • -mmic -openmp –O3 • Performance Considerations • Complete unroll of three nested loops • Vectorized, but not efficiently enough
MIC ver. 3 • Source code !$OMP PARALLEL DO ... DO ie=1,nelem DO ii=1,npts ... END DO !ii DO ii=1,npts ... END DO END DO !$OMP END PARALLEL DO nowait • Compiler options • -mmic -openmp -O3 -align array64byte -opt-prefetch=0 • Performance Considerations • Merged two openMP regions into one with “no wait” • Helps to remove openMP sync. overheads
MIC ver. 4 • Source code DO j=1,NX DO i=1, NX ji = (j-1)*NX !DEC$ vector always aligned DO ii=1, NX*NX grad2(ii,j) = grad2(ii,j) + ( delta2(ii,j)* & flx(ji+i,ie)*der2(ii,i) + delta3(ii,i) * & fly(ji+i,ie)*der3(ii,j) ) * gw2(i) END DO ! ii-loop END DO ! i-loop !DEC$ vector always aligned DO ii=1, NX*NX grad(ii) = grad(ii) + grad2(ii,j) * gw2(j) ENDDO END DO ! J • Compiler options • -mmic -openmp -O2 -align array64byte -opt-prefetch=0 -opt-assume-safe-padding • Performance Considerations • Reduced gather/scatter and increased aligned vector move • All arrays are referenced unit-stride way, or fixed.
MIC ver. 5 • Source code modification DO j=1,SET_NX DO i=1, SET_NX ji = (j-1)*SET_NX + i !DEC$ vector always aligned DO ii=1, SET_NX*SET_NX grad2(ii,j) = grad2(ii,j) + & ( delta_der2(ii,ji)*flx(ji,ie) + & delta_der3(ii,ji)*fly(ji,ie) ) * gw(i) END DO END DO … END DO • Compiler options • mmic -openmp -O3 -align array64byte -opt-prefetch=0 -opt-assume-safe-padding -mP2OPT_hlo_fusion=F • Performance Considerations • Effectively reduce two FLOPs to one FLOP by merging two arrays into one and pre-calculates it
CPU Evolutions with MIC evolutions • Generally, performance tuning on a micro-architecture also helps to improve performance on another micro-architecture. However, it is not always true. GPU
CUDA-C Evolutions • Compiler options • -O3 -arch=sm_35 • same to all versions • “Offload mode” only • However, the time cost for data copy between CPU and GPU is not included for comparison to MIC native mode 14.2x
CUDA-C ver. 1 • Source code <Host> … dim3 gridSize(nelem), blockSize(nX*nX); kernel<<<gridSize, blockSize>>>(D_flx, D_fly, D_der, …); … <Kernel> … ie = blockIdx.x*ColsPerBlock + threadIdx.x/(nX*nX); ii = threadIdx.x%(nX*nX); k = ii%nX; l = ii/nX; … for (j=0;j<nX;j++) { s1 = 0.0; for (i=0;i<nX;i++) { s1 = s1 + (D_delta[j*nX+l] * D_flx[ie*nX*nX+i+j*nX] * \ D_der[k*nX+i] + D_delta[k*nX+i]* \ D_fly[ie*nX*nX+i+j*nX] * D_der[l*nX+j]) * D_gw[i]; } s2 = s2 + s1 * D_gw[j]; } D_flx[ie*nX*nX+ii] = D_flx[ie*nX*nX+ii] + dt * s2; D_fly[ie*nX*nX+ii] = D_fly[ie*nX*nX+ii] + dt * s2; … • Performance considerations • Converting from Fortran to CUDA-C requires considerable amount of effort to make it work correctly • Conversion to CUDA-C force programmer to think about thread parallelization and vectorization from the beginning
CUDA-C ver. 2 • Source code <Host> dim3 gridSize(nelem/8)); dim3 blockSize(nX*nX*8) <Kernel> No change • Performance considerations • Enhance theoretic occupancy by using CUDA GPU Occupancy Calculator • 25% when blockSize=NX*NX • 100% when blockSize=NX*NX*8
CUDA-C ver. 3 • Source code <Host> No change <Kernel> __shared__double D_flx_s[nX*nX*nSizeSubBlock] __shared__double D_fly_s[nX*nX*nSizeSubBlock]; … D_flx_s[ik*nX*nX+ii] = D_flx[ie*nX*nX+ii]; D_fly_s[ik*nX*nX+ii] = D_fly[ie*nX*nX+ii]; … // calculations using data pre-fetched to shared mem. … D_flx[ie*nX*nX+ii] = D_flx_s[ik*nX*nX+ii] + dt * s2; D_fly[ie*nX*nX+ii] = D_fly_s[ik*nX*nX+ii] + dt * s2; • Performance considerations • Pre-fetch data from DRAM to Shared Memory • Re-use the pre-fetched data nX*nX times
