Download
1 / 9
90 likes | 242 Views
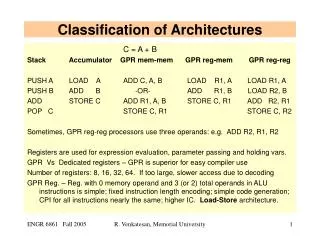
Classification of Architectures. C = A + B Stack Accumulator GPR mem-mem GPR reg-mem GPR reg-reg PUSH A LOAD A ADD C, A, B LOAD R1, A LOAD R1, A PUSH B ADD B -OR- ADD R1, B LOAD R2, B

E N D
Classification of Architectures C = A + B Stack Accumulator GPR mem-mem GPR reg-mem GPR reg-reg PUSH A LOAD A ADD C, A, B LOAD R1, A LOAD R1, A PUSH B ADD B -OR- ADD R1, B LOAD R2, B ADD STORE C ADD R1, A, B STORE C, R1 ADD R2, R1 POP C STORE C, R1 STORE C, R2 Sometimes, GPR reg-reg processors use three operands: e.g. ADD R2, R1, R2 Registers are used for expression evaluation, parameter passing and holding vars. GPR Vs Dedicated registers – GPR is superior for easy compiler use Number of registers: 8, 16, 32, 64. If too large, slower access due to decoding GPR Reg. – Reg. with 0 memory operand and 3 (or 2) total operands in ALU instructions is simple; fixed instruction length encoding; simple code generation; CPI for all instructions nearly the same; higher IC. Load-Store architecture. R. Venkatesan, Memorial University
Memory Addressing • Byte addressable memory means each byte has a unique address: almost always used so that one character can be modified selectively. • Each word consists of several bytes. If the wordsize is 64 bits, then each word spans eight addresses. • Memory access: read (load) or write (store). • Store (write) operation should be able to access 1 byte, quarter word, half word or 1 word at a time so that one character, short integer, integer/SPFP, long integer/DPFP can be modified as required. • For orthogonality, load (read) operations also facilitate access to 1 byte, quarter word, half word or 1 word accesses. • Little endian: if the lsB of the word has the address xxx…xx000 • Big endian: if the msB of the word has the address xxx…xx000 • Aligned memory access restriction: word should be located starting at address xxx…xx000, and not with any address that ends with any other 3-bit combination. This could mean a few wasted memory locations, but a complex alignment network is avoided, thus making t smaller. R. Venkatesan, Memorial University
Addressing Modes • Dozens of memory addressing modes have been used in CISC systems such as IBM 360, 370 and VAX 11. • Detailed statistical analyses have been carried out on CISC computers, and results are discussed in the textbook. • Registers are used as operands 50% of the time. • Displacement mode (index + disp.) is used 25% of the time. • Immediate addressing is used 20% of the time. • All other addressing modes are used <5% of the time, totally. • Therefore, it is efficient to design load-store processors with only displacement memory addressing mode, as long as the instruction set permits immediate operands as well. This way, we will not need a bit field in each load or store instruction to identify the memory addressing mode. If an unavailable mode be needed, use multiple instructions. • Displacement value: 12 bits capture 75% and 16 bits 99% of cases. • Immediate address: comparisons, const. in reg. move, shifts, etc. • Immediate value: 8 bits cover 70%, 16 bits cover 80%. R. Venkatesan, Memorial University
Operations in the Instruction Set • ALU reg-reg; ALU imm.; load; store; control transfer; FP; system, string, graphics, decimal, and others that are needed, but occurring rarely. • Control transfer: Jump or Branch (PC relative) ; Conditional or unconditional; call; return; s/w interrupts; trap. Most common: conditional branches with 8-12 bit value. 75% are forward branches. • Register indirect jumps are useful in case or switch instructions, dynamically shared libraries, virtual functions in C++, returns. • Most compares use an immediate 0 operand. • Condition code (flag): simple but constrain instruction ordering. • Condition register: test arbitrary register with result of comparison. • Compare and branch: one complex instruction; not good in pipelining. • State saving for procedure calls: caller saving or callee saving. • Media and signal processing: partitioned add enables four 16-bit adds in a 64-bit ALU in one cycle; SIMD or vector instructions; paired single operations using DPFP registers for vertices; saturating arithmetic; MAC or multiply accumulate. R. Venkatesan, Memorial University
