Download

1 / 49
500 likes | 671 Views
Structure-based Analysis of Protein Function. Jacquelyn S. Fetrow Reynolds Professor of Computational Biophysics Departments of Physics and Computer Science Wake Forest University. PTPs and Serine Hydrolases. Jacquelyn S. Fetrow Wake Forest University. Need for Improved Proteome Analyses.

E N D
Structure-based Analysis of Protein Function Jacquelyn S. Fetrow Reynolds Professor of Computational BiophysicsDepartments of Physics and Computer ScienceWake Forest University PTPs and Serine Hydrolases Jacquelyn S. Fetrow Wake Forest University
Need for Improved Proteome Analyses • Powerful genomics and proteomics methods identify large numbers of protein sequences • Need to identify biochemical function and functional state accurately • Need to increase quality of annotations: decrease false positive and false negative identifications
Knowing the Sequence is Not Enough to Determine the Function • Except in model organisms, over 50% of all proteins identified by large-scale sequencing projects are annotated as “function unknown” • Annotations are inadequate and do not adequately describe functional complexity of proteins • Annotation transfer methods can assign incorrect function in a significant number of cases S. cerevisiae Fsh3p S.pombe DYR_SCHPO S. cerevisiae DHFR
COX-1 (1cqe) COX-2 (1cx2) Structural proteomics approach to function annotation • Most common method: • structural superposition • function annotation transfer based on structural similarity
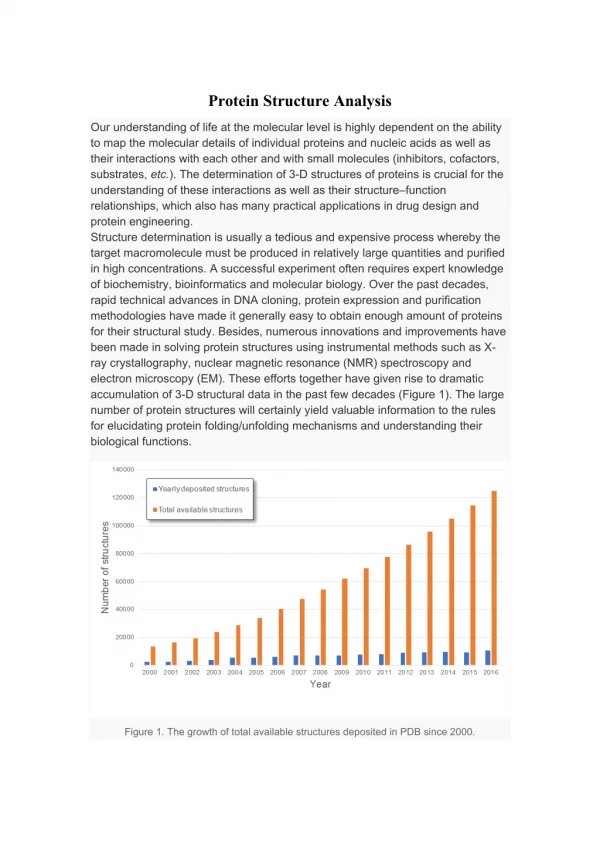
Similar Structure, Different Function Similar Structure, Similar Function 48% 27% 23% Different Structure, Different Function 1.5% Different Structure, Similar Function But, Knowing the Structure is Not Enough to Predict the Function Analysis of high resolution structures released in 1998 compared to pre-1998 PDB structures Koppensteiner, W., Lackner, P. Wiederstein, M., & Sippl, M. J. Mol. Biol 2000 296:1139. See also:Martin, et al. 1998, Structure 6:875-884Hegyi and Gerstein, 1999, J. Mol. Biol. 288:147-164.
