Download
1 / 7
70 likes | 213 Views
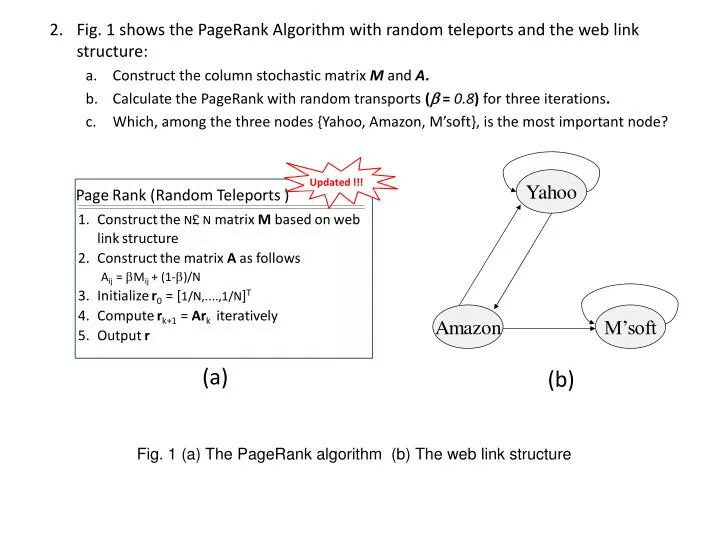
Fig. 1 shows the PageRank Algorithm with random teleports and the web link structure: Construct the column stochastic matrix M and A . Calculate the PageRank with random transports ( = 0.8 ) for three iterations .

E N D
Fig. 1 shows the PageRank Algorithm with random teleports and the web link structure: • Construct the column stochastic matrix M and A. • Calculate the PageRank with random transports ( = 0.8) for three iterations. • Which, among the three nodes {Yahoo, Amazon, M’soft}, is the most important node? (a) (b) Fig. 1 (a) The PageRank algorithm (b) The web link structure
Ans: 1/2 1/2 0 1/2 0 0 0 1/2 1 M = 7/15 7/15 1/15 7/15 1/15 1/15 1/15 7/15 13/15 1/2 1/2 0 1/2 0 0 0 1/2 1 1/3 1/3 1/3 1/3 1/3 1/3 1/3 1/3 1/3 A = = + 0.2 0.8 rk+1 = Ark r0 r1 r2 r3 y a = m 1 1 1 1.00 0.60 1.40 0.84 0.60 1.56 0.776 0.536 1.688 The most important node
As shown in Fig. 2, document frequency thresholding is an important step toward feature extraction in text mining. • Given the content for document D1 and D2 shown in Fig.3, fill the document-feature matrix. • Given N=10 and =1.5, what are the feature terms extracted from D1 by using inverse document frequency weighting? • Given N=10 and =1.0, what are the feature terms extracted from D2 by using entropy weighting? ps.c)小題之計算複雜度高,介於考試時間有限,故本題型在期末考出現的機率很低。 (c) Fig. 3 Fig. 2 Flowchart for feature extraction in text mining.
Feature Extraction: Weighting Model(3) • Entropy weighting where average entropy of j-th term • gfj::= number of times j-th term occurs in the whole training document collection -1: if word occurs once time in every document 0: if word occurs in only one document
Ans: a) b) wij=Freqij* log(N/DocFreqj) • => feature terms: O, R, S, W c) wij= log2(Freqij+1)* (1-entropy(wi)) • => feature terms: A, B
Fig. 4 • Data Preprocessing is essential for web usage mining. • Explain the four steps data preprocessing • Given the web page linkage shown in Fig 4. (c), refine the user sessions shown in Fig. 4 (a). • Given the web page linkage shown in Fig 4. (c), complete the paths in Fig. 4. (b). Fig. 4
Ans: a) b) • Three Sessions: • A-B-F-O-G-A-D • L-R • A-B-C-J • Four Sessions: • A-B-F-O-G • A-D • L-R • A-B-C-J or c) • Four Sessions: • A-B-F-O-F-B-G • A-D • L-R • A-B-A-C-J