Download

1 / 64
640 likes | 872 Views
Scheduling. What’s the problem?. Have some work to do know subtasks Have limited resources Have some constraints to meet Want to optimize quality. Outline. Overview shop scheduling data-flow scheduling real-time scheduling OS scheduling Real-time scheduling RTOS generation

E N D
Scheduling EE249
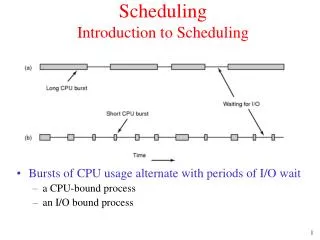
What’s the problem? • Have some work to do • know subtasks • Have limited resources • Have some constraints to meet • Want to optimize quality EE249
Outline • Overview • shop scheduling • data-flow scheduling • real-time scheduling • OS scheduling • Real-time scheduling • RTOS generation • scheduling • Communication • Data-flow scheduling • pure • Petri nets EE249
Shop scheduling Single job, one time • finite and known amount of work • multiple resources of different kind • often minimize lateness • could add release, precedence, deadlines, ... SOLUTION: compute the schedule APPLICATION: manufacturing EE249
Data-flow scheduling Single-job, repeatedly • known amount of work • simple subtasks • multi-processor • max. throughput, min. latency SOLUTION: code generation APPLICATION: signal processing EE249
Data-flow scheduling variants • Work • data dependent (BDF, FCPN) • Resources • many different execution units (HLS) • Goal • min. code, min. buffers, min. resources EE249
Real-time scheduling Fixed number of repeating jobs • each job has fixed work • job is a sub-task • processor(s) • meet individual deadlines SOLUTION: choose policy, let RTOS implement it APPLICATION: real-time control EE249
RT scheduling variants • Work • sporadic or event-driven tasks, • variable (data dependent) work • coordination between tasks: • mutual exclusion, precedence, … • Goal • event loss, input or output correlation, freshness, soft deadlines, ... EE249
OS scheduling Variable number of random tasks • know nothing about sub-tasks • processor + other computer resources • progress of all tasks, average service time SOLUTION: OS implements time-slicing APPLICATION: computer systems EE249
Outline • Overview • shop scheduling • data-flow scheduling • real-time scheduling • OS scheduling • Real-time scheduling • RTOS generation • Scheduling • Communication • Data-flow scheduling • pure • Petri nets EE249
RTOS functions • Enable communication between software tasks, hardware and other system resources • Coordinate software tasks • keep track which tasks are ready to execute • decide which one to execute: scheduling EE249
Outline • Implementing communication through events • Coordination: • classic scheduling results • reactive model of real-time systems • conservative scheduling analysis • priority assignment EE249
The scheduling problem • Given: • estimates on execution times of each task • timing constraints • Find: • an execution ordering of tasks that satisfies constraints • A schedule needs to be: • constructed • validated EE249
Off-line vs. on-line scheduling • Plus side: • simpler • lower overhead • highly predictable • Minus side • bad service to urgent tasks • independent of actual requests EE249
Scheduling Algorithms • off-line (pre-run-time, static) • round-robin, e.g. • C1 C2 C3 C4 C1 C2 C3 C4 C1 C2 C3 C4 … • static cyclic, e. g. • C1 C2 C3 C2 C4 C1 C2 C3 C2 C4 C1 C2 … • on-line (run-time, dynamic) • static priority • dynamic priority • preemptive or not EE249
Static priority scheduling • synthesis: • priority assignment • RMS [LL73] • analysis • Audsley 91 EE249
Rate Monotonic Scheduling • Liu -Layland [73]consider systems consisting of tasks: • enabled periodically • with fixed run time • that should be executed before enabled again • scheduled preemptively with statically assigned priorities EE249
Rate Monotonic Scheduling • giving higher priority to tasks with shorter period (RMS) is optimal • if any other static priority assignment can schedule it, them RMS can do it too • define utilization as sum of Ei/Ti • any set of n tasks with utilization of less than n(21/n-1) is schedulable • for n=2,3,…. n(21/n-1) = 0.83, 0.78, … ln(2)=0.69 EE249
Static Priority Schedule Validation Audsley [91]: • for a task in Liu-Layland’s model find its worst case execution time k n i i i i i time WCET i run time i period i period i EE249
Audsley’s algorithm • let Ei’s be run-times, Ti’s periods • how much can i be delayed by a higher priority task k: • each execution delays it by Ek • while i is executing k will be executed ciel(WCETi/ Tk) • WCETi = Ei + SUMk>i ciel(WCETi/ Tk)* Ek EE249
Solving implicit equation • iteration • WCETi,0 = Ei • WCETi,n+1 = Ei + SUMk>i ciel(WCETi,n/ Tk)* Ek will converge if processor utilization if less than 1 EE249
Dynamic priority • Earliest deadline first: • at each moment schedule a task with the least time before next occurrence • LL have shown that for their model, EDF schedules any feasible set of tasks EE249
What’s wrong with LL model? • Liu-Layland model yields strong results but does not model reactivity well • Our model: • models reactivity directly • abstracts functionality • allows efficient conservative schedule validation EE249
Computation Model • System is a network of internal and external tasks • External tasks have minimum times between execution • Internal tasks have priorities and run times 20 1,2 5,2 3,2 10 2,1 4,1 EE249
Computation Model 20 1,2 5,2 3,2 10 2,1 4,1 • External task execute at random, respecting the lower bound between executions • Execution of a task enables all its successors • Correct if no events are lost EE249