COX-1 (1cqe) COX-2 (1cx2) But, then, what do we really mean by function? • Two isoforms of human cyclooxygenase, COX-1 & COX-2 • COX-1 is expressed in healthy tissues; COX-2 is induced in inflammatory response • COX-1 and COX-2 have ~60% sequence identity, very similar overall structures, and identical catalytic residues
COX-1 (1cqe) COX-2 (1cx2) But, then, what do we really mean by function? • Aspirin/NSAIDs inhibit both isoforms; COX-1 inhibition can lead to gastrointestinal side effects • Newer COX-2 selective inhibitors (VioxxTM, CelebrexTM) have anti-inflammatory and pain killing benefits of NSAIDs with reduced side effects 1cqe: P RLVLTVRSNLI AQ TF –EFNQLYHWH –R FGM Y- GESMIEMGAPFSLK 1cx2: P –YVLTSRSYLI AQ TF SEFNTLYHWH YR FSL YLGETMVELGAPFSLK Goal: accurate identification of active sites and their similarities and differences
Fuzzy Functional Forms and Active Site Profiling • Advantage: computational method based on structure • Use of structural (not just sequence) information • Identification of key functional features (not annotation transfer via global sequence alignment) • Fast; can be globally applied to protein sequences • Disadvantage: computational method • Scoring function cutoffs • False positive and negative rates • Size of FFF library Fetrow & Skolnick. J. Mol. Biol. (1998) 282: 949-968. Cammer, Hoffman, Speir, Canady, Nelson, Knutson, Gallina, Baxter, Fetrow. J. Mol. Biol. (2003) 334:387-401.
B A C Geometric definition of an FFF • Defined by three metrics • Key residues (and their identity) involved in active site chemistry • Geometric constraints (distances between alpha carbons) • Allowed variability for geometric constraints • Training • Against all PDB structures • Relax constraints to identify all true positive structures, but no false positives • Cross validation Fetrow & Skolnick. J. Mol. Biol. (1998) 282: 949-968. Fetrow, Godzik & Skolnick. (1998) J. Mol. Biol. 282:703-711.
Advantages of the FFF approach FFF for redox regulatory site • Use of structural information enables: • Function annotation farther into “twilight zone” • Identification of similar functional sites in proteins of different structure • Functional complexity • Identification of multiple chemistries within a single functional site • Identification of multiple functions within a protein domain Serine-threonine phosphatase FFF 1=metal binding site FFF 2=metal binding site FFF 3=phosphatase catalytic residues Fetrow, Siew, Skolnick. FASEB J (1999) 13:1866-74
Comparison of putative redox active site residues PP1 PP2B PP2A
Cluster analysis of PP1, PP2A, and PP2B subfamilies PP1 PP2A PP2B
Comparison of putative redox active site residues PP2B PP2A PP1
Limitations of the FFF Approach • FFFs only uses identities of three residues • Leads to false positive identifications • FFF hit is only yes/no • Does not have a score or confidence associated with it • FFFs only identify key residues • Does not identity specificity—substrate or small molecule specificity
Active site signature: first step in active site profiling • Use FFF to identify key functional residues • Extract fragments in structural proximity to FFF residues • Arrange fragments to form a linear sequence—active site signature Cammer, Hoffman, Speir, Canady, Nelson, Knutson, Gallina, Baxter, Fetrow. J. Mol. Biol. (2003) 334:387-401.
