Download

1 / 43
430 likes | 787 Views
The standard error of the sample mean and confidence intervals. How far is the average sample mean from the population mean? In what interval around mu can we expect to find 95% or 99% or sample means. An introduction to random samples.

E N D
The standard error of the sample mean and confidence intervals How far is the average sample mean from the population mean? In what interval around mu can we expect to find 95% or 99% or sample means
An introduction to random samples • When we speak about samples in statistics, we are talking about random samples. • Random samples are samples that are obtained in line with very specific rules. • If those rules are followed, the sample will be representative of the population from which it is drawn.
Random samples: Some principles • In a random sample, each and every score must have an equal chance of being chosen each time you add a score to the sample. • Thus, the same score can be selected more than once, simply by chance. (This is called sampling with replacement.) • The number of scores in a sample is called “n.” (Small n, not capital N.) • Sample statistics based on random samples provide least squared, unbiased estimates of their population parameters.
The first way a random sample is representative of its population • One way a random sample will be representative of the population is that the sample mean will be a good estimate of the population mean. • Sample means are better estimates of mu than are individual scores. • Thus, on the average, sample means are closer to mu than are individual scores.
The variance and the standard deviation are the basis for the rest of this chapter. • In Chapter 1 you learned to compute the average squared distance of individual scores from mu. We called it the variance. • Taking a square root, you got the standard deviation. • Now we are going to ask a slightly different question and transform the variance and standard deviation in another way.
As you add scores to a random sample • Each randomly selected score tends to correct the sample mean back toward mu • If we have several samples drawn from a single population, as we add scores to each sample, each sample mean gets closer to mu. • Since they are all getting closer to mu, they will also be getting closer to each other.
As you add scores to a random sample – larger vs. smaller samples • The larger the random samples, the closer their means will be to mu, on the average. • The larger the random samples, the closer their means will be to each other, on the average.
Let’s see how that happens Population is 1320 students taking a test. is 72.00, = 12 Let’s randomly sample one student at a time and see what happens.We’ll create a random sample with 8 students’ scores in the sample.
Scores Mean Standard deviations 3 2 1 0 1 2 3 102 72 66 76 66 78 69 63 Test Scores F r e q u e n c y score 36 48 60 96 108 72 84 Sample scores: Means: 87 80 79 76.4 76.7 75.6 74.0
Which sample means are likely to be closer to each other.1. The means of three random samples, each with an n of 102. The means of three random samples, each with an n of 5
The larger samples should be closer, on the average, to mu, and therefore closer to each other.
How much closer to mu does the sample mean get when you increase n, the size of the sample? (1) • The average squared distance of individual scores is called the variance. You learned to compute it in Chapter 1. • The symbol for the mean of a sample is the letter X with a bar over it.We will write that as X-bar or
How much closer to mu does the sample mean get when you increase n, the size of the sample? (2) • The average squared distance of sample means from mu is the average squared distance of individual scores from mu divided by n, the size of the sample. • Let’s put that in a formula • sigma2X-bar = sigma2 = sigma2/n
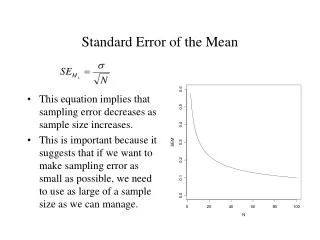
The standard error of the sample mean • As you know, the square root of the variance is called the standard deviation. It is the average unsquared distance of individual scores from mu. • The average unsquared distance of sample means from mu is the square root of sigma2X-bar • The square root of sigma2X-bar = sigmaX-bar. sigmaX-bar is called the standard error of the sample mean or, more briefly, the standard error of the mean. Here are the formulae sigma2X-bar = sigma2/n sigmaX-bar = sigma/
The standard error of the mean • Let’s translate the formula into English, just to be sure you understand it. Here is the formula again: sigmaX-bar = sigma/ • In English: The standard error of the sample mean equals the ordinary standard deviation divided by the square root of the sample size.
Another way to say that: The average unsquared distance of sample means from the population mean (mu) equals the average unsquared distance of individual scores from the population mean divided by the square root of the sample size.
Still another way to say the same thing.The standard error of the mean is the standard deviation of the sample means around mu.This sometimes confuses people. If it confuses you, just remember: The standard error of the mean is the averaged unsquared distance of sample means from mu.
Let’s check and make sure that the formula is correct. Let’s see that the standard error equals the ordinary standard deviation divided by the square root of n. To do that, let’s start with a tiny population: N=5 • Here are all the scores in a population: 1,3,5,7,9. • The scores in this population form a perfectly rectangular distribution. • Mu = 5.00
Computing sigma • SS=(1-5)2+(3-5)2+(5-5)2+ (7-5)2+ (9-5)2=40 • sigma2=SS/N=40/5=8.00 • sigma = 2.83
If we did compute a standard deviation of sample means from mu, it should give the same result as the formula • Let’s see if it does. • We can only do all the computations if we have a very small population and an even tinier sample. • Let’s use the population of 5 scores we just looked at (sigma = 2.83). We’ll use samples with n = 2. • If the formula is right, the average unsquared distance of sample means, n=2, should be 2.83/ = 2.83/1.414 = 2.00. • Is that right? To find out, let’s compute the standard error of the mean from the differences between the means of all possible samples (n=2) from mu (the mean from the population of scores 1,3,5,7,9).
The standard error = the standard deviation divided by the square root of n, the sample size • The formula works. And it works every time. • By the way the mean of the samples (125/25=5.00 = mu) is the mean of the population. And that works every time too.
