Download

1 / 37
370 likes | 490 Views
Han-Ku Lee Department of Computer Science Florida State University Feb 19 th , 2002 hkl@csit.fsu.edu. Efficient Compilation of the HPJava Language for HPC. Outline. Background - review of data-parallel languages HPspmd Programming Language Model HPJava

E N D
Han-Ku Lee Department of Computer Science Florida State University Feb 19th, 2002 hkl@csit.fsu.edu Efficient Compilation of the HPJava Language for HPC hkl@csit.fsu.edu
Outline • Background - review of data-parallel languages • HPspmd Programming Language Model • HPJava • The compilation strategies for HPJava • Author’s contributions and Proposedwork • Conclusions and Current Status hkl@csit.fsu.edu
Research Objectives • Data-parallel programming and languages have played a major role in high-performance computing • HPF – difficult (compilation) • Library-based lower-level SPMD programming – successful • HPspmd programming language model – a flexible hybrid of HPF-like data-parallel language and the popular, library-oriented, SPMD style • Base-language for HPspmd model should be clean and simple object semantics, cross-platform portability, security, and popular – Java hkl@csit.fsu.edu
Proposed Work • Efficient Compilation of the HPJava Language for HPC • Main thrust of proposal work will be to explore effectiveness of optimizations in the HPspmd translator • Continue to investigate which optimization strategies are most critical in a wider range of applications in High Performance Compilers hkl@csit.fsu.edu
Data Parallel Languages • Large data-structures, typically arrays, are split across nodes • Each node performs similar computations on a different part of the data structure • SIMD – Illiac IV and Connection Machine for example introduced a new concept, distributed arrays • MIMD – asynchronous, flexible, hard to program • SPMD – loosely synchronous model (SIMD+MIMD) • Each node has its own local copy of program hkl@csit.fsu.edu
HPF(High Performance Fortran) • By early 90s, value of portable, standardized languages universally acknowledged. • Goal of HPF Forum – a single language for High Performance programming. Effective across architectures—vector, SIMD, MIMD, though SPMD a focus. • HPF - an extension of Fortran 90 to support the data parallel programming model on distributed memory parallel computers • Supported by Cray, DEC, Fujitsu, HP, IBM, Intel, Maspar, Meiko, nCube, Sun, and Thinking Machines hkl@csit.fsu.edu
Processors Memory Area HPF Ideal data distribution • Multi-processing and data distribution – communication and load-balance • Introduced processor arrangement and Templates • Data Alignment hkl@csit.fsu.edu
Features of HPJava • A language for parallel programming, especially suitable for massively parallel, distributed memory computers. • Takes various ideas from HPF. • e.g. - distributed array model • In other respects, HPJava is a lower levelparallel programming language than HPF. • explicit SPMD, needing explicit calls to communication libraries such as MPI or Adlib • The HPJava system is built on Javatechnology. • The HPJava programming language is an extension of the Java programming language. hkl@csit.fsu.edu
Benefits of our HPspmd Model • Translators are much easier to implement than HPF compilers. No compiler magic needed • Attractive framework for library development, avoiding inconsistent parameterizations of distributed array arguments • Better prospects for handling irregular problems – easier to fall back on specialized libraries as required • Can directly call MPI functions from within an HPspmd program hkl@csit.fsu.edu
HPspmd Architecture hkl@csit.fsu.edu
Multidimensional Arrays • Java is an attractive language, but needs to be improved for large computational tasks • Java provides an array of arrays => disadvantage • Time consumption for out-of bounds checking • The ability to alias rows of an array • The cost of accessing an element • HPJava introduces true multidimensional arrays and regular sections • For example int [[*,*]] a = new int [[5, 5]] ; for (int i=0; i<4; i++) a [i, i+1] = 19 ; foo ( a [[:, 0]] ) ; hkl@csit.fsu.edu
0 1 p Processes Proces2 p = new Procs(2, 3) ; on (p) { Range x = new BlockRange(N, p.dim(0)) ; Range y = new BlockRange(N, p.dim(1)) ; float [[-,-]] a = new float [[x, y]] ; float [[-,-]] b = new float [[x, y]] ; float [[-,-]] c = new float [[x, y]] ; … initialize ‘a’, ‘b’ overall (i=x for :) overall (j=y for :) c [i, j] = a [i, j] + b [i, j]; } • An HPJava program is concurrently started on all members of some process collection – process groups • on construct limits control to the active process group (APG), p 0 1 2 hkl@csit.fsu.edu
Distributed arrays • The most important feature of HPJava • A collective object shared by a number of processes • Elements of a distributed array are distributed • True multidimensional array • Can form a regular section of an distributed array • When N = 8 in the previous example code, the distributed array, ‘a’ is distributed like: hkl@csit.fsu.edu
