Download

1 / 10
100 likes | 250 Views
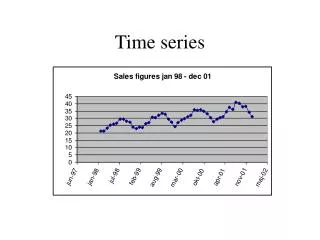
GHS Time Series Dataset. Melissa Davy Senior Research Officer Office for National Statistics. The dataset. Combined dataset of the GHS from 1972 to 2004 for selected variables. Why created?. Social Inequalities Branch Changes overtime and by birth cohort in measures of inequalities

E N D
GHS Time Series Dataset Melissa Davy Senior Research Officer Office for National Statistics
The dataset • Combined dataset of the GHS from 1972 to 2004 for selected variables.
Why created? • Social Inequalities Branch • Changes overtime and by birth cohort in measures of inequalities • No sources of data available which provided what we needed
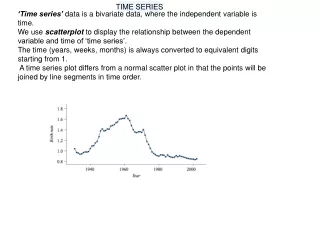
What is pseudo-cohort analysis? • Cohort analysis - panel data - same individual • Pseudo-cohort analysis - cross-sectional data - average experience of a given cohort • For example - aged 20 to 25 in a 1980 survey = 21 to 26 in 1981 = 22 to 27 in 1982 = 44 to 49 in 2004.
General Household Survey • more than 30 years of data • Covers a range of topics • Relatively large sample size • High quality data source
Extending scope of the project • Disadvantages - Time consuming • Advantages • Valuable research tool • Exploiting full potential of the GHS data • Makes time series analysis easier
Dataset creation • Deciding which variables. • Tracking variable over time • Selected the variables for each year • Matching the datasets together • Syntax to re-categories & re-name variables • Derived variables. • Long process with various complications, documented in Uren (2006)
What is on the dataset? • Years: 1972 to 2004 • Variables contains over 80 variables (i.e. demographics, households, education, employment, health & smoking) • Cases Over 0.8 million individuals Over 0.3 million households
Accessing & using the dataset • Essex data archive • Accompanying user guide • Enquires: govsurveys@esds.ac.uk
Related publications • Uren Z (2006) The GHS Pseudo Cohort Dataset (GHSPCD): Introduction and Methodology. Survey Methodology Bulletin, no 59, pp25-37. NB, originally the GHS Time Series Dataset was referred to as the GHS Pseudo-Cohort Dataset (GHSPCD) (www.statistics.gov.uk/cci/article.asp?ID=1637&Pos=1&ColRank=1&Rank=1) • Davy M (2006) Time and generational trends in smoking among men and women in Great Britain, 1972-2003/04, Health Statistics Quarterly 32, pp.35-43. (http://www.statistics.gov.uk/statbase/Product.asp?vlnk=6725) • Davy M (2007) Socio-economic inequalities in smoking: an examination of generational trends in Great Britain, Health Statistics Quarterly, 34. (Will be published in May 2007)