Download

1 / 30
300 likes | 439 Views
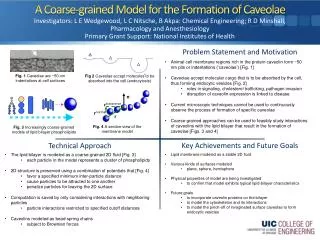
Filter Decomposition for Supporting Coarse-grained Pipelined Parallelism. Wei Du , Gagan Agrawal Ohio State University. data. data. data. data. Internet. data. data. data. Distributed Data-Intensive Applications. Fast growing datasets Remote data access Distributed data storage

E N D
Filter Decomposition for Supporting Coarse-grained Pipelined Parallelism Wei Du, Gagan Agrawal Ohio State University
data data data data Internet data data data Distributed Data-Intensive Applications • Fast growing datasets • Remote data access • Distributed data storage • More connected world
data data data data Internet data data data Implementation: Local processing Requirements: Huge Storage/Powerful Computer/Fast Connection data data data data Internet data data data
Implementation: Remote processing data data data data Internet data data data Requirements: Complex Analysis at Data Centers
A Practical Solution • Our hypothesis • Coarse-grained pipelined execution model is a good match data Internet data
Range_query Find the K-nearest neighbors Coarse-Grained Pipelined Execution • Definition • Computations associated with an application are carried out in several stages, which are executed on a pipeline of computing units • Example — K-nearest Neighbor (KNN) Given a 3-D range R= <(x1, y1, z1), (x2, y2, z2)>, and a point p = (a, b, c). We want to find the nearest K neighbors of pwithin R.
Challenges • Computation associated with an application needs to be decomposed into stages • Decomposition decisions are dependent on the execution environment • Generating code for each stage (SC03) • Other performance issues for the pipelined execution (ICPP04) • Adapting to the dynamic execution environment (SC04)
RoadMap • Filter Decomposition Problem • MIN_ONETRIP Algorithm • MIN_BOTTLENECK Algorithm • MIN_TOTAL Algorithm • Experimental Results • Related Work • Conclusion
C1 f1 , f2 f1 C1 f1 f1 L1 L1 C2 f3 - f6 C2 f2 , f3 fn-1 fn-2,fn-1 Cm-1 Cm-1 Lm-1 Lm-1 fn fn Cm Cm Filter Decomposition f1 C1 L1 f2 C2 Cm-1 fn-1 Lm-1 Cm fn computation pipeline atomic filters
Filter Decomposition f1 C1 Goal: Find a placement p (f1,f2, …, fn) = (F1, F2, …, Fm) where Fi = fi1, fi1+1, …, fik , (1 ≤ i1,ik ≤ n) such that the predicted execution time is minimal (1≤ i ≤ m). L1 f2 C2 Cm-1 fn-1 Lm-1 Cm fn computation pipeline atomic filters
Bottleneck stage: bth stage the slowest stage in the pipeline Execution time T = T(C1)+T(L1)+N*T(C2)+T(L2)+T(C3) = ∑i≠bTi + (N-1)*Tb Cost Model C1 f1 , f2 f1 L1 C2 f3 L2 f4 C3
Three Algorithms T = ∑i≠bTi + (N-1)*Tb • MIN_ONETRIP Algorithm • dynamic programming algorithm • to minimize ∑Ti • MIN_BOTTLENECK Algorithm • dynamic programming algorithm • to minimize Tb • MIN_TOTAL Algorithm • greedy algorithm • try to minimize T
fn fn-1 Filter Decomposition: MIN_ONETRIP Goal: minimize time spent by one packet on the pipeline Cm-2 Lm-2 Cm-1 Lm-1 Cm fn fn-1
T[i-1,j] + Cost_comp(P(Cj),Task(fi)) T[i,j] = min T[i,j-1] + Cost_comm(B(Lj-1),Vol(fi)) Filter Decomposition: MIN_ONETRIP T[i,j]: min cost of doing computations f1 ,…, fi on computing units C1,…, Cj, where the results of fi are on Cj. • Goal: T[n,m] • Cost: O(mn) Cm-2 Lm-2 Cm-1 Lm-1 Cm