Examples of residues identical across family Examples of residues different between family members—possible specificity determinants? Align signatures to create active site profile Profile segments for 7 enzymes identified by one FFF
Active Site Profile Score 1cozA_1 GTFDLLHWGHIKLLEAYRTISTTKIKEE 1cozB_1 GTFDLLHWGHIKLLEAYRTISTTKIKEE BS002557__1cozA GTFDPPHNGHLLMANDYREVSSTMIRER **** * **: : : ** :*:* *:*. • Empirically derived function takes into account sequence similarity • Enables approaches based on active site information • Clustering of functional families (profile score) • Novel sequence family and subfamily assignment (pairwise score) Identity Strong Weak 1.0 0.2 0.1
B B A A C C Validation of Active Site Profile Score • 193 real functional families • 193 FFFs applied to known structures from PDB to identify functional families • For each protein in each family, extract active site signature • Align all signatures in a given family to create profile • Calculate profile score • 193 decoy functional families • Geometric criteria “relaxed” slightly to identify first “false positive” • (Automatically identified as part of training procedure) • Extract signatures, align to create profile, calculate score
1ac5_ LNGGPC-GESYAGQY-IGNGWI-----NMYNFN-NGDKDLICNN-NASHMVPFD 1ivyA LNGGP--GESYAGIYIVGNGLSLFNIYNLY--N-NGDVDMACNF-GAGHMVPTD 1ysc_ LNGGP--GESYAGHY-IGNGLTMAGE-NVYDIRKAGDKDFICNWLNGGHMVPFD 1ivyB LNGGP--GESYAGIYIVGNGLSLFNIYNLYA-N-NGDVDMACNF-GAGHMVPTD 1cpy_ LNGGP-AGASYAGHYIIGNGLTMAG--NVYDIR-AGDKDFICNWLNGGHMVPFD ***** * **** * :*** *:* . ** *: ** ...**** * Active site profile for serine carboxypeptidases Profile score=0.42 Validation of the active site profile score
1ac5_ LNGGPC-GESYAGQY-IGNGWI-----NMYNFN-NGDKDLICNN-NASHMVPFD 1ivyA LNGGP--GESYAGIYIVGNGLSLFNIYNLY--N-NGDVDMACNF-GAGHMVPTD 1ysc_ LNGGP--GESYAGHY-IGNGLTMAGE-NVYDIRKAGDKDFICNWLNGGHMVPFD 1ivyB LNGGP--GESYAGIYIVGNGLSLFNIYNLYA-N-NGDVDMACNF-GAGHMVPTD 1cpy_ LNGGP-AGASYAGHYIIGNGLTMAG--NVYDIR-AGDKDFICNWLNGGHMVPFD ***** * **** * :*** *:* . ** *: ** ...**** * 1ac5_ LNGGPC-GESYAGQY--IGNGWI-----NMYNFN-NGDKDLICNN---NASHMVPFD 1ivyA LNGGP--GESYAGIYI-VGNGLSLFNIYNLY--N-NGDVDMACNF---GAGHMVPTD 1ysc_ LNGGP--GESYAGHY--IGNGLTMAGE-NVYDIRKAGDKDFICNWL--NGGHMVPFD 1ivyB LNGGP--GESYAGIYI-VGNGLSLFNIYNLYA-N-NGDVDMACNF---GAGHMVPTD 1cpy_ LNGGP-AGASYAGHYI-IGNGLTMAG--NVYDIR-AGDKDFICNWL--NGGHMVPFD 1c4xA LHGAG--GNSMGGAVTLMGSVG-----SFVY----HGRQDRIVPLTLDRCGHWAQLE *:*. * * .* :*. :* * * .* . : Validation of Active Site Profile Score Serine carboxypeptidase profile Score=0.42 Serine carboxypeptidase decoy profile Score=0.14
Validation of Active Site Profile Score • Profile score compared to decoy profile score shows clear separation for most families • Separation less distinct when decoy is functionally related to FFF family • Profile score ≥0.25 considered significant True profiles Decoy profiles
Prospective validation of the method • Human protein tyrosine phosphatases (PTPs) • PTPs are important signal transduction proteins • Analysis demonstrates accuracy and throughput • Yeast serine hydrolases • Serine hydrolases are crucial for many cellular processes • Analysis demonstrates experimental validation of sensitivity and accuracy of function annotations • Performance compared to other tools
Method for genome analysis • Download protein sequences encoded by human or yeast genome • Run Prospector (Skolnick, et al) fold recognition program • For any protein sequence that aligns with structure used to create FFF: • Take top 20 alignments (top five hits for four scoring functions) • Determine if FFF residues conserved • If yes: • Predict FFF function • Identify active site signature • Align and calculate pairwise profile score
PTP Functional Family • Catalytic site is found in multiple protein structures • Active site structure is conserved 2hnp, a classical PTP 1vhr, a dual specificity PTP 1phr, a low molecular weight PTP
Annotation of human genome sequences for PTP function • Identified over 150 human PTPs • Comparison to experimentally-verified PTPs shows that over 95% of known PTPs identified: false negative rate < 5% • Over 40 unique PTPs identified • Sequences that are not recognized as PTPs by any other method (including BLAST, Blocks, Prints and Pfam) How good are these function assignments?
