Download

1 / 10
100 likes | 174 Views
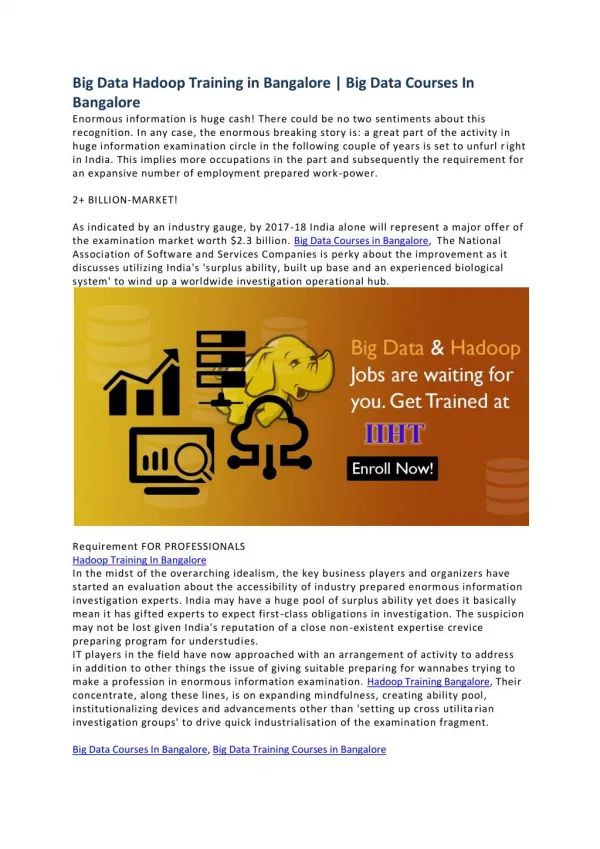
We provide complete and fully fledged Big Data Hadoop Training in Bangalore to enhance subject knowledge of the students. Candidates acquire knowledge in both technical aspects as well as practical aspects.<br>http://www.kellytechno.com/Bangalore/Course/Hadoop-Training

E N D
Best Hadoop Training In Bangalore HDFS OVERVIEW Powered By Contact Us info@kellytechno.com 080-6012 6789, +91 784 800 6789
HDFS OVERVIEW • Features of HDFS • HDFS Architecture • Goals of HDFS www.kellytechno.com
HDFS OVERVIEW • Hadoop File System was specialized through distributed file system design. It is actually run on commodity hardware. When compared to all the other distributed systems, HDFS is definitely fault-tolerant as well as specifically created by using low price hardware. • HDFS maintains very big volume of data and allows for easier access. To keep those huge data, the information is saved across multiple machines. All these files are stored in redundant manner to retrieve the system from available data losses in times of failure. HDFS also can make applications available to similar processing. www.kellytechno.com
Features of HDFS • It is suitable for the distributed storage and processing. • Hadoop presents a command interface to communicate with HDFS. • The built-in servers of name node and data node help users to easily monitor the status of cluster. • Streaming access to file system data. • HDFS allows for file permissions and authentication. www.kellytechno.com
HDFS Architecture • Provided below is the architecture of a Hadoop File System. www.kellytechno.com
HDFS follows the master-slave architecture and it has the following elements. • Namenode The name node is the commodity hardware that contains the GNU/Linux operating system as well as the name node software . It is a software that is able to be run on commodity hardware . The system having the name node acts as the master server and it happens the following tasks : • Manages the file system namespace. • Regulates client’s access to files. • It also executes file system operations such as renaming, closing, and opening files and directories. www.kellytechno.com
Data node The data node is a commodity hardware having the GNU/Linux operating system and data node software. For each and every node (Commodity hardware/System) in a cluster, there will be a data node. These nodes maintain the data storage of their system. • Data nodes perform read-write operations on the file systems, in respect to client request. • They also perform operations such as block creation, deletion, and replication according to the instructions of the name node. www.kellytechno.com
Block Normally the user data is stored in the files of HDFS . The file in a file system are going to be split up into a number of segments and/or stored in individual data nodes . These file segments are called as blocks . In simple terms , the minimum amount of data that HDFS can read or write is called a Block . The default block size is 64MB , but it can be increased as per the required to change in HDFS configuration . www.kellytechno.com
Goals of HDFS • Fault detection and recovery: Since HDFS consists of a large number of commodity hardware , failure of components is often . Because of that HDFS will need to have mechanisms for quick and automatic fault detection and recovery . • Huge datasets: HDFS should create different nodes per cluster to maintain the applications containing huge datasets . • Hardware at data: A requested task can be used efficiently , when ever the computation takes place near the data . Specifically whereas huge datasets are involved , it will reduce the network traffic and increases the throughput . www.kellytechno.com
Thank you! Presented By www.kellytechno.com