Download

1 / 44
440 likes | 565 Views
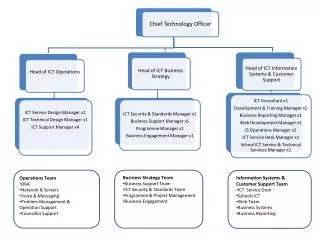
Representing Video for Retrieval and Repurposing SIMS 202 Information Organization and Retrieval. Marc Davis Chairman and Chief Technology Officer. Presentation Outline. Introductions Problem space and motivation Current approaches Issues in video representation and retrieval

E N D
Representing Video for Retrieval and Repurposing SIMS 202 Information Organization and Retrieval Marc Davis Chairman and Chief Technology Officer
Presentation Outline • Introductions • Problem space and motivation • Current approaches • Issues in video representation and retrieval • Media streams demonstration
Global Media Network • Digital video produced anywhere by anyone accessible to anyone anywhere • Today’s video users become tomorrow’s video producers • Not 500 Channels — 500,000,000 Video Web Sites
What is the Problem? • Today people cannot easily create, find, edit, share, and reuse media • Computers don’t understand video content • Video is opaque and data rich • We lack structured representations • Without content representation (metadata), manipulating digital video will remain like word-processing with bitmaps
The Search for Solutions • Current approaches don’t work • Signal-based analysis • Keywords • Natural language • Need standardized metadata framework • Designed for video and rich media data • Human and machine readable and writable • Standardized and scaleable • Integrated into media capture, production, editing, distribution, and reuse • Enables widespread use and reuse of video in daily life
Signal-Based Parsing • Theoretical problem • Mismatch between percepts and concepts (e.g., dogs, friends, cars) • Practical problem • Parsing unstructured, unknown video is very, very hard
Signal-Based Parsing • Some things are doable and usable • Video • Scene break detection • Camera motion • Low level visual similarity • Audio • Pause detection • Audio pattern matching • Simple speech recognition • Some things can be made easier • At the point of capture, simplify and/or interact with the recording device, the environment, and agents in the environment • If not, after capture use “human-in-the-loop” algorithms
Keywords vs. Semantic Descriptors dog, biting, Steve
Keywords vs. Semantic Descriptors dog, biting, Steve
Why Keywords Don’t Work • Are not a semantic representation • Do not describe relations between descriptors • Do not describe temporal structure • Do not converge • Do not scale
Natural Language vs. Visual Language Jack, an adult male police officer, while walking to the left, starts waving with his left arm, and then has a puzzled look on his face as he turns his head to the right; he then drops his facial expression and stops turning his head, immediately looks up, and then stops looking up after he stops waving but before he stops walking.
Natural Language vs. Visual Language Jack, an adult male police officer, while walking to the left, starts waving with his left arm, and then has a puzzled look on his face as he turns his head to the right; he then drops his facial expression and stops turning his head, immediately looks up, and then stops looking up after he stops waving but before he stops walking.
Visual Language Advantages • A language designed as an accurate and readable representation of video (especially for actions, expressions, and spatial relations) • Enables Gestalt view and quick recognition of descriptors due to designed visual similarities • Supports global use of annotations
Representing Video • Streams vs. Clips • Video syntax and semantics • Ontological issues in video representation • Retrieving video
Streams vs. Clips • Clip-based representation • Fixes a segmentation of the video stream • Separates the clip from its context of origin • Encodes only one particular segmentation of the original data
Streams vs. Clips Stream of 100 Frames of Video
Streams vs. Clips • Stream-based representation • The stream of frames is left intact • The stream has many possible segmentations by multi-layered annotations with precise time indexes (and the intersections, unions, etc. of these annotations)
Stream-Based Representation • Makes annotation pay off • The richer the annotation, the more numerous the possible segmentations of the video stream • Clips • Change from being fixed segmentations of the video stream, to being the results of retrieval queries based on annotations of the video stream • Annotations • Create representations which make clips, not representations of clips
Video Syntax and Semantics • The Kuleshov Effect • Video has a dual semantics • Sequence-independent invariant semantics of shots • Sequence-dependent variable semantics of shots
Ontological Issues for Video • Video plays with rules for identity and continuity • Space • Time • Character • Action
Space and Time • Actual Recorded Space and Time • GPS • Studio space and time • Inferable Space and Time • Establishing shots • Cues and clues