Hydrolysis of pNPP by PTP #1 Functional Characterization of PTP Proteins • Clone, express, and purify • Test PTPs for biochemical function • Progress (before termination of project) • 49 soluble PTP domains purified • 37 PTPs active in vitro • Four active PTPs that were not previously recognized by other methods (including no recognizable similarity to any PTP in the public databases)
Functional Characterization of PTP Proteins • False positive rate cannot be absolutely determined; PTP project shows: • Total PTP proteins: 49 soluble proteins, with 37 active in pNPP hydrolysis assay (~25% not validated in assay) • PTP proteins unrecognized by other methods: 6 soluble proteins, with 4 active in pNPP hydrolysis assay (~33% not validated in assay) • Maximum false positive rate: ~25-33% • Why a maximum? • Only one substrate and assay condition tested • Small sample set
Active Site Profiling of Human PTPs: Identification of Sub-families • Identified over 150 human PTPs • Identify active site signature from each PTP sequence • Align to create active site profile for PTP family • Cluster to identify subfamilies of PTPs
Subfamily 1 Classical PTPs --Novel PTP#5 --Blast(global sequence similarity)indicates that PTP#5 is dual specificity PTP Subfamily 2 Subfamily3 Dual specificity PTPs and PTEN Subfamily4 All PTPs Subfamily5 --Clustering of active site profile indicates “PTP#5” falls into class 1 Subfamily6 Low molecular weight PTPs Subfamily7 Subfamily8 Active Site Profiling of Human PTPs: Identification of Sub-families
Summary of human PTP annotation project • 150 PTPs identified in human genome • Over 95% of previously annotated PTPs identified (false negative rate <5%) • Of those tested in our lab, 75% exhibited PTP function • 40 proteins not identified by other methods (BLAST, Blocks, Pfam) • Of those tested, 66% exhibited PTP function • Maximum false positive rate: 25-33% • Active site profiling subclassifies proteins differently than global sequence alignment
FFFs for Serine Hydrolases • 35 serine hydrolase FFFs describing 25 EC-defined functions • Nucleophilic serine in active site • Protease, lipase, esterase, amidase or transacylase function (FAD-independent-S-hydroxynitrile lyase, too) • Several “family” FFFs, including a/b hydrolase “family” FFF • 35 FFFs cover approximately 63% of known structural space and 23% of potential functional space
Identification of Yeast Serine Hydrolases by FFFs and Profiling • 6946 yeast protein sequences (NCBI and SGD) • Threading with PROSPECTOR against PDB structures • Analysis of top 20 threads (top five scores, four scoring functions) with serine hydrolase FFFs • If thread is “hit” by FFF, sequence is identified as a serine hydrolase (yes or no) • Active site profile scoring provides rank ordering of identified serine hydrolases; ≥0.25 is considered significant Skolnick & Kihara. (2001) Proteins 42:319-331. DiGennaro, Siew, Hoffman, Zhang, Skolnick, Neilson, Fetrow. (2001) J. Struct. Biol. 134:232-245.Fetrow, Godzik & Skolnick. (1998) J. Mol. Biol. 282:703-711.