CUDA-C ver. 4 • Source code <Host> No change <Kernel> __shared__double D_der_s[nX*nX], D_delta_s[nX*nX]; __shared__double D_gw_s[nX]; … for (i=0;i<nX;i++) { s1 = s1 + (D_delta_s[j*nX+l] * D_flx_s[ik*nX*nX+i+j*nX]* \ D_der_s[k*nX+i] + D_delta_s[k*nX+i] * \ D_fly_s[ik*nX*nX+i+j*nX] * D_der_s[l*nX+j]) * D_gw_s[i]; } • Performance considerations • Re-use data of static arrays that are loaded to Shared memory
CUDA-Fortran • Source Code ie = (blockidx%x - 1)*NDIV + (threadidx%x - 1)/(NX*NX) + 1 ii = MODULO(threadIdx%x - 1, NX*NX) + 1 IF (ie > SET_NELEM) RETURN k = MODULO(ii-1,NX) + 1 l = (ii - 1)/NX + 1 s2 = 0.0_8 DO j=1, NX s1 = 0.0_8 DO i = 1, NX s1 = s1 + (delta(l,j)*flx(i+(j-1)*nx,ie)*der(i,k) + & delta(i,k)*fly(i+(j-1)*nx,ie)*der(j,l))*gw(i) END DO ! i loop s2 = s2 + s1*gw(j) END DO ! j grad(ii,ie) = s2 flx(ii,ie) = flx(ii,ie)+ dt*grad(ii,ie) fly(ii,ie) = fly(ii,ie)+ dt*grad(ii,ie) • Performance considerations • Maintains source structure of original Fortran • Needs understanding on CUDA threading model, especially for debugging and performance tuning • Supports implicit memory copy, which is convenient but could negatively impact to performance if over-used.
OpenACC • Source Code !$ACC DATA PRESENT_OR_COPY(flx,fly) PRESENT_OR_CREATE(grad) PRESENT_OR_COPYIN(gw,der,delta) !$ACC KERNELS !$ACC LOOP GANG(ngangs) VECTOR(neblk) DO ie=1, SET_NELEM ... END DO ! Ie !$ACC END KERNELS !$ACC END DATA • Performance considerations • Trial and error with ngangs and neblk • Compiler report feature helps to understand how it affects to GPU resource allocations • Was not successful to use cache directive on PGI compiler
F2C-ACC • Source Code !ACC$REGION (<npts:block=16>,<nelem>,<der,delta,gw:in>,<flx,fly:inout>,<grad:none>) BEGIN !ACC$DO PARALLEL(1) DO ie=1, nelem !ACC$DOVECTOR(1) DO ii=1, nx*nx … END DO !ii END DO ! Ie !ACC$REGIONEND • Performance considerations • Similar to Open ACC in terms of programming • Generates CUDA C source file that is readable • Performance is between OpenACC and CUDA Fortran • Lack of support for some language features including derived types
One source • One source is highly desirable • Hard to manage versions from multiple micro-architectures and multiple programming technologies • Performance enhancement can be applied to multiple versions simultaneously • Conditional Compilation • Macro to insert & delete code for a particular technology • User control compilation by using compiler macro • Hard to get one source for CUDA-C • Many scientific codes are written in Fortran • CUDA-C has quite different code structure and should be written in C • Performance impact • Highest performance tuning techniques hardly allow one source
Conclusions • Faster hardware provides us with potential to the performance. However, we can exploit the potential only through better software. • Better software on accelerators generally means that it utilizes many cores and wide vectors simultaneously and efficiently. • In practice, those massive parallelisms can be achieved effectively by, among others, 1) re-using data that are loaded onto faster memory and 2) accessing successive array elements with aligned unit-stride manner.
Conclusions - continued • Using those techniques, we have achieved considerable amount of speed-ups for DG KERNEL • Speed-ups compared the best one socket SandyBridge performance • MIC: 6.6x • GPU: 5.4x • Speed-ups from initial version to the best performed version • MIC: 15.6x • GPU: 14.2x • Our next challenge is to applying the techniques that we have learned from kernel experiments to real software package.
Thank you for your attention. • Contacts: srinathv@ucar.edu, youngsung@ucar.edu • ASAP: http://www2.cisl.ucar.edu/org/cisl/tdd/asap • CESM: http://www2.cesm.ucar.edu • HOMME: http://www.homme.ucar.edu • Extrae: http://www.bsc.es/es/computer-sciences/performance-tools/trace-generation • TAU: http://www.cs.uoregon.edu/research/tau/home.php