Schedule Validation • To check correctness: • check whether internal events can be lost • priority analysis • check whether external events can be lost • bound WCET EE249
More general: if fan-ins of i form a tree such that leaves have lower priority than non-leaves and k, then (i,k) cannot be lost i k Validation for Internal Events • Simple: if priority of i is less than k, then (i,k) cannot be lost i k EE249
Validation for External Events • Compute a bound on the period of time a processor executes task of priority i or higher (i-busy period) > i > i > i i i < i < i time i-busy period • (i-busy period ) > ( WCETi ) EE249
Bounding i-busy Period • i-busy period is bounded by: • initial workload at priority level i or higher caused by execution of some task < i • workload at priority level i or higher caused by execution of external tasks during the i-busy period • can find (by simulation) workload at priority level i or higher caused by execution of a single task • can bound the number of occurrences of external tasks in a given period • need to solve a fix-point equation EE249
System: Network of CFSMs F B=>C C=>F G C=>G F^(G==1) C C=>A CFSM1 CFSM2 C C=>B A B C=>B (A==0)=>B CFSM3 EE249
Implementations • CFSMs can be implemented: • in hardware: HW-CFSMs • in software: SW-CFSMs • by built-in peripherals (e.g. timer): MP-CFSMs EE249
Events: SW to SW • for every event, RTOS maintains • global values • local flags x CFSM2 x emit x( 3 ) detect x CFSM1 CFSM3 x 3 EE249
Events: atomicity problems • TASK 1 detects y AND NOT x, which is never true • to avoid, need atomic detects TASK 1 detect x detect y TASK 2 emit x TASK 3 if detect x then emit y EE249
Events: SW to SW • for atomicity: • always read from frozen • others always write to live • at the beginning of execution, switch CFSM live frozen EE249
Events: HW to SW • event can be polled or driving an interrupt • for polled events: • allocate I/O port bits for value, occurrence and acknowledge flags • generate the polling task that acknowledges and emits all polled events that have occurred • for events driving an interrupt: • allocate I/O port bits for value, • allocate an interrupt vector, • create an interrupt service routine that emits an event EE249
Events: interrupts • interrupt service routine: • optional interrupt service routine: { emit x } { emit x execute SW-CFSM } R T O S X IRQ X HW-CFSM SW-CFSM EE249
Events: SW to HW • allocate I/O port bits for value and occurrence flag • use existing ports or memory-mapped ports • write value to I/O port • create a pulse on occurrence flag EE249
Events: SW to/from MP • every peripheral must have a library with • init function (to be called at initialization time) • deliver function for each input (to be called by emit) • detect function for each output (to be called by poll-taker) • interrupt service routine (containing emit) EE249
Coordination • consider SW-CFSM ready to run whenever it has some not consumed input events • choose the next ready SW-CFSM to run: • scheduling problem EE249
Experiments • dashboard • 6 tasks, 13 events • 0.1s (8.6s to estimate run times) • shock absorber controller • 48 tasks, 11 events • 0.3s (880s to estimate run times) • PATHO RTOS • orders of magnitude faster than timed automata • scales linearly EE249
Open Problems • Propagation of constraints from external I/O behavior to each CFSM • probabilistic: Markov chains • exact: FSM state traversal • Satisfaction of constraints within a single transition (e.g., software-driven bus interface protocol) • Automatic choice of scheduling algorithm, based on performance estimation and constraints • Scheduling for verifiability EE249
Outline • Overview • shop scheduling • data-flow scheduling • real-time scheduling • OS scheduling • Real-time scheduling • RTOS generation • scheduling • Communication • Data-flow scheduling • pure • Petri nets EE249
Data-flow scheduling • Functionality usually represented with a data-flow graph • Kahn’s conditions allow scheduling freedom • if a computation is specified with actors (operators) and data dependency, and • every actor waits for data on all inputs before firing, and • no data is lost • then the firing order doesn’t matter EE249
Data-flow graphs • Schedule: a firing order that respects data-flow constraints and returns the graph to initial state A, 1 B, 2 D, 1 C, 3 EE249
Schedule implementation Static scheduling (cyclic executive, round robin) • A, B, C, D are processes • RTOS schedules them repeatedly in order A D B C • simple, but context-switching overhead large A, 1 B, 2 A schedule: A D B C D, 1 C, 3 EE249
Schedule implementation Code synthesis (OS generation) • A, B, C, D are subroutines • generate: forever{ call A; call D; call B; call C; } • less robust, better overhead A, 1 B, 2 A schedule: A D B C D, 1 C, 3 EE249
Schedule implementation In-lined code synthesis • A, B, C, D are code fragments • generate: forever{A; D; B; C; } • even less robust, even better overhead A, 1 B, 2 A schedule: A D B C D, 1 C, 3 EE249
Data-flow scheduling Resources • fixed or arbitrary number of processors Goal: • max. throughput given a fixed number of processors • min. processors to achieve required throughput EE249
Data-flow scheduling goals Max. throughput given a fixed number of processors • it is NP-hard to determine max. achievable throughput Min. processors to achieve required throughput • if there are loops than there is a fundamental upper bound • easy to compute EE249
Throughput bound 1/maxloops(Time/Delay) A, 1 B, 2 D, 1 C, 3 N+2’nd output of A can be computed at least 7 time units after the Nth EE249