Annotation of yeast genome for serine hydrolase functions • 147 proteins identified by combination of PROSPECTOR and serine hydrolase FFFs • 52 of 147 proteins identified by more than one serine hydrolase FFF • 55 of 147 proteins identified with significant active site profile score (≥0.25) • 7 proteinswere previously identified* as serine hydrolases (“knowns”) • Profile score≥0.25: Dap2, Kex1, Prb1, Prc1, Ste13, and Yjl068c • Profile score=0.23: Ppe1 How good are these function assignments? *Previously identified in SGD (http://genome-www.stanford.edu/Saccharomyces/)
High Throughput Screening Biological Samples Activity Probes Activity-based Probe Technology • Advantage: probe chemistry • Identifies functional proteins in complex mixtures • Fractionates proteome on basis of chemical reactivity (not protein abundance) • Disadvantage: probe chemistry • Specific for serine hydrolases? Patricelli, Giang, Stamp, Burbaum. (2001) Proteomics 1:1067-1071.Kidd, Liu & Cravatt. (2001) Biochemistry 40:4005-4015. Cravatt & Sorenson. (2000) Curr. Opin. Chem. Biol. 4:663-668.
Identification of Serine Hydrolases by ABPs • Yeast grown under four culture conditions • Cultures lysed, centrifuged, fractions labeled with ABP • Affinity chromatography; separation of labeled proteins by 1D PAGE • In-gel tryptic digest and LC-MS identification of peptides • High quality identifications: More than one peptide identified for a given protein
Results of ABP labeling experiments • 80 proteins uniquely labeled by ABP • 23 of 80 proteins identified with high quality mass spec data • 8 of 23 proteins were previously identified* as serine hydrolases (“knowns”): Dap2, Kex1, Ppe1, Prb1, Prc1, Ste13, Yjc068c and Amd2 • “unknowns”: Ygl039w, Ygl157w, Yml059c, Fas2, Ydr428c, Ynl123w, Yor084w, Eht1, Yju3, Ybr139w, Ybr204c, Yhr049c, Ylr118c, Ymr222c, and Yor280c *Previously identified in Saccharomyces Genome Database (SGD) (http://genome-www.stanford.edu/Saccharomyces/)
Comparison of computational and experimental results • Chemical proteomics: 23 high quality identifications • Computational/structural proteomics: 55 proteins identified with significant active site profile score (≥0.25) • 15 proteins identified by both methods (high quality identifications by both methods)
How well did the FFFs identify ABP-labeled proteins? • If all 23 proteins identified by ABP labeling are correct, then: • FFF identification: 15/23=65% • FFF coverage of structure space (“the best we could expect to do”): 65% • FFF coverage of biological function space (“the worst we could expect to do”): 23% • But, are all the ABP identifications actually serine hydrolases?
What did the FFFs miss? • 8 proteins identified by high quality ABP data, but not serine hydrolase FFFs • Amd2 (“8th known”) identified by ABP, but not FFF because no amidase FFF had been constructed • 3 proteins identified by dehydrogenase FFFs, not serine hydrolase FFFs (discussed subsequently) • 3 proteins with significant threading scores, no FFF hit • Yor084w (1a8uA): chloroperoxidase T (known serine hydrolase) • Fas2 (1kas): 3-oxo-ACP-reductase/synthase • Ynl123w (1pysB): tRNA synthetase • 1 protein (Ydr428c) yields no computational results
Advantages of Combining Methods: Clarification of ABP identifications • 3 proteins identified by high quality ABP data, but not serine hydrolase FFFs • Ygl039w, Ygl157w, and Yml059c • All three labeled by another family of FFFs (UDP-galactose-4-epimerase, estradiol-17-beta dehydrogenase, and 3-alpha, 20-beta-hydroxysteroid dehydrogenase) • Proteins in this family all have active site serine and tyrosine: possible site of ABP labeling • If these protein functions are correctly identified by the FFFs AND if other five ABP identifications are correct, then: • FFF identification: 18/23=78% (better than expected)