Type and Size of Operands • Most modern processors place another restriction: operands in ALU instructions should always be 1 word long. This simplifies the hardware, thus reducing t. • Character, integer (+ short, long), SPFP, DPFP, Boolean are common. • Fixed point data type for DSPs. 0.000000000000000 assumed binary point in a fixed location; range: -1 to +1-2-15. • DSP: blocked fixed point: exponent separately kept (scaling) and shared between a set of fixed-point variables. • Decimal: BCD or packed decimal. • Media or graphics operations would benefit from data types such as vertex: x, y, z coordinates and w for color; each 32 bit FP. pixels: R, G, B, A (transparency): 4 x 8 = 32 bits. • DSP: modulo or circular addressing mode; bit reverse addressing. R. Venkatesan, Memorial University
CISC vs RISC • Three (selected) instructions are sufficient to design a processor that can be used to run any application; even simple operations will take a very large number of repetitions of these three instructions. • CISC processors provide several hundreds to thousands of instructions but the compilers do not use most of the esoteric instructions. • Most modern processors employ about a 100 instructions and thus essentially follow RISC architecture. • They employ fixed instruction lengths (32 bytes, for example); impose aligned memory access constraint; all ALU operations are done on word-sized operands; provide only one or a few addressing modes; do not use flags but use a GPR for compare. Floating-point operations are almost always used. • Processors released in the past ten years include graphics, DSP and multimedia operations and data types to facilitate such operations. • Examples of processors with good architectures: MIPS, Alpha, SUN Sparc, Intel iPSC860. R. Venkatesan, Memorial University
Role of compilers • Compiler based issues: • Regularity and orthogonality: operations, data types, addr. modes • Provide primitives, not solutions • Simplify trade-offs among alternatives • Provide instructions that bind the quantities known at compile time as const. • Compiler optimizations: • High-level optimizations: often done on source with output fed to later optimization passes. Example: procedure integration. • Local optimizations: optimize code only within a straight line code fragment; aka basic block. Examples: common expression elimination; constant propagation, stack height reduction. • Global optimizations: extend local optimizations across branches and introduce a set of transformations aimed at optimizing loops. Examples: copy propagation, code motion, induction variable elimination. • Register allocation: associates registers with operands. • Processor-dependent optimizations: Examples: pipeline scheduling, branch offset optimization, replace multiplies with adds and shifts. R. Venkatesan, Memorial University
MIPS 64 Architecture • 64-bit load-store architecture; can select little or big endian (mode bit). • 32 64-bit GPRs (integer registers). R0 always has 0 and is read-only; R31 is used with calls; all other GPRs are identical in usability. • 32 64-bit FPRs. F0 … F31 can hold SPFP or DPFP numbers; when SPFP is loaded the other half of FPR is used. • Aligned memory access; only addressing mode is displacement; memory access as bytes, half words, words or double words – 64-bit number is called a double word! LD, SD, LW, LWU, SW, LH, LHU, SH, LB, LBU, SB. msbits are loaded with sign bit or zero (unsigned). • ALU operands are always 64 bits long. DADD, DADDI, DADDU, DADDIU, DSUB, DSUBU, DMUL, DMULU, DDIV, DDIVU, MADD, AND, ANDI, OR, ORI, XOR, XORI, LUI (load bits 32-47 with imm. and sign-extend), DSLL, DSRL, DSRA, DSLLV, DSRLV, DSRAV, SLT, SLTI, SLTU, SLTIU. • Control: BEQZ, BNEZ, BEQ, BNE, BCIT, J, JR, JAL, JALR, TRAP • FP: ADD.D, ADD.S, ADD.PS; SUB.D, MUL.D, MADD.D, DIV.D, etc. R. Venkatesan, Memorial University
MIPS 64 Instruction Formats R. Venkatesan, Memorial University