Let’s see what sigmaX-bar can tell us • We know that the mean of SAT/GRE scores = 500 and sigma = 100 • So 68.26% of individuals will score between 400 and 600 and 95.44% will score between 300 and 700 • REMEMBER THAT SAMPLE MEANS FALL CLOSER TO MU, ON THE AVERAGE, THAN DO INDIVIDUAL SCORES.
What happens when we take random samples with n=4? • The standard error of the mean is sigma divided by the square root of the sample size = 100/ =100/2=50.00. These sample means will form a lovely normal curve around the population mean (mu=500) with a standard deviation equal to the standard error of the mean = 50.00 • 68.26% of the sample means (n=4) will be within 1.00 standard error of the mean from mu and 95.44% will be within 2.00 standard errors of the mean from mu • So, 68.26% of the sample means (n=4) will be between 450 and 550 and 95.44% will fall between 400 and 600
Let’s make the samples larger • Take random samples of SAT scores, with 400 people in each sample, the standard error of the mean is sigma divided by the square root of 400 = 100/ = 100/20=5.00. • These sample means will form a lovely normal curve around the population mean (mu=500) with a standard deviation equal to the standard error of the mean = 5.00 • 68.26% of the sample means will be within 1.00 standard error of the mean from mu and 95.44% will be within 2.00 standard errors of the mean from mu. • So, 68.26% of the sample means (n=400) will be between 495 and 505 and 95.44% will fall between 490 and 510.
You try it with random samples of verbal SAT scores, with 2500 people in each sample. • In what interval can we expect that 68.26% of the sample means will fall? • In what interval can we expect 95.44% of the sample means to fall?
With n= 2500, the standard error of the mean is sigma divided by the square root of 2500 = 100/50=2.00. • So on the verbal part of the SAT, the average (unsquared) distance of samples (n=2500) is 2.00 points • 68.26% of the sample means will be within 1.00 standard error of the mean from mu and 95.44% will be within 2.00 standard errors of the mean from mu. • 68.26% of the sample means (n=2500) will be between 498 and 502 and 95.44% will fall between 496 and 504
A slightly tougher question • Using SAT scores, with n=2500: • Into what interval should 95% of the sample means fall?
A slightly tougher question • 95% of the sample means should fall within 1.960 standard errors of the mean from mu. • Given that sigmaX-bar =2.00, you multiply 1.960 * sigmaX-bar = 1.960 x 2.00 = 3.92
Thus: • 95% of the sample means should fall in an interval that goes 3.92 points in both directions around mu • 500 – 3.92 = 496.08 • 500 + 3.92 = 503.92 • So 95% of sample means (n=2500) should fall between 496.08 and 503.92
What happens as n increases? • The sample means get closer to each other and to mu. • Their average squared distance from mu equals the variance divided by the size of the sample. • Therefore, their average unsquared distance from mu equals the standard deviation divided by the square root of the size of the sample. • The sample means fall into a more and more perfect normal curve. • These facts are called “The Central Limit Theorem” and can be proven mathematically.
We want to define two intervals around mu:One interval into which 95% of the sample means will fall. Another interval into which 99% of the sample means will fall.
95% of sample means will fall in a symmetrical interval around mu that goes from 1.960 standard errors below mu to 1.960 standard errors above mu • A way to write that fact in statistical language is: CI.95: mu + 1.960 sigmaX-bar or CI.95: mu - 1.960 sigmaX-bar < X-bar < mu + 1.960 sigmaX-bar
As I said, 95% of sample means will fall in a symmetrical interval around mu that goes from 1.960 standard errors below mu to 1.960 standard errors above mu • Take samples of SAT/GRE scores (n=400) • Standard error of the mean is sigma divided by the square root of n=100/ = 100/20.00=5.00 • 1.960 standard errors of the mean with such samples = 1.960 (5.00)= 9.80 • So 95% of the sample means with n=400 can be expected to fall in the interval 500+9.80 • 500-9.80 = 490.20 and 500+9.80 =509.80 CI.95: mu + 1.960 sigmaX-bar = 500+9.80 or CI.95: 490.20 < X-bar < 509.20
99% of sample means will fall within 2.576 standard errors from mu • Take the same samples of SAT/GRE scores (n=400) • The standard error of the mean is sigma divided by the square root of n=100/20.00=5.00 • 2.576 standard errors of the mean with such samples = 2.576 (5.00)= 12.88 • So 99% of the sample means can be expected to fall in the interval 500+12.88 • 500-12.88 = 487.12 and 500+12.88 =512.88 CI.99: mu + 2.576 sigmaX-bar = 500+12.88 or CI.99: 487.12 < the sample mean < 512.88
You do one. • What is the 95% confidence interval for samples of 25 randomly selected IQ scores? • To do the problem, first compute the standard error for samples of 25 IQ scores • IQ: mu =100, sigma = 15
Compute sigmaX-bar • First compute the standard error for samples of 25 IQ scores • IQ: mu =100, sigma = 15 • Standard error for samples of size 25 is 15 divided by the square root of 25 = 15/5.00 =3.00
IQ scores – Interval into which 95% of samples n=25 should fall, sigma = 3.00 • 95% of the sample means should fall within 1.960 standard errors of mu = 1.960 (3.00) = 5.88 points • 100-5.88 = 94.12 and 100+5.88 =105.88 So, 95% of sample means (n=25) for IQ scores should fall into the range from 94.12 to 105.58.
How do we express that as a 95% confidence interval? • 95% of the sample means should fall within 1.960 standard errors of mu = 1.960 (3.00) = 5.88 points • 100-5.88 = 94.12 and 100+5.88 =105.88 • To express that as a confidence interval, we can write it in either of two ways CI.95: mu + 1.960 sigmaX-bar = 100+5.88 or CI.95: 94.12 < X-bar < 105.88