What about the “unknowns”? • 15 proteins identified by both methods • 7 of 8 “knowns” identified by both methods (Dap2, Kex1, Ppe1, Prb1, Prc1, Ste13, and Yjl068c) • 8 novel annotations of proteins as serine hydrolases (Eht1, Yju3, Ybr139w, Ybr204c, Yhr049w, Ylr118c, Ymr222c, and Yor280c) • All 8 annotated as “function unknown” or “hypothetical protein” in SGD • High confidence in novel annotations (two independently applied methods)
What about the “unknowns”? • 15 proteins identified by both methods • 7 of 8 “knowns” identified by both methods (Dap2, Kex1, Ppe1, Prb1, Prc1, Ste13, and Yjl068c) • 8 novel annotations of proteins as serine hydrolases (Eht1, Yju3, Ybr139w, Ybr204c, Yhr049w, Ylr118c, Ymr222c, and Yor280c) • All 8 annotated as “function unknown” or “hypothetical protein” in SGD • High confidence in novel annotations (two independently applied methods)
New Family of Eukaryotic Serine Hydrolases (FSH) • 3 yeast proteins (Yhr049w, Ymr222c, and Yor280c) identified by both ABP and FFFs • 3 sequences related by sequence similarity • All annotated as “function unknown” at SGD • None annotated with confidence by other computational methods (Prints, Pfam or Blocks)
New Family of Eukaryotic Serine Hydrolases (FSH) • These 3 proteins related to proteins from other eukaryotic proteomes (human, mouse, worm, fruit fly, mosquito, plant) • No NCBI biochemical annotations for any of these proteins (except one—see next slide)
S. cerevisiae Fsh1p S.cerevisiae Fsh2p S. cerevisiae Fsh3p S.pombe DYR_SCHPO S. cerevisiae DHFR Cautionary Tale for Annotation Transfer • One FSH protein, DYR_SCHPO, from S. pombe was annotated as a dihydrofolate reductase (DHFR) • Sequence analysis indicates a multidomain protein: contains both DHFR and serine hydrolase function • Possible biological connection between serine hydrolase and DHFR functions? • Annotation transfer methods would have assigned incorrect function to FSH family of proteins
Comparison to other computational methods: How much information does structure add? • ABPs identified 23 proteins with high confidence • FFFs identified 15 (65%) as serine hydrolases • Pfam identified 10 (43%) as serine hydrolases
Summary of yeast serine hydrolase annotation project • 15 serine hydrolase sequences identified by both methods • 7 of 8 known serine hydrolases identified by both methods (all eight identified by ABP labeling) • 8 new serine hydrolases identified (formerly annotated as “function unknown”) • New family of eukaryotic serine hydrolases (FSH) • FFF annotation clarifies molecular function of the three proteins identified by ABP labeling • More accurately identify limits of FFF and active site profiling accuracy • If 23 ABP identifications are correct, FFF correctly identifies function of 78% Baxter, et al. (2004) Mol. Cell Prot.
Structure-based annotation of protein function • Prospective experimental validation of predictions demonstrates accuracies (and limitations) of current methods • Mis-annotation of function continues to be a problem—found in all databases • Results suggest that a significant number of proteins will exhibit well-studied functions, but are not identified by current computational methods • Profiling of sequences around functional site provides additional information on function and specificity
Susan Baxter (NCGR) Melanie Nelson (SAIC) Stephen Cammer (SDSC) Brian Hoffman (Scitegic) Jen Montimurro (Wadsworth Ctr) Stacy Knutson (Wake Forest) Jeff Speir (Scripps) Jeannine DiGennaro (GeneVault) Steve Betz (Neurocrine) Marijo Galina Susan Okuley Chris Scott ActivX Jonathan Burbaum Jonathan Rosenblum Dan Giang Acknowledgements • (now Cengent Therapeutics)