Time: Temporal Durations • Story (Fabula) Duration • Example: Brushing teeth in story world (5 minutes) • Plot (Syuzhet) Duration • Example: Brushing teeth in plot world (1 minute: 6 steps of 10 seconds each) • Screen Duration • Example: Brushing teeth (10 seconds: 2 shots of 5 seconds each)
Character and Continuity • Identity of character is constructed through • Continuity of actor • Continuity of role • Alternative continuities • Continuity of actor only • Continuity of role only
Representing Action • Describe the intersubjective, physically visible aspects of what you see and hear • Emotions vs. expressions • Abstract actions vs. conventionalized actions • Consider how actions can be decomposed and combined (temporally and spatially) • Actions and subactions • Consider how actions can be recontextualized • By montage and reuse • By cultural differences
Retrieving Video • Query: • Retrieve a video segment of “a hammer hitting a nail into a piece of wood” • Sample results: • Video of a hammer hitting a nail into a piece of wood • Video of a hammer, a nail, and a piece of wood • Video of a nail hitting a hammer, and a piece of wood • Video of a sledgehammer hitting a spike into a railroad tie • Video of a rock hitting a nail into a piece of wood • Video of a hammer swinging • Video of a nail in a piece of wood
Types of Video Similarity • Semantic • Similarity of descriptors • Relational • Similarity of relations among descriptors in compound descriptors • Temporal • Similarity of temporal relations among descriptors and compound descriptors
Retrieval Examples to Think With • “Video of a hammer, a nail, and a piece of wood” • Exact semantic and temporal similarity, but no relational similarity • “Video of a nail hitting a hammer, and a piece of wood” • Exact semantic and temporal similarity, but incorrect relational similarity • “Video of a sledgehammer hitting a spike into a railroad tie” • Approximate semantic similarity of the subject and objects of the action and exact semantic similarity of the action; and exact temporal and relational similarity • “Video of a hammer swinging” cut to “Video of a nail in a piece of wood” • Combines two disparate elements in the database (partial results) to create an effective query response
MediaAnnotation and Retrieval Engine • Key benefits • More accurate annotation and retrieval • Global usability and standardization • Reuse of rich media according to content and structure • Key features • Stream-based representation (better segmentation) • Semantic indexing (what things are similar to) • Relational indexing (who is doing what to whom) • Temporal indexing (when things happen) • Iconic interface (designed visual language) • Universal annotation (standardized markup schema)
Media Streams GUI Components • Media Time Line • Icon Space • Icon Workshop • Icon Palette
Media Time Line • Visualize video at multiple time scales • Write and read multi-layered iconic annotations • One interface for annotation, query, and composition
Icon Space • Icon Workshop • Utilize categories of video representation • Create iconic descriptors by compounding iconic primitives • Extend set of iconic descriptors • Icon Palette • Dynamically group related sets of iconic descriptors • Reuse descriptive effort of others • View and use query results
Icon Space: Icon Workshop • General to specific (horizontal) • Cascading hierarchy of icons with increasing specificity on subordinate levels • Combinatorial (vertical) • Compounding of hierarchically organized icons across multiple axes of description
Icon Space: Icon Palette • Dynamically group related sets of iconic descriptors • Collect icon sentences • Reuse descriptive effort of others
Video Retrieval In Media Streams • Same interface for annotation and retrieval • Assembles responses to queries as well as finds them • Query responses use semantics to degrade gracefully
Media Streams Technologies • Minimal consensual representation distinguishing video syntax and semantics • Iconic visual language for annotating and retrieving video content • Retrieval-by-composition methods for repurposing video
Methodological Considerations • Techne-centered methodology combines • Constructing theories by constructing artifacts • Constructing artifacts informed by (de)constructing theories • Practitioners • Lev Kuleshov, Sergei Eisenstein, Seymour Papert, Narrative Intelligence Reading Group, Marc Davis • Designing video representation and retrieval systems requires a techne-centered methodology
Future Work • MPEG-7 standardization efforts • Gathering more and better metadata at the point of capture • Integrating metadata into conventional media editing and sharing • Developing “human-in-the-loop” indexing algorithms and systems • Representing action sequences and even higher level narrative structures • Fair use advocacy