BlockRange CyclicRange Range ExtBlockRange IrregRange CollapsedRange Dimension Distribution format • HPJava provides further distribution formats for dimensions of distributed arrays without further extensions to the syntax • Instead, the Range class hierarchy is extended • BlockRange, CyclicRange, IrregRange, Dimension • ExtBlockRange – a BlockRange distribution extended with ghost regions • CollapsedRange – a range that is not distributed, i.e. all elements of the range mapped to a single process hkl@csit.fsu.edu
Overall constructs overall (i = x for 1: N-2: 2) a[i] = i` ; • Distributed parallel loop • i– distributed index whose value is symbolic location (not integer value) • Index triplet represents a lower bound, an upper bound, and a step – all of which are integer expressions • With a few exception, the subscript of a distributed array must be a distributed index, and x should be the range of the subscripted array (a) • This restriction is an important feature, ensuring that referenced array elements are locally held hkl@csit.fsu.edu
Array Sections • HPJava supports subarrays modeled on the array sections of Fortran 90 • The new array section is a subset of the elements of the parent array • Triplet subscript • The rank of an array section is equal to the number of triplet subscripts • e.g. float [[-,-]] a = new float [[x, y]] ; float [[-]] b = a [[0, :]] ; float [[-,-]] u = a [[0 : N/2-1, 0 : N-1 : 2]] ; hkl@csit.fsu.edu
Distributed Array Type • Type signature of a distributed array T [[attr0, …, attrR-1]] bras where R is the rank of the array and each term attrr is either a single hyphen, - or a single asterisk, *, the term bras is a string of zero or more bracket pairs, [] • T can be any Java type other than an array type. This signature represents the type of a distributed array whose elements have Java type T bras • A distributed array type is not treated as a class type hkl@csit.fsu.edu
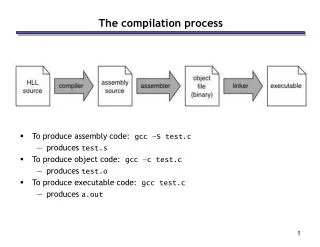
Basic Translation Scheme • The HPJava system is not exactly a high-level parallel programming language – more like a tool to assist programmers generate SPMD parallel code • This suggests the translations the system applies should be relatively simple and well-documented, so programmers can exploit the tool more effectively • We don’t expect the generated code to be human readable or modifiable, but at least the programmer should be able to work out what is going on • The HPJava specification defines the basic translation scheme as a series of schema hkl@csit.fsu.edu
Translation of a distributed array declaration Source: T [[attr0, …, attrR-1]] a ; TRANSLATION: T [] a ’dat ; ArrayBase a ’bas ; DIMENSION_TYPE (attr0) a ’0 ; … DIMENSION_TYPE (attrR-1) a ’R-1 ; where DIMENSION_TYPE (attrr) ≡ ArrayDim if attrr is a hyphen, or DIMENSION_TYPE (attrr) ≡ SeqArrayDim if attrr is a asterisk e.g. float [[-,*]] var ; float [] var__$DS ; ArrayBase var__$bas ; ArrayDim var__$0 ; SeqArrayDim var__$1 ; hkl@csit.fsu.edu
Translation of the overall construct SOURCE: overall (i = x for e lo : e hi : e stp) S TRANSLATION: Block b = x.localBlock(T [e lo], T [e hi], T [e stp]) ; Group p = apg.restrict(x.dim(), apg) ; for (int l = 0; l < b.count; l ++) { int sub = b.sub_bas + b.sub_stp * l ; int glb = b.glb_bas + b.glb_stp * l ; T [S | p] } where: i is an index name in the source program, x is a simple expression in the source program, e lo, e hi, and e stpare expressions in the source, S is a statement in the source program, and b, p, l, sub and glb are names of new variables hkl@csit.fsu.edu
OptimizationStrategies • Based on the observations for parallel algorithms such as Laplace equation using red-black iterations, distributed array element accesses are generally located in inner overall loops. • The complexity of the associated terms in the subscript expression of a distributed array element access. • Strength Reduction - introducing the induction variables • Loop-unrolling - hoisting the run-time support classes • Common-subexpression elimination • The novelty is in adapting these optimizations to make HPspmd practical hkl@csit.fsu.edu
Example of Optimization • Here we only consider strength reduction optimizations on the index expression • Consider the nested overall and loop constructs overall (i=x for :) overall (j=y for :) { float sum = 0 ; for (int k=0; k<N; k++) sum += a [i, k] * b [k, j] ; c [i, j] = sum ; } hkl@csit.fsu.edu
A correct but naive translation Block bi = x.localBlock() ; for (int lx = 0; lx<bi.count; lx ++) { Block bj = y.localBlock() ; for (int ly = 0; ly<bj.count; ly ++) { float sum = 0 ; for (int k = 0; k<N; k ++) sum += a.dat() [a.bas() + (bi.sub_bas + bi.sub_stp * lx) * a.str(0) + k * a.str(1)] * b.dat() [b.bas() + (bj.sub_bas + bj.sub_stp * ly) * b.str(1) + k * b.str(0)] ; c.dat() [c.bas() + (bi.sub_bas + bi.sub_stp * lx) * c.str(0) + (bj.sub_bas + bj.sub_stp * ly) * c.str(1)] = sum; } } hkl@csit.fsu.edu
