Download

1 / 21
210 likes | 317 Views
Quete: Ontology-Based Query System for Distributed Sources. Haridimos Kondylakis , Anastasia Analyti, Dimitris Plexousakis Kondylak, analyti, dp @ics.forth.gr. Presentation Outline. Motivation Current Integration Approaches Quete Overview Querying in Quete Evaluation Conclusions

E N D
Quete: Ontology-Based Query System for Distributed Sources Haridimos Kondylakis, Anastasia Analyti, Dimitris Plexousakis Kondylak, analyti, dp @ics.forth.gr
Presentation Outline • Motivation • Current Integration Approaches • Quete Overview • Querying in Quete • Evaluation • Conclusions • Future Work
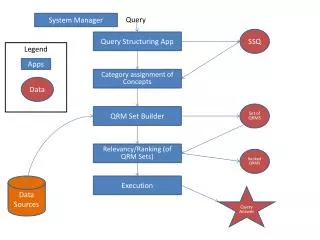
1. Motivation Visualization Tools Regulatory Element Tools findings metadata Statistical, Clustering, Classification Tools D.B. Query Engine mediator Sample name Normalized data Clinical IS Genomic IS Normalization Tools
2. Current Approaches (1/2) • Warehouse Integration • Data is downloaded, filtered, integrated and stored in a warehouse. Answers are taken from the warehouse • GUS • Navigational Integration • Explicit Links Between data • SRS, Entrez • Mediator - Wrapper Approaches • A global schema is defined over all data sources • K2/BioKleisli, TAMBIS, BACIIS, DiscoveryLink
2. Current Approaches (2/2) • Mediator-Wrapper approach • GAV approach • The global schema is defined in terms of the source terminologies • LAV approach • The sources are defined in terms of the global schema Query Results Mediator Wrapper Wrapper Source 1 Source 2
3. Integration Architecture Java Application Ontology Query Result Q U E T E Java DB Engine Jdbc-Odbc Jdbc-Odbc Jdbc-Odbc Source 1 Source 2 Source 3
GOAnnotation GOId : StringGOName : String GeneExpression BreastCancerPatient RatioValue : Decimal Name : StringCity : StringSSN : String GOBiologicalProcess Hybridization GOCellularComponent HybridizationDate : Date TumorSample TumorIdentifier : StringSurgeryDate : Date 3.1 The Reference Ontology • Ontology is organized as a graph (+relationship concepts) related through • IS-A • HAS-A RiskFactors Reporter YearsOfSmoking : IntAge : Int ReporterName :StringHGNCGeneSymbol :String GOMolecularFunction IS-A HAS-A
3.2 Semantic Names • A semantic name (SN) captures the system independent semantics of a schema element combining one or more ontology terms • Semantic_name= [CN1; …; CNm] AN The semicolon between CNi and CNi+1 means that concept CNi is generalization of concept CNi+1 .
3.3 Definitions • A semantic name [CN1; …; CNm] AN is subsumed by a semantic name [CN1 ’; …; CNm ’] AN ’ , if • m ’ <= m • CNm-m’+I coincides with or is a specialization of CNi ’ , i=1, …, m’ • AN=AN’ • Two semantic names are semantically overlapping if • Their last i concept names are the same or related through the ISA relationship • They have the same attribute name AN
3.4 Integration Steps • Capture Process • Captures the data to be integrated • Performed independently in each source • Use Extractor tool to export database schemata • Choose fields/tables of interest • Use the Ontology to Annotate Schemata Use the Ontology to Annotate Schemata • Database schemata extracted and stored in X-Spec files that are sent to the central site. • Integration Process • Central Integration of the various data sources • A global view is produced in memory called Context View
4.1 Query Formulation • Attribute-only version of SQL SELECT [BreastCancerPatient]Name, [Reporter]HGNCGeneSymbol, [GeneExpression]RatioValue WHERE [RiskFactors]YearsOfSmoking>30 AND [Hybridization]HybridizationDate=[TumorSample]SurgeryDate AND [Reporter;GOMolecularFunction]GOName=“celladhesion” ORDERBY [BreastCancerPatient]Name • SELECT clause contains concepts to be projected • WHERE clause specifies selection criteria • FROM clause is absent since the integration system will automatically identify tables to be used. • No need for explicit join declarations
4.2 Query Answering • Semantic Query is decomposed in SQL subqueries • When possible all operations are pushed into subqueries • They are issued in parallel in distinct data sources • When all results are returned in central site, all remaining operations are performed ( joins, ordering etc)
4.3 Requirements in forming local subqueries • Identify the interesting to the user table attributes with semantic name [CNpath]AN • i.e (attributes with the same or more specific information+ local join keys) • Since the from clause is missing, the linking tables with interesting to the user attributes must be determined and their join conditions • The join attributes called DB link attributes are needed to link the interesting to the user attributes among sources
4.4 Forming the local sub-queries • Extension of Unity’s algorithm that increase’s system recall with no sacrifice in precision • Our algorithm takes into account • The user query • The ontology • The data source-to-ontology mappings • …and formulates a single sub query (SQ) for each data source
4.5 Algorithm: Result Composition Input: (i)The user semantic query (ii) local SQs Output: Composition plan • Find all minimal subsets of SQs such that • There is a join tree connecting all subqueries • All the semantic query’s fields exist • In each SQ there is a projection attribute which does not overlap with the projection attribute of another SQ • Join the queries in each minimal subset • Project the common requested attributes • Union Results • Apply Group and Order operations
4.6 Results composition • Is done with the help of a central DBMS • For every sub query design the temporary table in central db and store the returned results • Build the global SQL query to be issued to the central DB according to the result composition plan • Execute the global SQL query • Pros • First step executed in parallel • Uses DBMS technology to handle efficient join, union, order and group operators
4.6 Novel features • Horizontal, vertical and hybrid fragmentation can be declared and used • During the formation of local sub queries • During the formation of the result composition plan • It rebuilds the fragmented tables before going further down to composition plan • Advantages • Eliminate unnecessary local sub queries • Avoids joins that are certain to return empty results • Increasing system’s recall • Improving performance.
Conclusions • Information Integration is a difficult task • Heterogeneity of Sources • Independent Evolution • Communication costs • Complicated Structures • Our system has good performance. • A LAV system • Global Schema do not change as sources evolve new sources are added • But without LAV’s complexity in processing • Trade off between complexity and efficiency
Future Work • More Query Algorithms in memory • Database Cycles • Non – Relational Data Sources • Exploit Systems for Automatic Schema matching • Web Service – Grid approach • Caching • Updates in sources