f1 f1 f1 … … … fn fn-1 fn-2 f1 fn fn-1fn f2…fn Filter Decomposition: MIN_BOTTLENECK Goal: minimize time spent at the bottleneck stage Cm-2 Lm-2 Cm-1 …… Lm-1 Cm
max{ N[i,j-1], Cost_comm(B(Lj-1),Vol(fi)) } max{ N[i-1,j-1], Cost_comm(B(Lj-1),Vol(fi-1)), Cost_Comp(P(Cj),Task(fi)) } N[i,j] = min … … max{ N[1,j-1], Cost_comm(B(Lj-1),Vol(f1)), Cost_Comp(P(Cj), Task(f2) + … + Task(fi)) } Filter Decomposition: MIN_BOTTLENECK N[i,j]: min cost of bottleneck stage for computing f1 ,…, fi on computing units C1,…, Cj,where the results of fi are on Cj. • Cost: O(mn2)
C1 L1 C2 C3 C4 Filter Decomposition: MIN_BOTTLENECK f1 C1 • To minimize the predicted execution time T L1 f2 C2 Estimated Cost f1 , f2 f1 f3 L2 f1 : T1 C3 f1, f2 : T2 f4 f1 - f3 : T3 L3 f1 - f4 : T4 C4 f5 Min{T1 … T4 } = T2
RoadMap • Filter Decomposition Problem • MIN_ONETRIP Algorithm • MIN_BOTTLENECK Algorithm • MIN_TOTAL Algorithm • Experimental Results • Related Work • Conclusion
Experimental Results • 4 Configurations • 3 Applications • Virtual Microscope • Iso-Surface Rendering 1 1 1 1 1 0.1 0.5 1 1 1 1 0.001 1 1 0.01 1 0.001 0.1 1 0.01
Used Applications • Virtual Microscope (Vmscope) • an emulation of a microscope • input: a rectangular region, a resolution value • output: portion of the original image with certain resolution
Experimental Results: Virtual Microscope • 3 queries • Q1 : 1 packet • Q2 : 4 packets • Q3 : 4500 packets • 4 Algorithms • MIN_ONETRIP • MIN_BOTTLENECK • MIN_TOTAL • Exhaustive_Search
Execution Time (in ms) Execution Time (in ms) Execution Time (in ms) Execution Time (in ms) Application Application Experimental Results: Virtual Microscope
Experimental Results: Virtual Microscope • Two observations • The performance variance between different algorithms is small • The Exha_Search does not always give the best placement • characteristics based on one packet information • combining two filters as one, saving copying cost
Used Applications • Iso-surface rendering (Iso) • input: a 3-D grid, a scalar value, a view screen with angle specified • output: a surface seen from certain angle, which captures points in the grid whose scalar value matches the given iso-surface value
Experimental Results: Iso • 2 Implementations • ZBUF • ACTP • 2 Datasets • small : 3 packets • large : 47 packets • 4 Algorithms • MIN_ONETRIP • MIN_BOTTLENECK • MIN_TOTAL • Exhaustive_Search
Execution Time (in ms) Execution Time (in ms) Application Application Experimental Results: Iso Small dataset Large dataset
Experimental Results: Iso • The MIN_TOTAL algorithm gives the best placement for small dataset • The MIN_ONETRIP algorithm finds the best placement for large dataset • This application is very data-dependent !
Execution Time (in ms) Execution Time (in ms) Number of Runs Number of Runs Experimental Results: Iso ZBUF ACTP
Conclusion & Future Work • Our algorithms perform quite well • Future Work • To find more accurate characteristics of applications • estimate of the performance change resulting from combining multiple atomic filters • estimate of the impact of data dependence