Strength-Reduction Optimization • The problem is the complexity of the associated terms in the subscript expressions • The subscript expressions can be greatly simplified by application of strength-reduction optimization • Eliminate complicated expressions involving multiplication from expressions in inner loops by introducing the induction variables: • Which can be computed efficiently by increasing at suitable points with the induction increments: hkl@csit.fsu.edu
Why benchmark ? • Before adapting optimization strategies in HPJava translator, need to benchmark hand-coded optimizations • Need to prove distributed arrays in Java don’t introduce unacceptable overhead hkl@csit.fsu.edu
Benchmarks • Benchmarked on Linux Red Hats 7.2 (Pentium IV 1.5 GHZ) • Linpack, Matrix-Multiplication, Laplace Equations using red-black relaxation • IMB Developer kits 1.3 (JIT) • Compared Java and HPJava with GNU cc and Fortran77 hkl@csit.fsu.edu
Comparison of base languages • daxpy() kernel in Linpack • N = 200, iter = 100000 with Maximal Optimization hkl@csit.fsu.edu
HPJava: Matrix Multiplication • N = 100, iter =100 with Maximal Optimization • HPJava uses a single-processor hkl@csit.fsu.edu
Laplace Equestion using red-black relaxation • N = 500, count = 100 with Maximal Optimization hkl@csit.fsu.edu
Benchmark results • Naïve HPJava is slow because allows for distributed arrays – complexity of subscripting • Practical optimizations can remove these overhead • HPJava results for a single processor – expected scale with multiple-processors • Java is quite competitive with other languages hkl@csit.fsu.edu
Fortran is sometimes slower than C ? • Could say “performance of Fortran and C” are same • But, depends upon compilers • GNU Fortran 77 compiler generates more machine codes than GNU cc compiler does for main loop in Linpack hkl@csit.fsu.edu
Author’s Contributions to HPJava • Developing and maintaining the HPJava front-end and back-end environments at NPAC, CSIT, and Pervasive Technology Labs. • Translator, Type-Checker, and Type-Analyzer of HPJava. • Some of his early works at NPAC • Unparser and Abstract Expression Node generator, and original implementation of the JNI interfaces of the run-time communication library, Adlib. hkl@csit.fsu.edu
Current Status of HPJava • Collaborated with Bryan Carpenter, Geoffrey Fox, Guansong Zhang, Sang Lim and Zheng Qiang • The first fully functional HPJava translator (written in Java) is now operational • Parser – JavaCC and JTB tools • Has been tested and debugged against small test suite and 800-line multigrid code hkl@csit.fsu.edu
Future Work • Efficient Compilation of the HPJava Language for HPC • optimizations of HPJava • Main thrust of proposal work will be to explore effectiveness of optimizations in the HPspmd translator • First, need to know which optimization strategies should be applied, by experimenting with hand-coded optimizations in HPJava and need to benchmark on parallel machines such as SP3 • Next, develop the optimized HPJava translator, test codes and applications over next few months • Will continue to investigate which optimization strategies are most critical in a wider range of applications in HPspmd compilers hkl@csit.fsu.edu
Publications and Plans • Han-Ku Lee, Bryan Carpenter, Geoffrey Fox, Sang Boem Lim. Benchmarking HPJava: Prospects for Performance. Feb 8, 2002. Submitted to Sixth Workshop on Languages, Compilers, and Run-time Systems for Scalable Computers(LCR2002). http://motefs.cs.umd.edu/lcr02/ • Bryan Carpenter, Geoffrey Fox, Han-Ku Lee, and Sang Lim. Node Performance in the HPJava Parallel Programming Language. Feb, 2002. The 16th Annual ACM International Conference on Super Computing(ICS2001). http://www.lcpcworkshop.org/LCPC2001/ • Bryan Carpenter, Geoffrey Fox, Han-Ku Lee, and Sang Lim. Translation of the HPJava Language for Parallel Programming. May 31, 2001. The 14th annual workshop on Languages and Compilers for Parallel Computing(LCPC2001). http://www.lcpcworkshop.org/LCPC2001/ • Bryan Carpenter, Guansong Zhang, Han-Ku Lee, and Sang Lim. Parallel Programming in HPJava. Draft of May 2001. http://aspen.csit.fsu.edu/pss/HPJava/ hkl@csit.fsu.edu
Conclusions • Reviewed data-parallel languages such as HPF • Introduced HPspmd programming language model – SPMD framework for using libraries based on distributed arrays • Specific syntax, new control constructs, basic translation schemes, and basic optimization strategies for HPJava • Proposed work: • Efficient Compilation of the HPJava Language for HPC hkl@csit.fsu.edu
Acknowledgements • This work was supported in part by the National Science Foundation (NSF ) Division of Advanced Computational Infrastructure and Research • Contract number – 9872125 hkl@csit.fsu.edu